📖 Nội dung bài học
Summary
Video này trình bày cách triển khai RAG (Retrieval-Augmented Generation) hoàn chỉnh qua một ví dụ thực tế. Chúng ta sẽ xây dựng một vector database từ đầu và thực hiện đầy đủ 5 bước của quy trình RAG bằng một tài liệu báo cáo mẫu.
Thiết lập Vector Database
Việc triển khai sử dụng một lớp VectorIndex tùy chỉnh để quản lý việc lưu trữ embeddings và thực hiện tìm kiếm tương đồng. Lớp này cung cấp các chức năng cốt lõi cho các thao tác vector database của chúng ta.
Triển khai RAG 5 Bước
Bước 1: Chia nhỏ văn bản theo Phần
Đầu tiên, chúng ta tải và chia nhỏ tài liệu nguồn bằng phương pháp chia theo phần tương tự như trước:
with open("./report.md", "r") as f:
text = f.read()
chunks = chunk_by_section(text)
Thao tác này chia báo cáo của chúng ta thành các phần logic để xử lý độc lập.
Bước 2: Tạo Embeddings cho từng Chunk
Tiếp theo, chúng ta tạo embeddings cho mỗi chunk bằng list comprehension:
embeddings = [generate_embedding(chunk) for chunk in chunks]
Bước này bao gồm nhiều lệnh gọi API, nên sẽ mất một chút thời gian. Mỗi chunk được chuyển đổi thành một biểu diễn vector số học.
Bước 3: Lưu Embeddings vào Vector Database
Bây giờ, chúng ta tạo vector store và điền dữ liệu bao gồm cả embeddings và văn bản tương ứng:
store = VectorIndex()
for embedding, chunk in zip(embeddings, chunks):
store.add_vector(embedding, {"content": chunk})
Điểm mấu chốt ở đây là chúng ta lưu cả embedding và văn bản gốc. Chỉ nhận lại một danh sách các số thì không hữu ích - chúng ta cần nội dung văn bản thực tế tương ứng với các embeddings đó. Dữ liệu metadata này cho phép chúng ta truy xuất kết quả có ý nghĩa sau này.
Bước 4: Tạo Embedding cho Truy vấn Người dùng
Khi người dùng đặt câu hỏi, chúng ta chuyển đổi nó sang cùng định dạng embedding:
user_embedding = generate_embedding("What did the software engineering dept do last year?")
