📖 Nội dung bài học
Tóm tắt
Text chunking là một trong những bước quan trọng nhất khi xây dựng một RAG (Retrieval Augmented Generation) pipeline. Cách bạn chia nhỏ tài liệu ảnh hưởng trực tiếp đến chất lượng của toàn bộ hệ thống. Một chiến lược chunking kém có thể dẫn đến việc chèn ngữ cảnh không liên quan vào prompt, khiến AI đưa ra câu trả lời hoàn toàn sai.

Hãy xem xét ví dụ này: bạn có một tài liệu với các phần về nghiên cứu y khoa và kỹ thuật phần mềm. Nếu bạn chunking kém, người dùng hỏi "Kỹ sư đã sửa bao nhiêu lỗi trong năm nay?" có thể nhận được thông tin về nghiên cứu y khoa thay vì kỹ thuật phần mềm, đơn giản vì phần y khoa tình cờ chứa từ "lỗi" (bug) trong một ngữ cảnh khác.
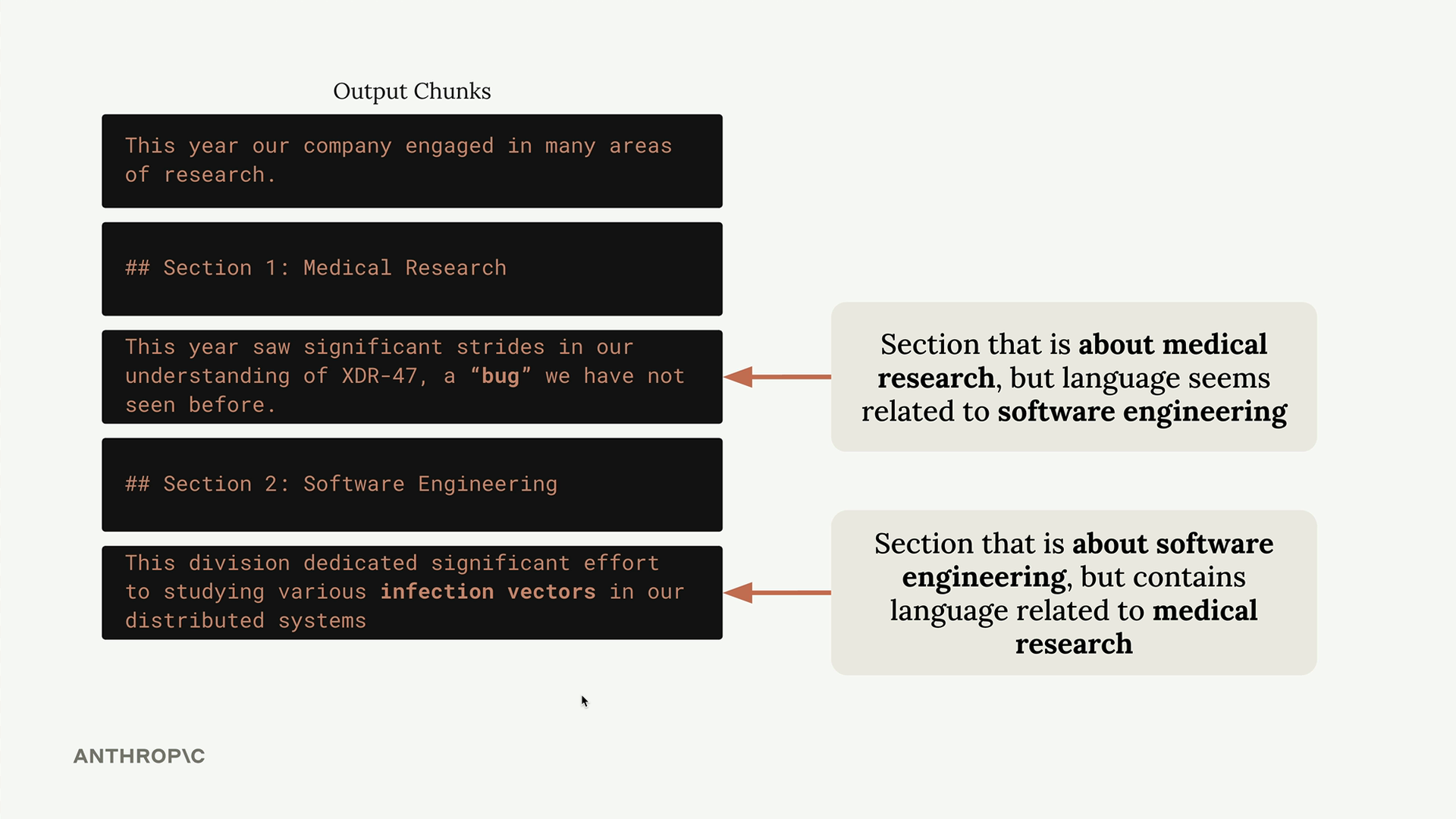
Điều này cho thấy tại sao chiến lược chunking lại quan trọng đến vậy. Mục tiêu là tạo ra các chunk duy trì sự mạch lạc về ngữ nghĩa và cung cấp ngữ cảnh có ý nghĩa khi được truy xuất.

