📖 Nội dung bài học
Giảm cỡ phụ đề-
Tăng cỡ phụ đề+ hoặc = Cỡ chữ
Tóm tắt
Khi xây dựng một RAG pipeline, bạn sẽ nhanh chóng nhận ra rằng semantic search (tìm kiếm ngữ nghĩa) một mình không phải lúc nào cũng cho kết quả tốt nhất. Đôi khi bạn cần các từ khóa khớp chính xác mà semantic search có thể bỏ lỡ. Giải pháp là kết hợp semantic search với lexical search (tìm kiếm từ vựng) bằng kỹ thuật BM25.
Vấn đề khi chỉ dùng Semantic Search
Giả sử bạn đang tìm kiếm một ID sự cố cụ thể như "INC-2023-Q4-011" trong một tài liệu. Mặc dù thuật ngữ chính xác này xuất hiện nhiều lần trong các phần liên quan, semantic search có thể trả về các phần không liên quan, trông có vẻ tương tự về mặt ngữ nghĩa nhưng thực tế lại không chứa thông tin cụ thể bạn cần.

Điều này xảy ra vì semantic search tập trung vào ý nghĩa hơn là các từ khóa khớp chính xác. Khi bạn cần khớp từ khóa một cách chính xác, bạn cần một phương pháp khác.
Chiến lược tìm kiếm kết hợp
Giải pháp là chạy cả semantic search và lexical search song song, sau đó hợp nhất các kết quả. Điều này mang lại cho bạn những lợi ích tốt nhất từ cả hai phương pháp:
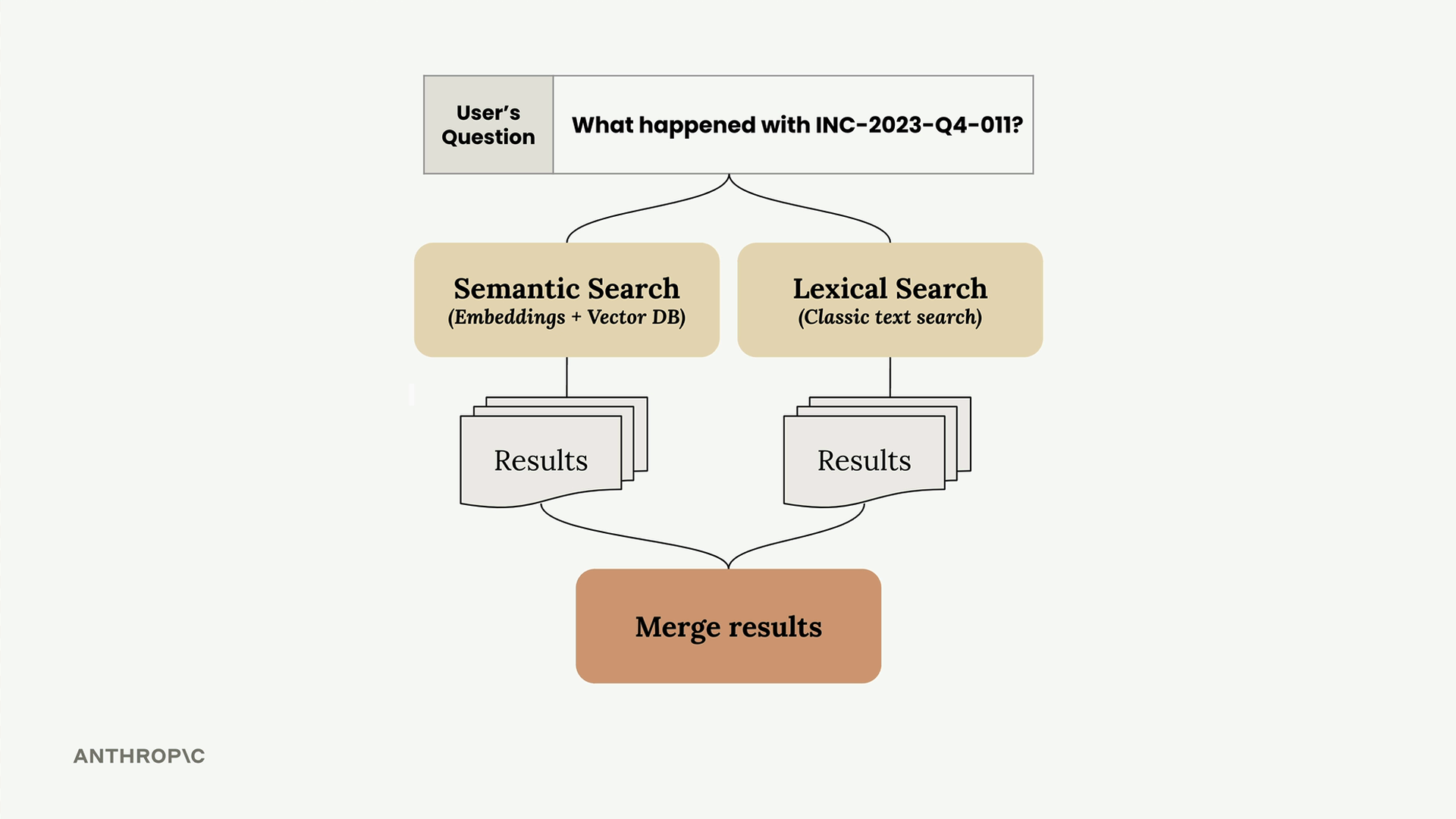
- Semantic search - Tìm nội dung liên quan về mặt khái niệm bằng cách dùng embeddings
- Lexical search - Tìm các từ khóa khớp chính xác bằng cách dùng tìm kiếm văn bản truyền thống
