📖 Nội dung bài học
Tăng Âm lượng↑
Giảm Âm lượng↓
Tua Tới→
Tua Lùi←
Phụ đề Bật/Tắtc
Toàn màn hình/Thoát Toàn màn hìnhf
Tắt tiếng/Bật tiếngm
Giảm Kích thước Phụ đề-
Tăng Kích thước Phụ đề+ hoặc =
Tua %0-9
Cài đặt Phụ đề Màu Phông chữ
Trắng
Độ trong suốt Phông chữ
100%
Kích thước Phông chữ
100%
Kiểu Phông chữ
Tóm tắt
Bây giờ chúng ta đã tìm hiểu các khái niệm cơ bản về RAG, phân đoạn văn bản và embeddings, hãy cùng xem xét quy trình RAG hoàn chỉnh từng bước. Ví dụ chi tiết này sẽ cho bạn thấy chính xác cách tất cả các phần kết hợp với nhau trong một triển khai thực tế.
Bước 1: Phân đoạn văn bản nguồn
Đầu tiên, chúng ta lấy tài liệu nguồn và chia nó thành các đoạn nhỏ dễ quản lý. Đối với ví dụ này, chúng ta sẽ sử dụng hai phần văn bản đơn giản:
- Phần 1: Nghiên cứu Y khoa - "Năm nay đã chứng kiến những bước tiến đáng kể trong hiểu biết của chúng ta về XDR-47, một 'lỗi' mà chúng ta chưa từng thấy trước đây."
- Phần 2: Kỹ thuật Phần mềm - "Bộ phận này đã dành nỗ lực đáng kể để nghiên cứu các vector lây nhiễm khác nhau trong các hệ thống phân tán của chúng ta."
Bước 2: Tạo Embeddings
Tiếp theo, chúng ta chuyển đổi từng đoạn văn bản thành các embeddings dạng số. Để làm rõ khái niệm này, hãy tưởng tượng chúng ta có một mô hình embedding hoàn hảo luôn trả về chính xác hai số và chúng ta biết mỗi số đại diện cho điều gì:
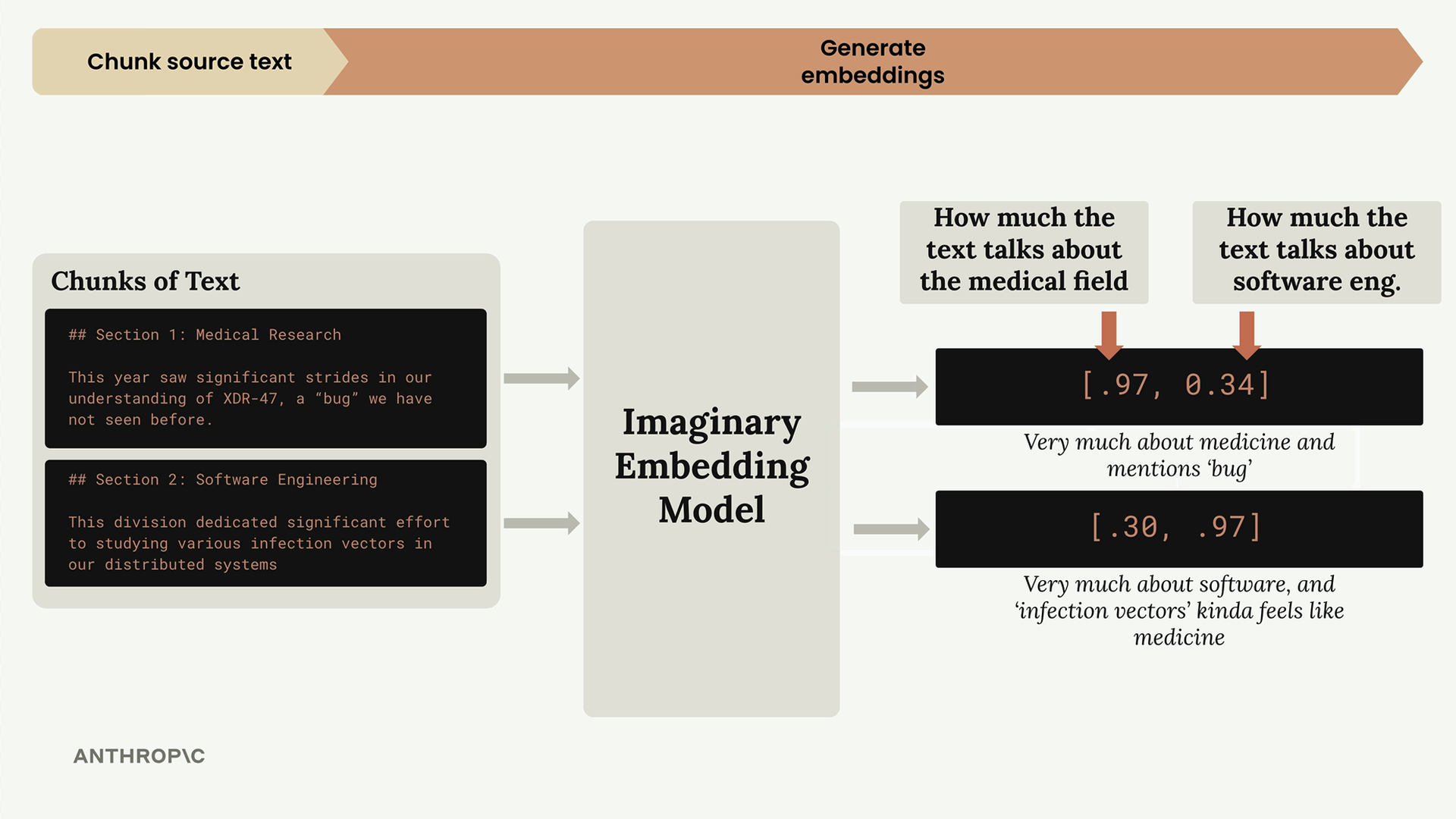
Trong mô hình tưởng tượng của chúng ta:
- Số thứ nhất: Văn bản nói về lĩnh vực y tế bao nhiêu
- Số thứ hai: Văn bản nói về kỹ thuật phần mềm bao nhiêu
Vì vậy, phần nghiên cứu y khoa của chúng ta nhận được embedding là [0.97, 0.34] - rất y khoa, có phần liên quan đến phần mềm do từ "bug". Phần kỹ thuật phần mềm nhận được [0.30, 0.97] - tập trung mạnh vào phần mềm, nhưng "infection vectors" (vector lây nhiễm) có ý nghĩa y khoa.