Ba chiến lược Chunking chính
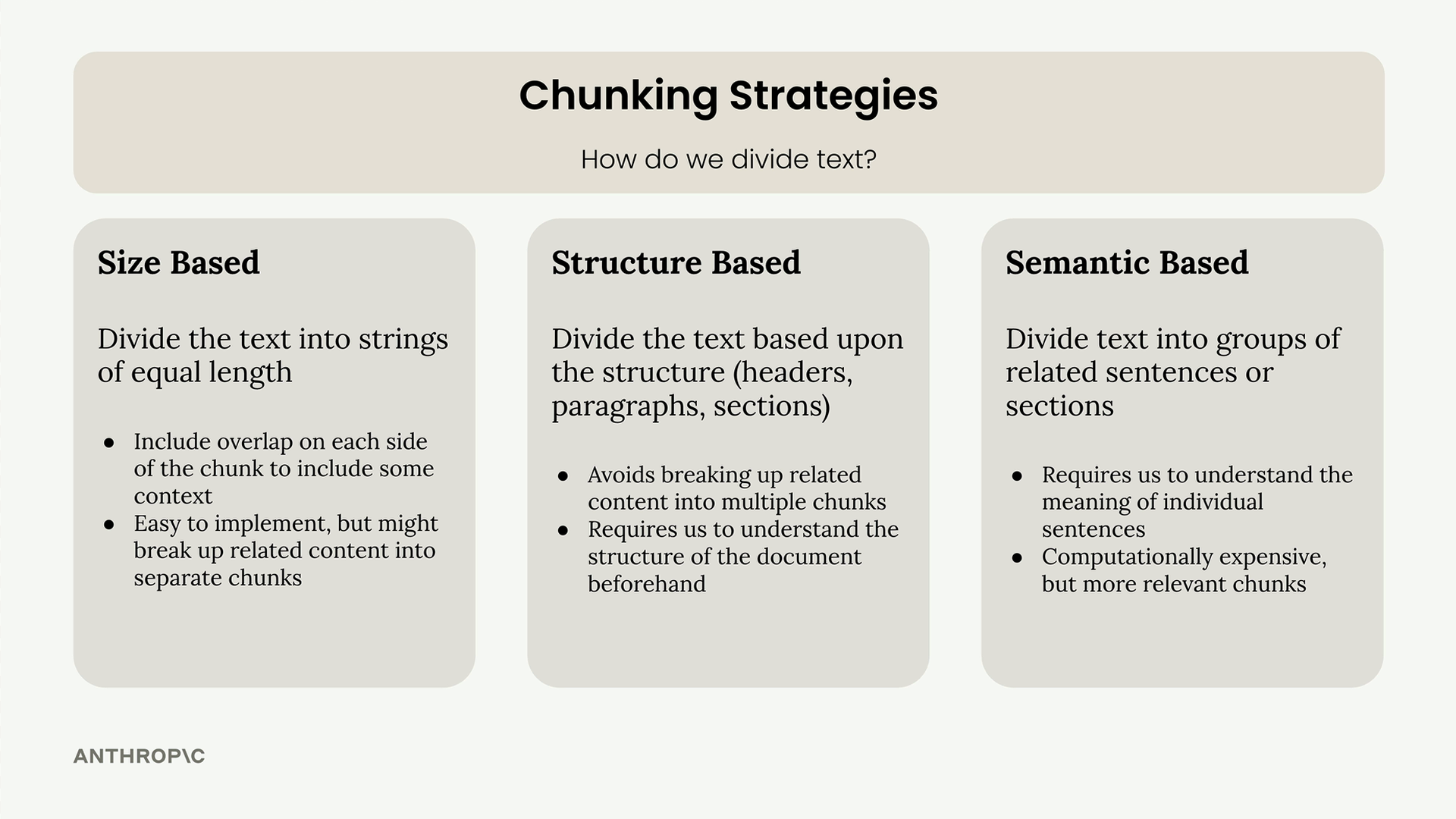
Có ba phương pháp tiếp cận chính để chunking văn bản, mỗi phương pháp có ưu điểm và đánh đổi riêng:
- Dựa trên kích thước (Size-based): Chia văn bản thành các chuỗi có độ dài xấp xỉ bằng nhau.