- Kết quả hợp nhất - Kết hợp cả hai phương pháp để có độ liên quan tổng thể tốt hơn
BM25 hoạt động như thế nào
BM25 (Best Match 25) là một thuật toán phổ biến cho lexical search trong các RAG pipeline. Đây là cách nó xử lý một truy vấn tìm kiếm:
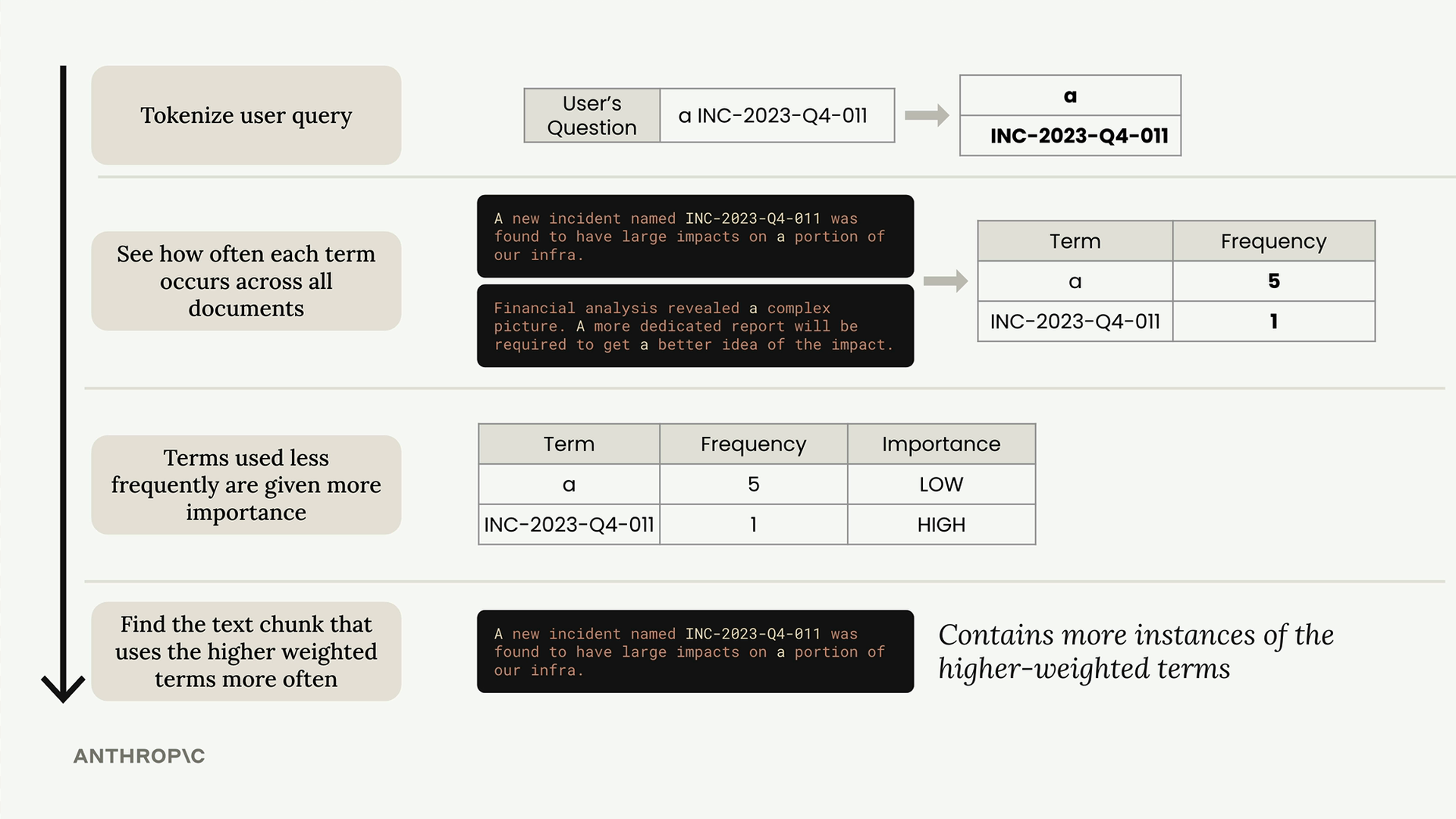
Thuật toán tuân theo các bước chính sau:
- Tokenize truy vấn - Chia câu hỏi của người dùng thành các token riêng lẻ
- Đếm tần suất thuật ngữ - Xem mỗi thuật ngữ xuất hiện bao nhiêu lần trên tất cả các tài liệu
- Gán trọng số cho thuật ngữ theo độ hiếm - Các thuật ngữ ít được dùng hơn sẽ nhận được điểm quan trọng cao hơn
- Chấm điểm tài liệu - Tìm các đoạn văn bản chứa nhiều trường hợp của các thuật ngữ có trọng số cao hơn
Điểm mấu chốt là các thuật ngữ hiếm như "INC-2023-Q4-011" quan trọng hơn nhiều đối với độ liên quan của tìm kiếm so với các từ thông thường như "a" hoặc "the".
Triển khai tìm kiếm BM25
Đây là cách thiết lập một hệ thống tìm kiếm BM25:
store = BM25Index()
for chunk in chunks:
store.add_document({"content": chunk})
results = store.search("What happened with INC-2023-Q4-011?", 3)
Việc triển khai BM25 duy trì một API tương tự như vector store của bạn, với các phương thức add_document() và search(). Sự nhất quán này giúp bạn dễ dàng dùng cả hai hệ thống cùng nhau.
Kết quả tìm kiếm tốt hơn