Chuẩn hóa (Normalization)
Trước khi lưu trữ các embeddings này, chúng sẽ trải qua quá trình chuẩn hóa để điều chỉnh mỗi vector có độ lớn bằng 1.0. Điều này thường được xử lý tự động bởi API embedding của bạn, nhưng điều quan trọng là phải hiểu rằng nó xảy ra.
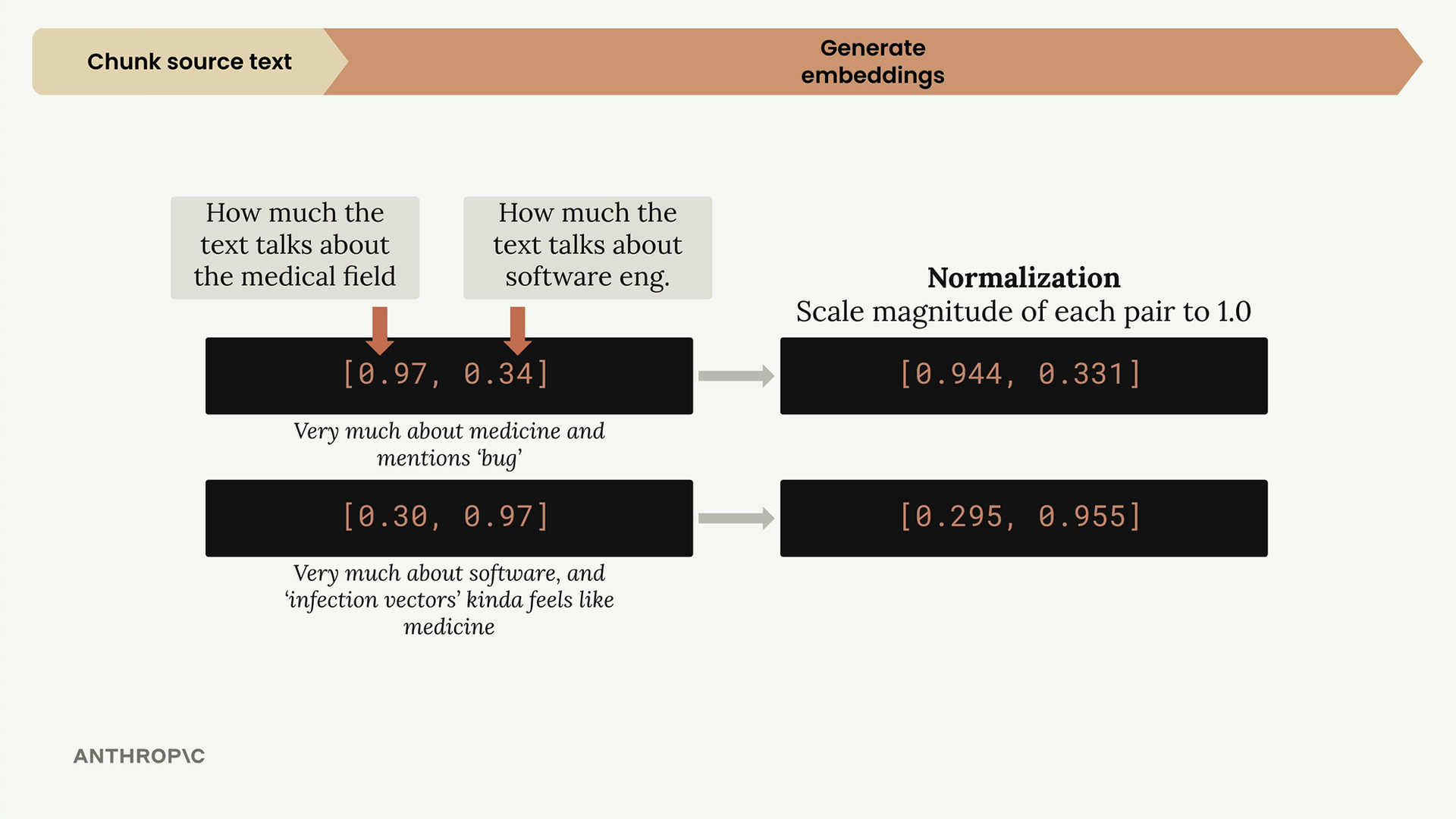
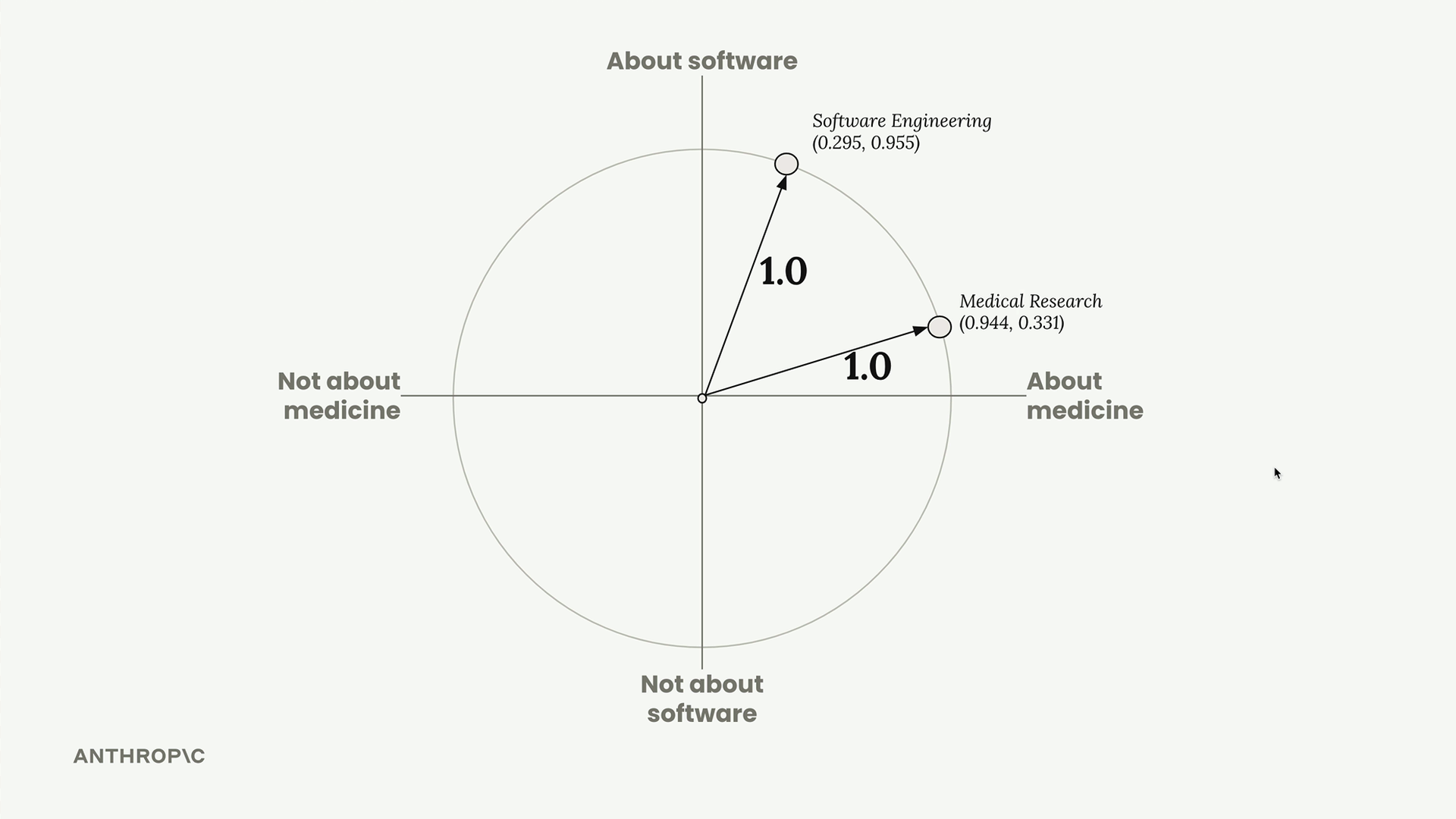
Sau khi chuẩn hóa, các embeddings của chúng ta trở thành [0.944, 0.331] và [0.295, 0.955]. Chúng ta có thể hình dung chúng trên một đường tròn đơn vị, nơi mỗi điểm nằm chính xác trên cạnh của đường tròn.