- Dựa trên cấu trúc (Structure-based): Chia dựa trên cấu trúc tài liệu (tiêu đề, đoạn văn, mục).
- Dựa trên ngữ nghĩa (Semantic-based): Nhóm các câu hoặc phần liên quan bằng các kỹ thuật NLP.
Chunking dựa trên kích thước
Chunking dựa trên kích thước là phương pháp đơn giản nhất. Bạn chỉ cần chia tài liệu thành các chunk có số lượng ký tự hoặc từ xấp xỉ bằng nhau. Cách này dễ triển khai và hoạt động đáng tin cậy trên các loại tài liệu khác nhau.
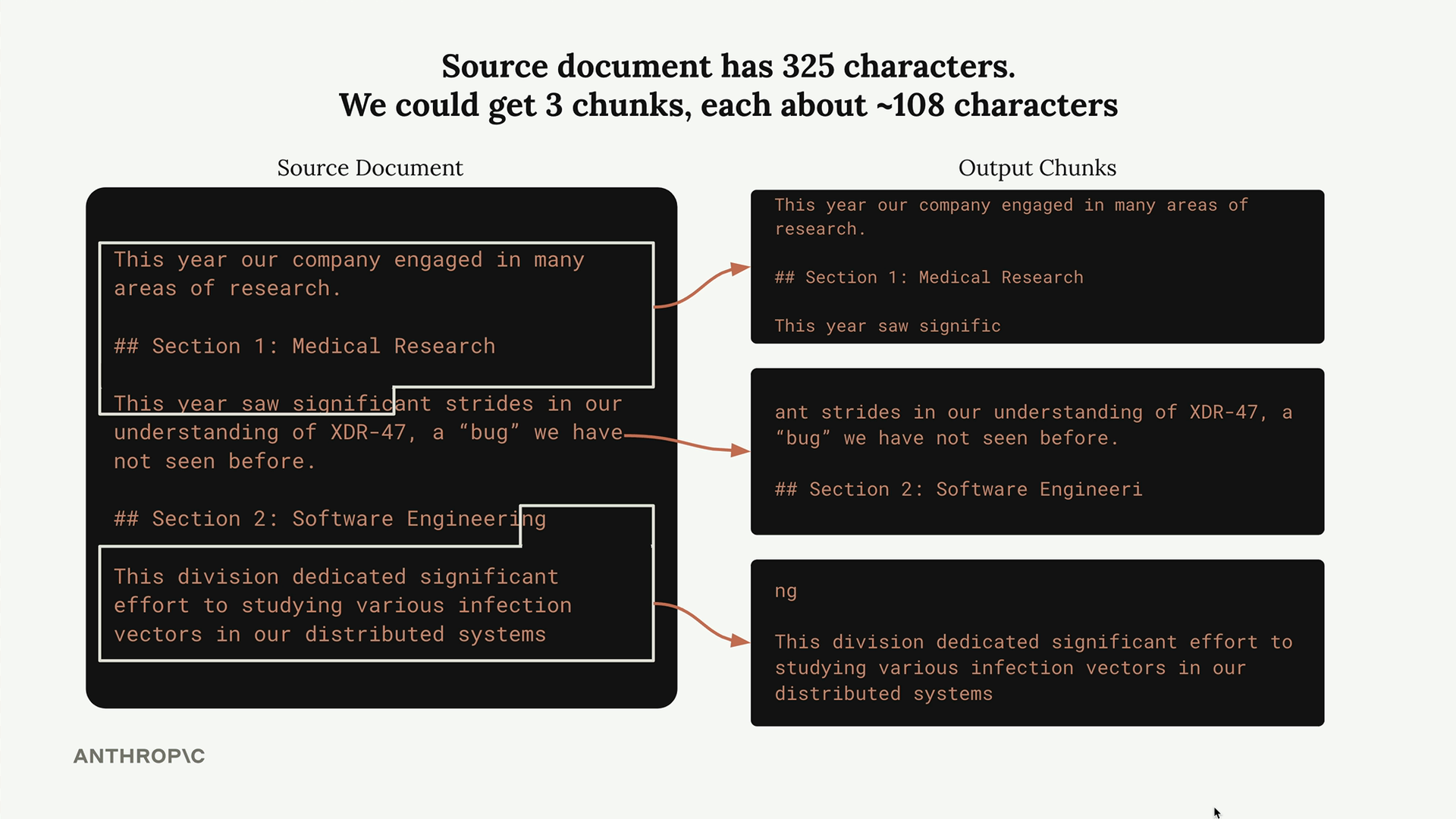
Tuy nhiên, phương pháp này có nhược điểm rõ ràng. Các từ bị cắt giữa câu và các chunk bị mất ngữ cảnh quan trọng. Ví dụ, một chunk có thể không bao gồm tiêu đề phần giải thích nội dung thực sự nói về điều gì.