Thao tác này tạo ra một biểu diễn vector cho câu hỏi của người dùng, có thể so sánh với các embeddings đã lưu trữ.
Bước 5: Tìm kiếm và Truy xuất các Chunk Liên quan
Cuối cùng, chúng ta tìm kiếm trong vector store để tìm nội dung tương đồng nhất:
results = store.search(user_embedding, 2)
for doc, distance in results:
print(distance, "\n", doc["content"][0:200], "\n")
Thao tác này trả về hai chunk liên quan nhất cùng với điểm cosine distance của chúng. Khoảng cách nhỏ hơn cho thấy độ tương đồng cao hơn.
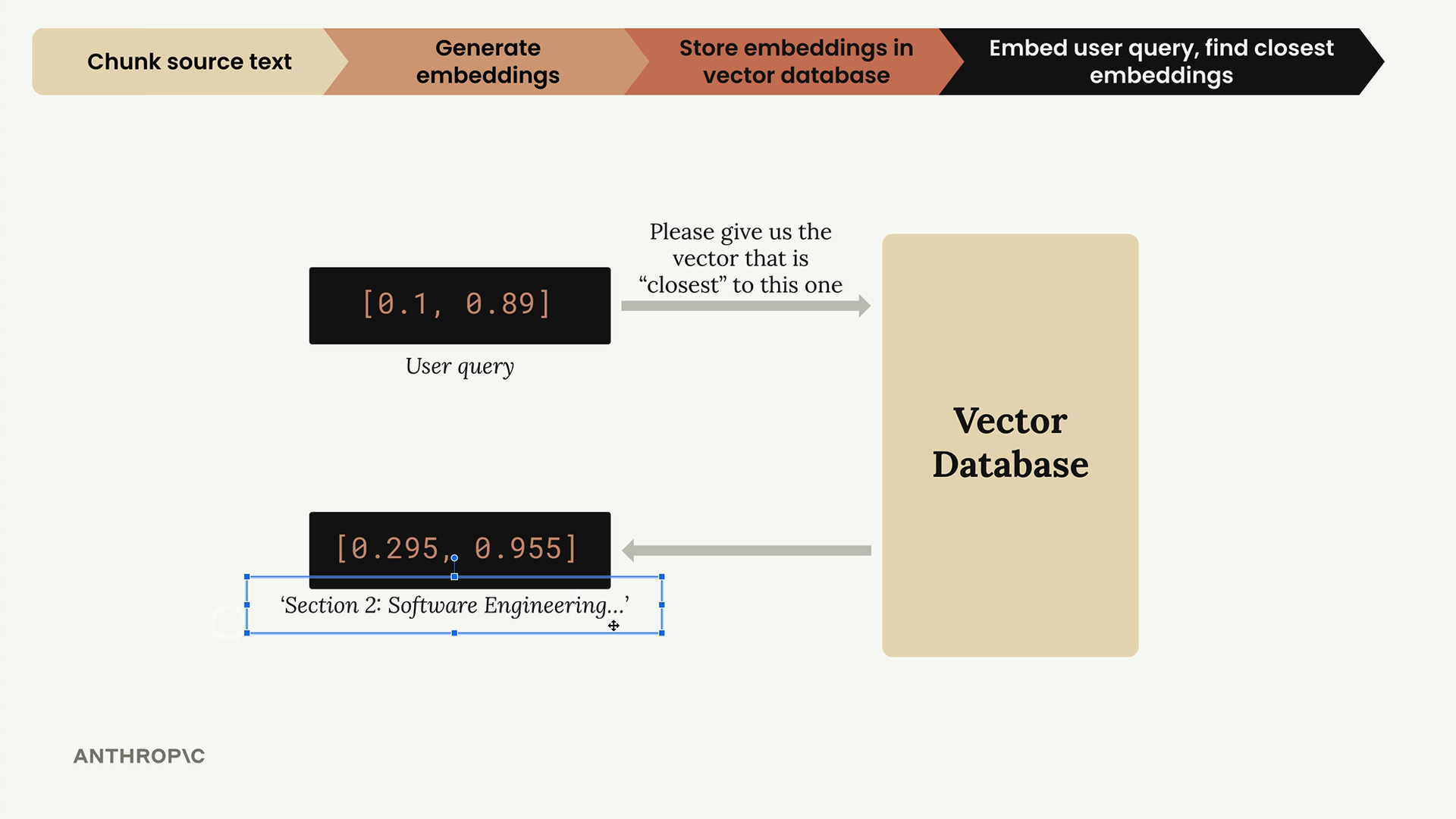
Hiểu kết quả
Kết quả tìm kiếm được xếp hạng theo mức độ liên quan. Trong ví dụ của chúng ta, phần kỹ thuật phần mềm có khoảng cách nhỏ nhất (0.71), trở thành kết quả phù hợp nhất. Phần phương pháp luận đứng thứ hai với khoảng cách 0.72.
Chỉ số khoảng cách giúp bạn hiểu mức độ tin cậy của hệ thống về mức độ liên quan của mỗi kết quả. Khoảng cách càng gần thì kết quả khớp càng tốt với truy vấn của người dùng.
Tại sao lưu Văn bản cùng với Embeddings
Một quyết định thiết kế quan trọng là lưu văn bản gốc cùng với mỗi embedding. Nếu không có bước này, bạn chỉ nhận lại các mảng số, không hữu ích cho việc tạo phản hồi. Bằng cách bao gồm văn bản nguồn, bạn có thể sử dụng ngay các chunk đã truy xuất để cung cấp ngữ cảnh cho mô hình ngôn ngữ của mình.
Như vậy là đã hoàn thành quy trình RAG cốt lõi, mặc dù có những tối ưu hóa và cải tiến bổ sung có thể nâng cao hiệu suất trong các tình huống thực tế.
Downloads
🔁 Bài học liên quan
- Bài tiếp: BM25 lexical search
- Bài trước: The full RAG flow
- Cùng section: Overview of Claude Models · Accessing the API · Making a request
- Thuộc lộ trình: Path C
- Docs tham khảo: Glossary · Skills atlas · By use-case
📚 Nguồn & ghi nhận
- Bài học gốc Anthropic Academy: https://anthropic.skilljar.com/claude-in-amazon-bedrock/276781
- © 2025 Anthropic. Chỉ dùng cho mục đích giáo dục, fair-use.
- Crawl: — · Chuẩn hoá: 2026-05-01