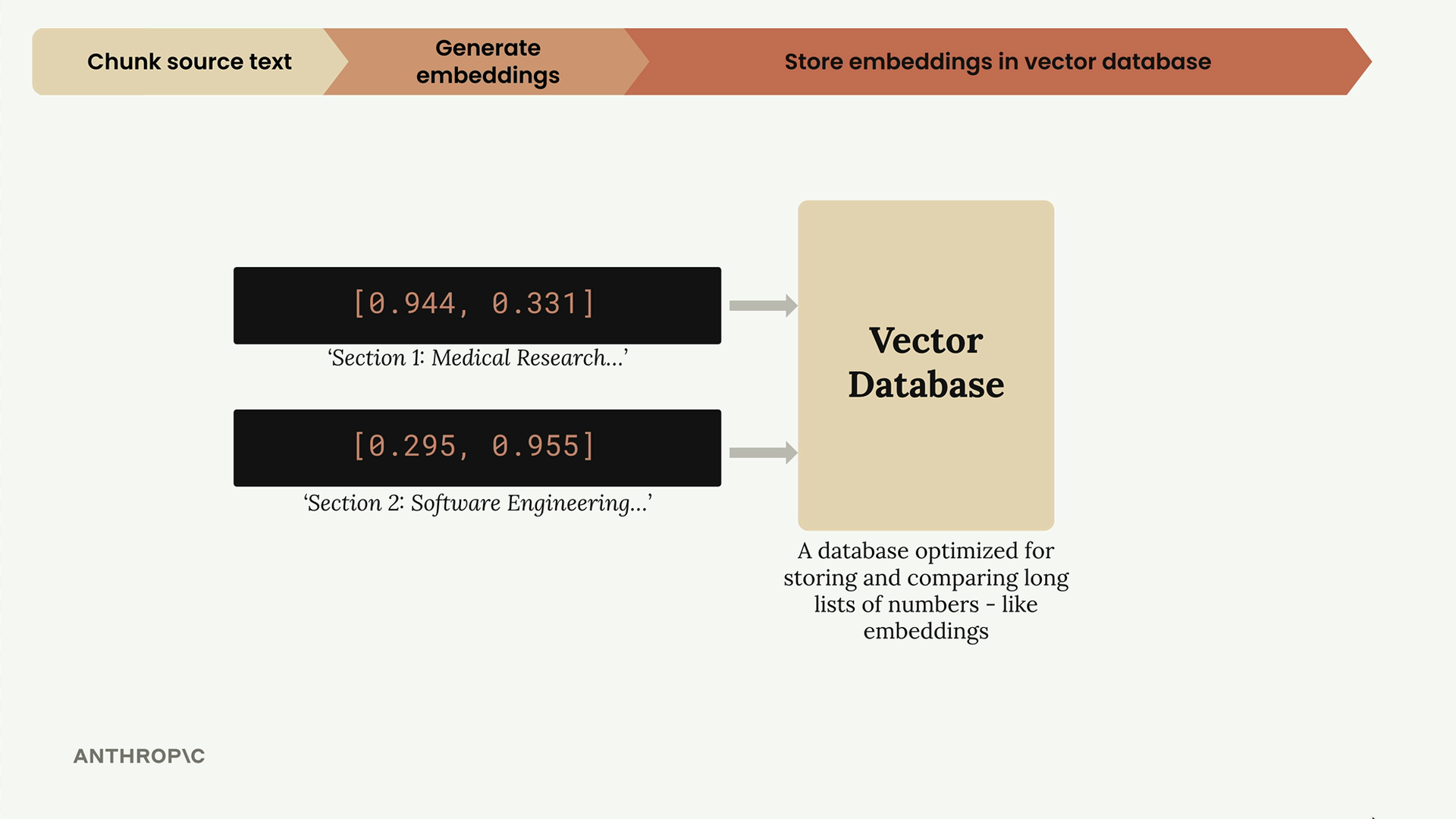
Bước 3: Lưu trữ trong Cơ sở dữ liệu Vector
Các embeddings đã chuẩn hóa được lưu trữ trong cơ sở dữ liệu vector - một cơ sở dữ liệu chuyên dụng được tối ưu hóa để lưu trữ, so sánh và tìm kiếm qua các danh sách số dài như embeddings của chúng ta.
Tại thời điểm này, chúng ta tạm dừng. Tất cả công việc cho đến nay là tiền xử lý xảy ra trước. Bây giờ chúng ta chờ người dùng gửi một truy vấn.
Bước 4: Xử lý Truy vấn Người dùng