Giải pháp là thêm sự chồng lấn (overlap) giữa các chunk. Mỗi chunk bao gồm một số ký tự từ các chunk lân cận, đảm bảo bảo toàn ngữ cảnh tốt hơn và tránh bị cắt đột ngột.
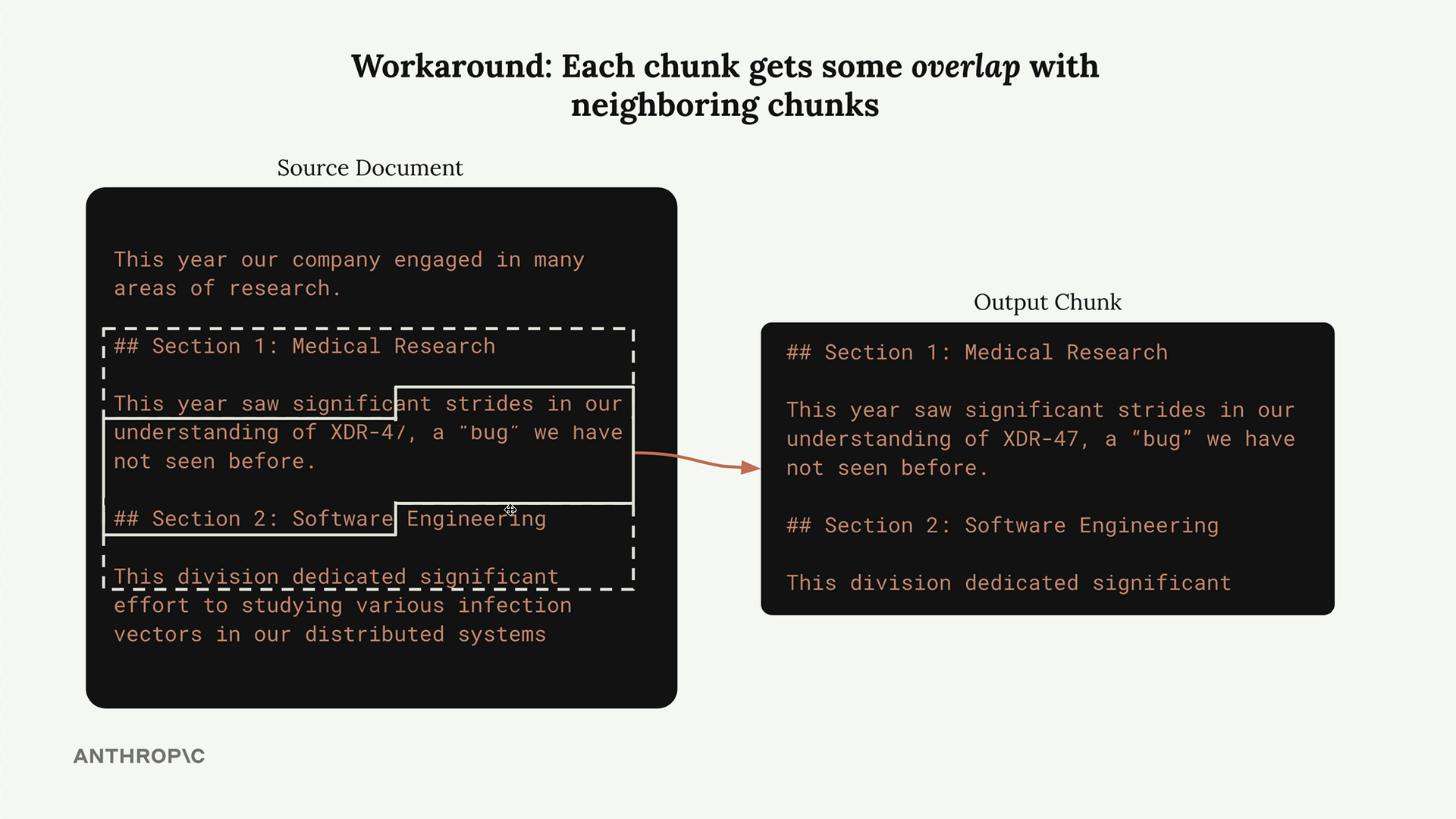
Đây là một triển khai cơ bản của chunking dựa trên ký tự có chồng lấn:
def chunk_by_char(text, chunk_size=150, chunk_overlap=20):
chunks = []
start_idx = 0
while start_idx < len(text):
end_idx = min(start_idx + chunk_size, len(text))
chunk_text = text[start_idx:end_idx]
chunks.append(chunk_text)
start_idx = (
end_idx - chunk_overlap if end_idx < len(text) else len(text)
)
return chunks
Chunking dựa trên cấu trúc
Chunking dựa trên cấu trúc tận dụng tổ chức tự nhiên của tài liệu bạn. Nếu bạn làm việc với các tệp markdown, bạn có thể chia theo tiêu đề. Đối với các định dạng khác, bạn có thể chia theo đoạn văn hoặc các yếu tố cấu trúc khác.