Khi bạn chạy cùng một truy vấn qua BM25 mà trước đó đã thất bại với semantic search một mình, bạn sẽ nhận được kết quả tốt hơn nhiều. Thuật toán ưu tiên chính xác các phần chứa ID sự cố chính xác, xếp hạng chúng cao hơn các phần có thể liên quan về mặt ngữ nghĩa nhưng không chứa thuật ngữ cụ thể bạn đang tìm kiếm.
Kết quả tìm kiếm giờ đây hiển thị chính xác các phần Kỹ thuật Phần mềm và An ninh mạng thực sự thảo luận về sự cố, thay vì trả về nội dung không liên quan như Phân tích Tài chính.
Các bước tiếp theo
Giờ đây bạn đã có cả hệ thống semantic search và lexical search hoạt động độc lập, bước tiếp theo là hợp nhất kết quả của chúng. Phương pháp kết hợp này sẽ mang lại cho bạn khả năng hiểu ngữ nghĩa của embeddings kết hợp với độ chính xác của việc khớp từ khóa, tạo ra trải nghiệm tìm kiếm mạnh mẽ hơn cho RAG pipeline của bạn.
Tải xuống
🔁 Bài học liên quan
- Bài tiếp: A multi-search RAG pipeline
- Bài trước: Implementing the RAG flow
- Cùng section: Overview of Claude Models · Accessing the API · Making a request
- Thuộc lộ trình: Path C
- Docs tham khảo: Glossary · Skills atlas · By use-case
📚 Nguồn & ghi nhận
- Bài học gốc Anthropic Academy: https://anthropic.skilljar.com/claude-in-amazon-bedrock/276776
- © 2025 Anthropic. Chỉ dùng cho mục đích giáo dục, fair-use.
- Crawl: 2026-04-23 · Chuẩn hoá: 2026-05-01