Khi người dùng đặt câu hỏi như "Tôi tò mò về công ty. Đặc biệt, bộ phận kỹ thuật phần mềm đã làm gì trong năm nay?", chúng ta chạy truy vấn của họ qua cùng một mô hình embedding.
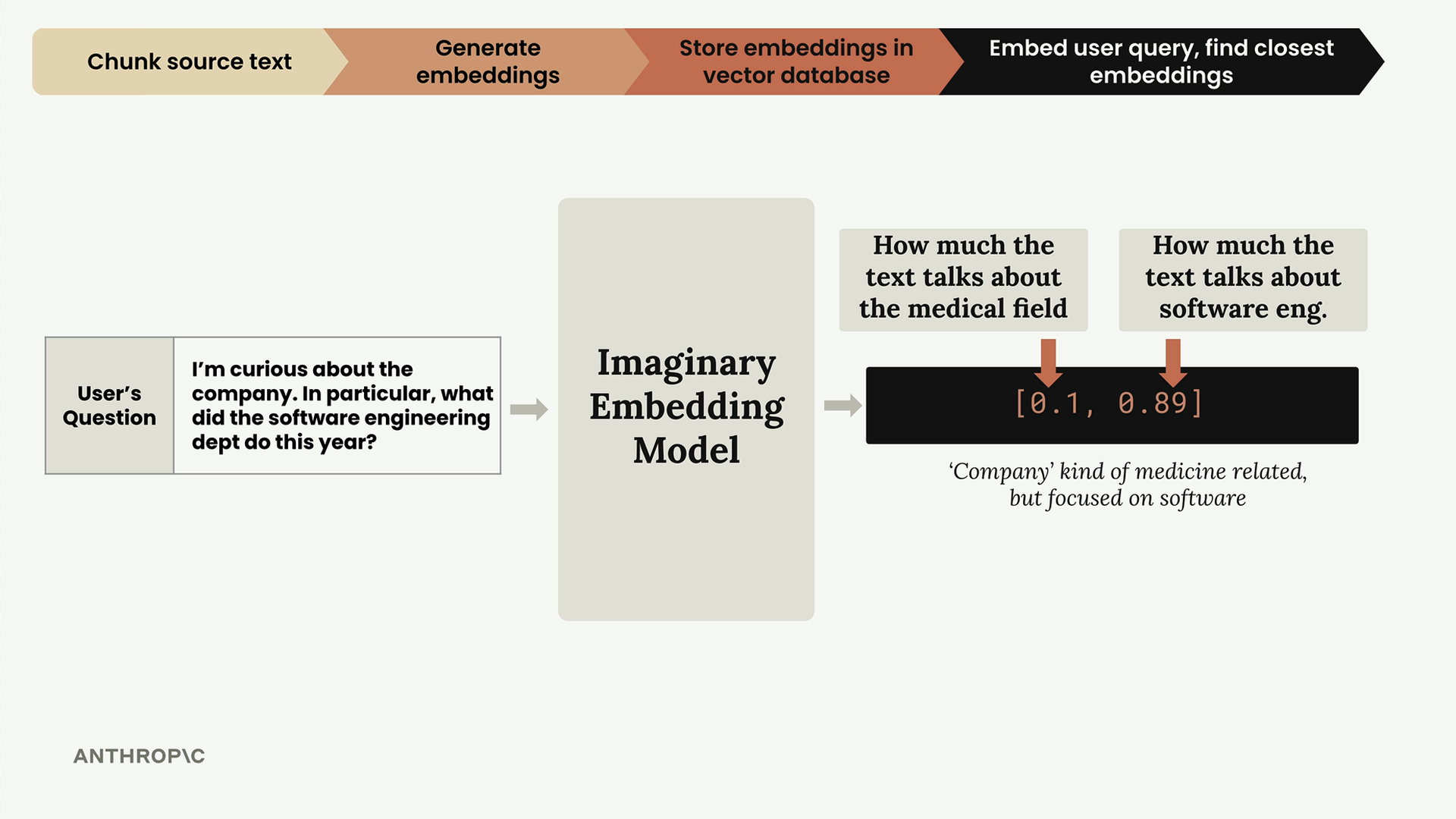
Truy vấn này được nhúng thành [0.1, 0.89] - điểm y tế thấp, điểm kỹ thuật phần mềm cao. Sau khi chuẩn hóa, nó trở thành [0.112, 0.993].
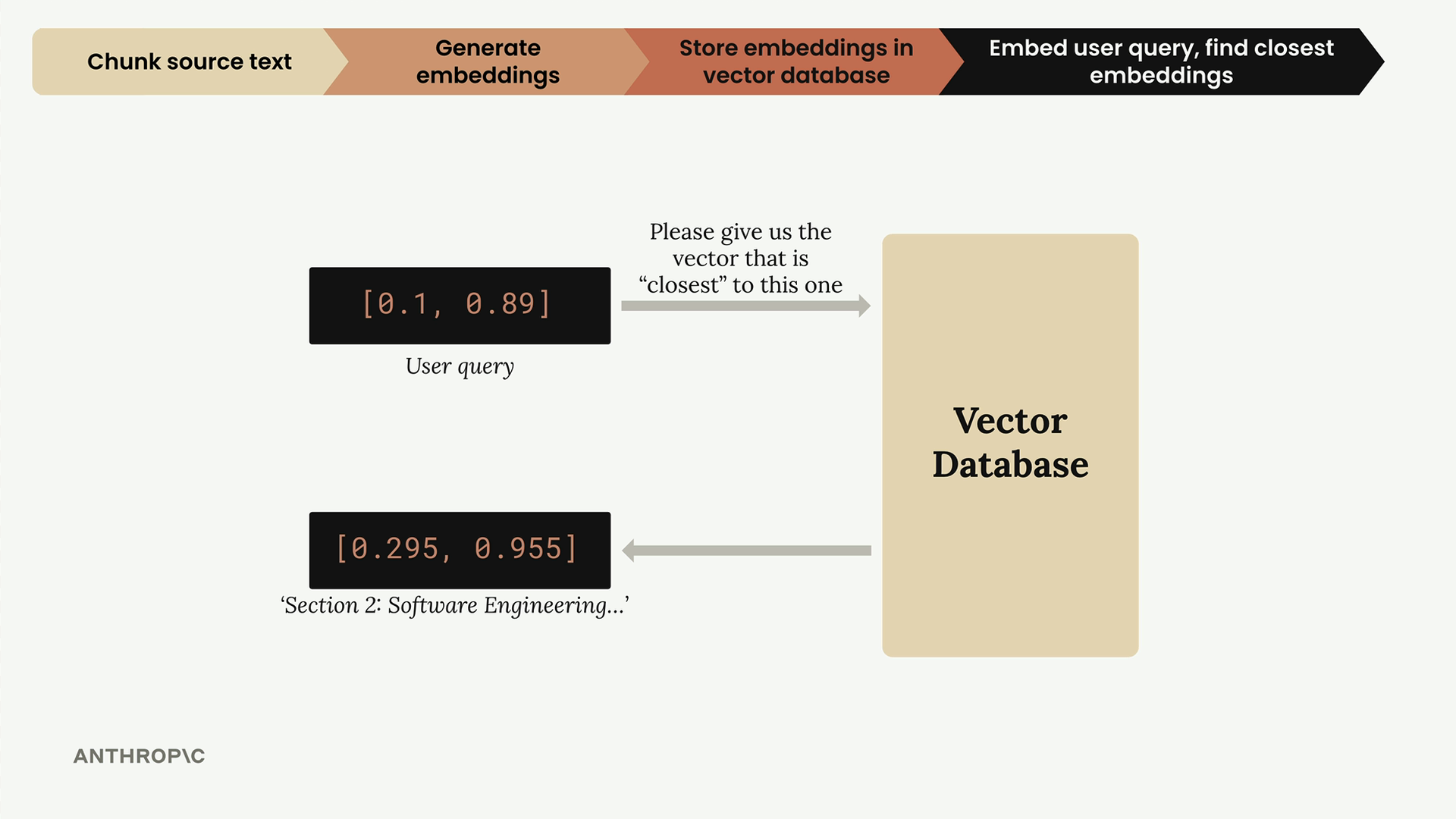
Bước 5: Tìm Embeddings Tương tự
Bây giờ chúng ta hỏi cơ sở dữ liệu vector: "Tìm embedding đã lưu trữ gần nhất với embedding truy vấn của người dùng này." Cơ sở dữ liệu trả về phần kỹ thuật phần mềm vì nó là phần tương tự nhất.
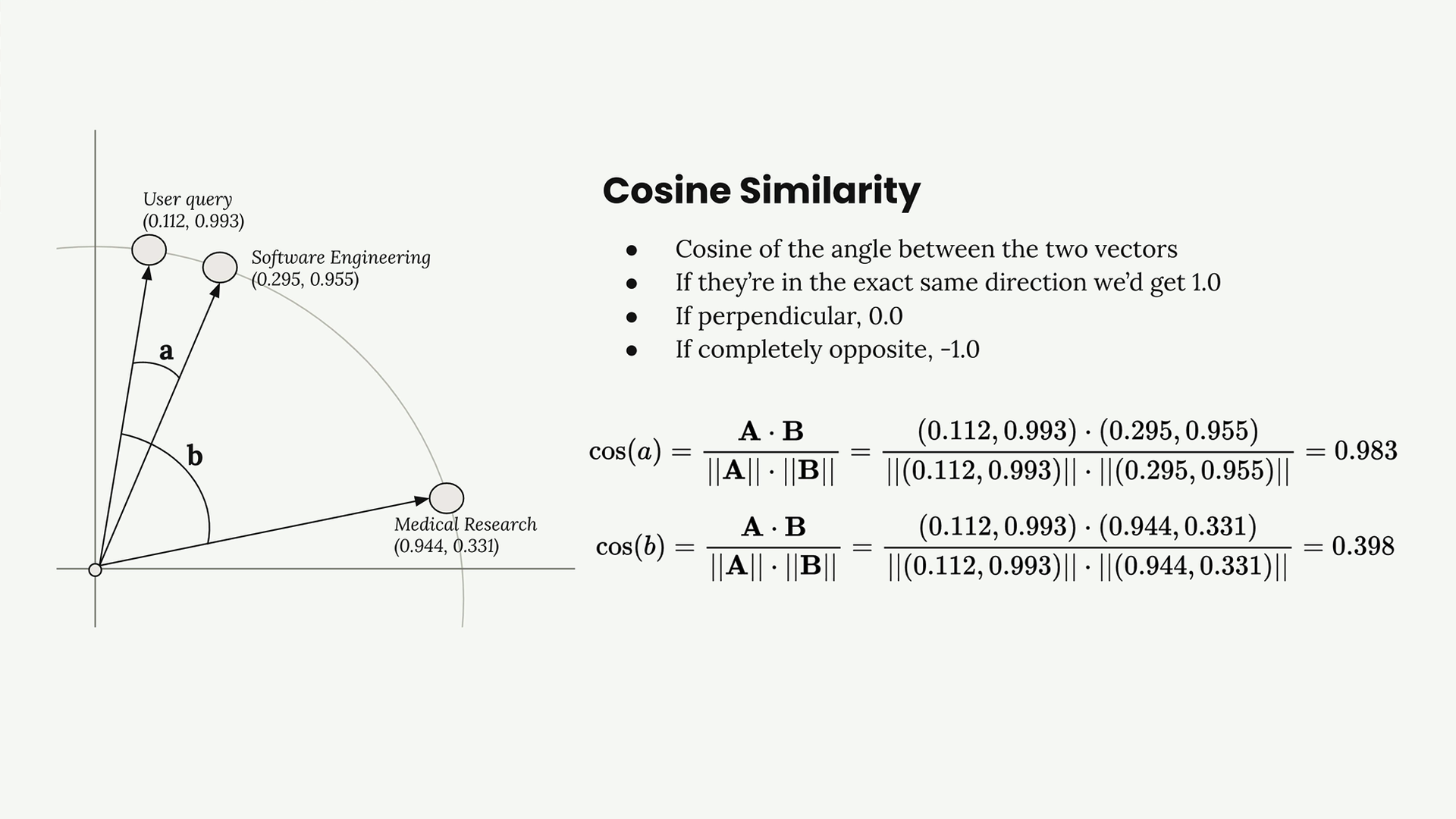
Cách hoạt động của Sự tương tự: Cosine Similarity
Cơ sở dữ liệu vector sử dụng cosine similarity để xác định các embeddings nào tương tự nhất. Nó đo lường cosine của góc giữa hai vector.
Các điểm chính về cosine similarity:
- Kết quả dao động từ -1 đến 1
- Các giá trị gần 1 có nghĩa là rất tương tự
- Các giá trị gần 0 có nghĩa là vuông góc (không liên quan)
- Các giá trị gần -1 có nghĩa là hoàn toàn đối lập
Phép tính sử dụng công thức dot product: cos(a) = (A · B) / (||A|| · ||B||)
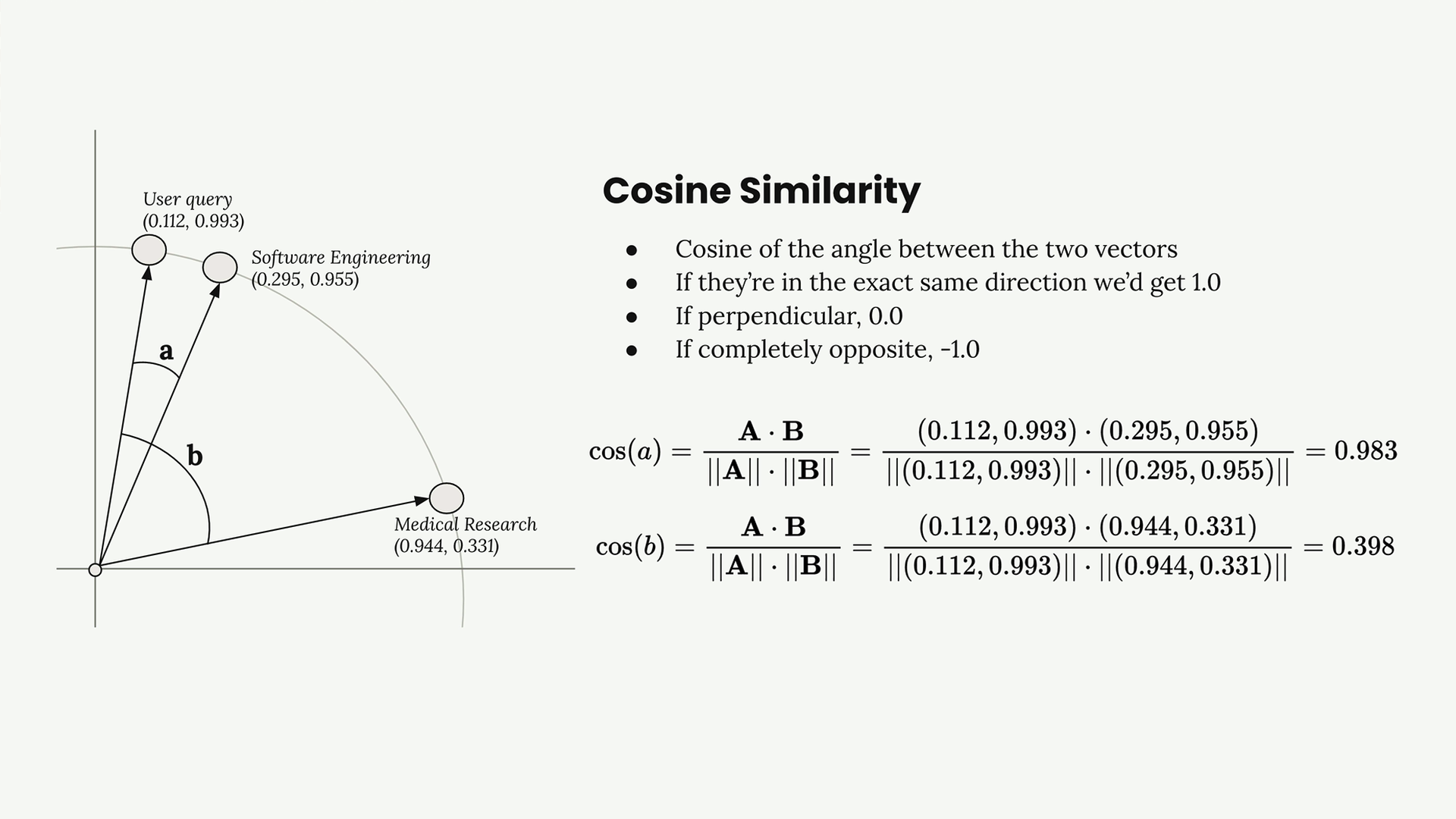
Trong ví dụ của chúng ta, truy vấn của người dùng có cosine similarity là 0.983 với đoạn mã kỹ thuật phần mềm và chỉ 0.398 với đoạn nghiên cứu y khoa. Đoạn mã kỹ thuật phần mềm rõ ràng là phù hợp hơn.
Khoảng cách Cosine (Cosine Distance)
Bạn sẽ thường thấy "cosine distance" trong tài liệu cơ sở dữ liệu vector. Đây chỉ đơn giản là 1 - cosine similarity, cho chúng ta một con số dễ hiểu hơn, trong đó:
- Các giá trị gần 0 có nghĩa là độ tương tự cao
- Các giá trị lớn hơn có nghĩa là độ tương tự thấp hơn
Bước 6: Xây dựng Prompt Cuối cùng
Cuối cùng, chúng ta lấy câu hỏi của người dùng và đoạn văn bản liên quan nhất mà chúng ta tìm thấy, sau đó kết hợp chúng thành một prompt cho Claude:
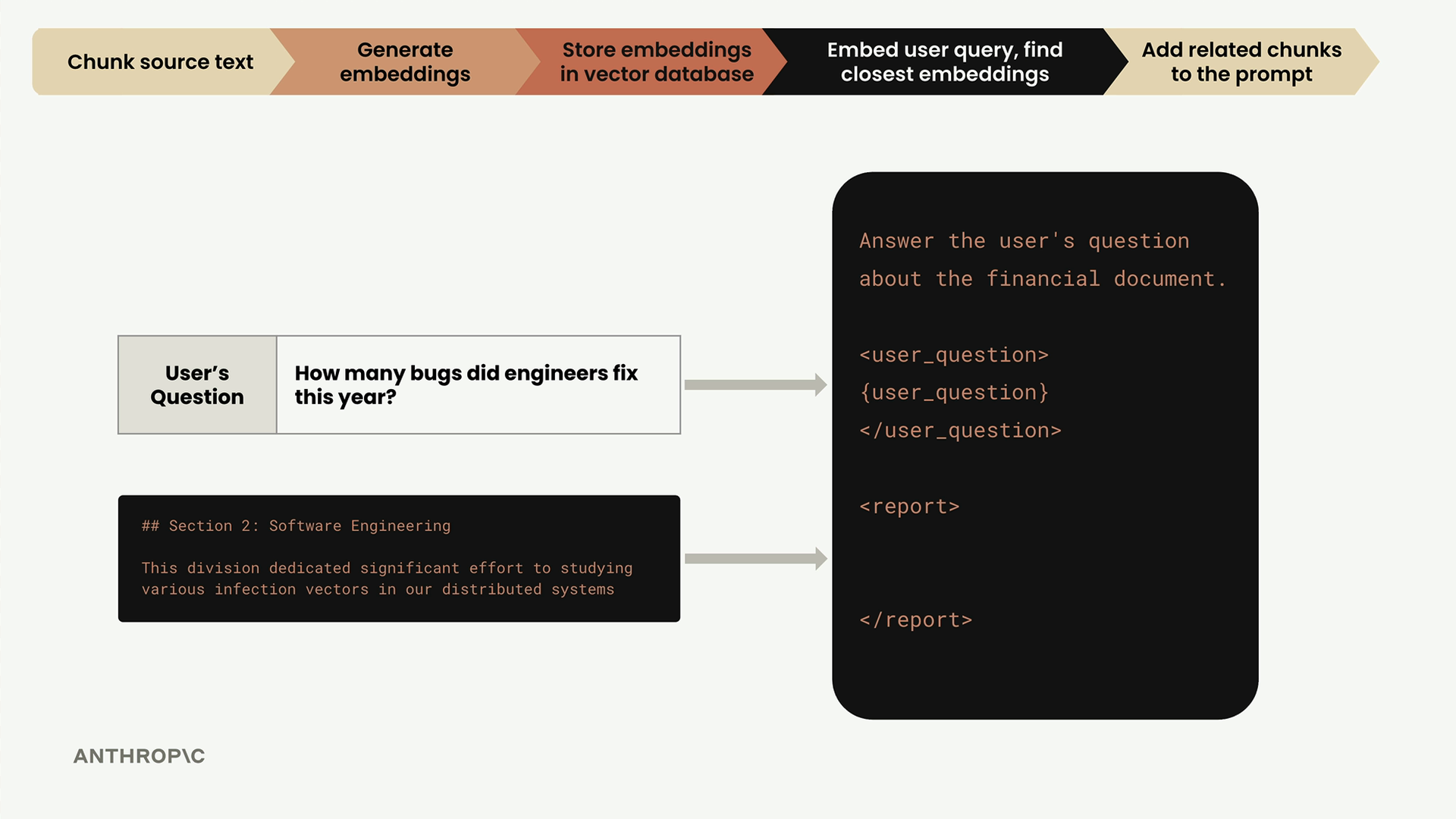
Prompt bao gồm cả câu hỏi của người dùng và ngữ cảnh liên quan từ cơ sở kiến thức của chúng ta, cho phép Claude cung cấp câu trả lời đầy đủ thông tin dựa trên thông tin cụ thể trong cơ sở kiến thức của chúng ta.
Luồng Hoàn chỉnh
Đó là toàn bộ quy trình RAG từ đầu đến cuối:
- Phân đoạn tài liệu nguồn
- Tạo embeddings cho mỗi đoạn
- Lưu trữ embeddings trong cơ sở dữ liệu vector
- Khi người dùng đặt câu hỏi, nhúng truy vấn của họ
- Tìm các embeddings đã lưu trữ tương tự nhất bằng cosine similarity
- Thêm các đoạn liên quan vào prompt cùng với câu hỏi của người dùng
- Gửi prompt đã nâng cao tới Claude để nhận phản hồi
Hiểu quy trình này và toán học đằng sau nó sẽ giúp bạn làm việc hiệu quả với cơ sở dữ liệu vector và khắc phục sự cố khi hệ thống RAG của bạn không trả về kết quả như mong đợi.
🔁 Bài học liên quan
- Bài tiếp: Implementing the RAG flow
- Bài trước: Text embeddings
- Cùng section: Overview of Claude Models · Accessing the API · Making a request
- Thuộc lộ trình: Path C
- Docs tham khảo: Glossary · Skills atlas · By use-case
📚 Nguồn & ghi nhận
- Bài học gốc Anthropic Academy: https://anthropic.skilljar.com/claude-in-amazon-bedrock/276774
- © 2025 Anthropic. Chỉ dùng cho mục đích giáo dục, fair-use.
- Crawl: — · Chuẩn hoá: 2026-05-01