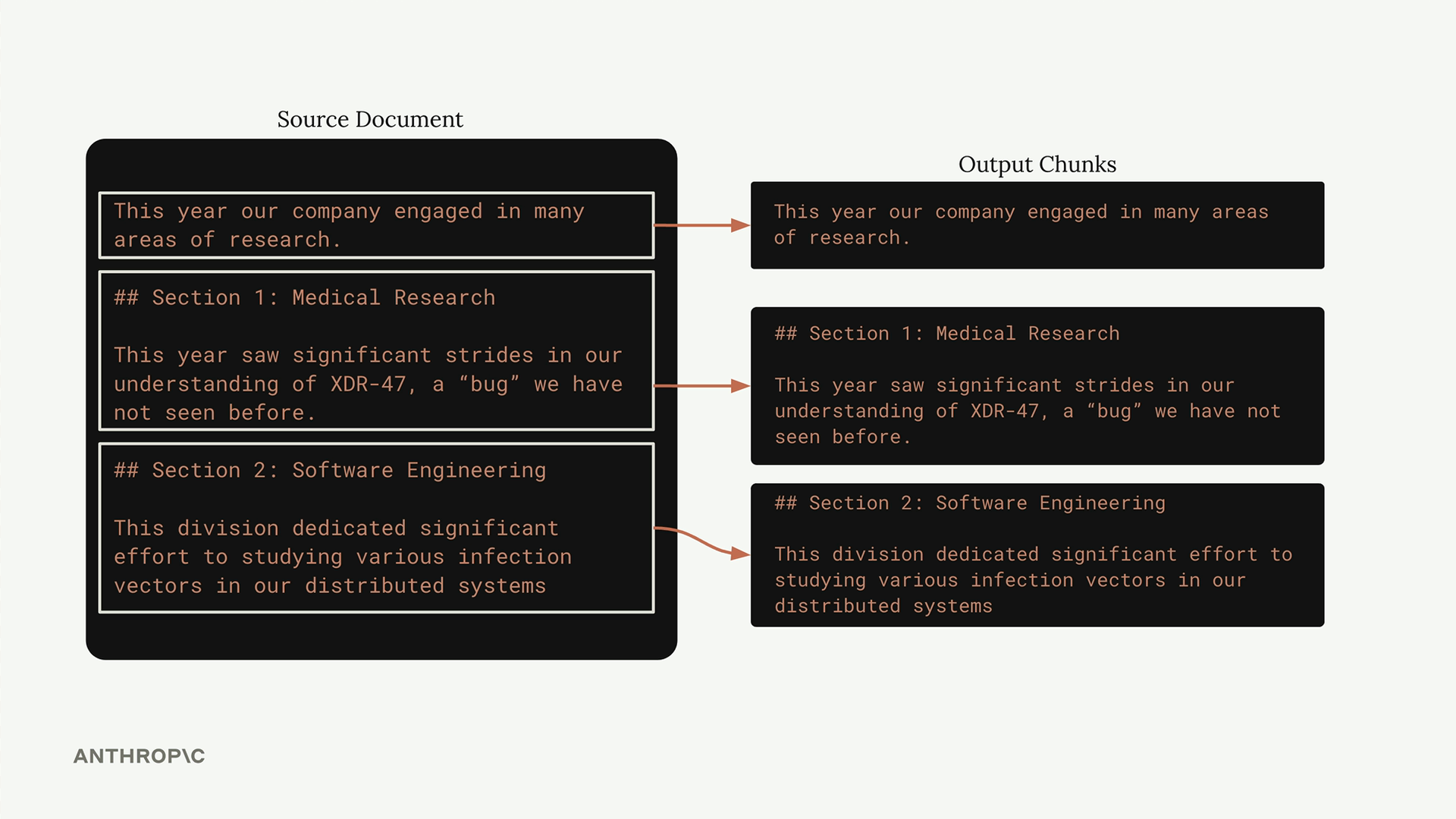
Phương pháp này hoạt động hiệu quả khi bạn có sự đảm bảo về cấu trúc tài liệu. Đối với tài liệu markdown, bạn có thể chia theo tiêu đề mục:
def chunk_by_section(document_text):
pattern = r'\n## '
return re.split(pattern, document_text)
Hạn chế chính là nhiều tài liệu không có cấu trúc nhất quán. Các tệp văn bản thuần túy, PDF hoặc tài liệu do người dùng tải lên có thể không có các dấu hiệu cấu trúc rõ ràng để chia.
Chunking dựa trên ngữ nghĩa
Chunking dựa trên ngữ nghĩa là phương pháp tinh vi nhất. Nó phân tích ý nghĩa và mối quan hệ giữa các câu để nhóm nội dung liên quan lại với nhau. Điều này thường bao gồm:
- Chia văn bản thành các câu.
- Sử dụng các kỹ thuật NLP để đo lường sự tương đồng về ngữ nghĩa.
- Nhóm các câu liên quan thành các chunk mạch lạc.
Mặc dù cách này có thể tạo ra các chunk chất lượng cao nhất, nhưng nó tốn kém về mặt tính toán và phức tạp hơn để triển khai. Đối với hầu hết các ứng dụng, các phương pháp đơn giản hơn là đủ tốt.
Triển khai thực tế
Đây là một hàm chunking dựa trên câu cung cấp một giải pháp cân bằng tốt:
def chunk_by_sentence(text, max_sentences_per_chunk=5, overlap_sentences=1):
sentences = re.split(r'(?<=[.!?])\s+', text)
chunks = []
start_idx = 0
while start_idx < len(sentences):
end_idx = min(start_idx + max_sentences_per_chunk, len(sentences))
current_chunk = sentences[start_idx:end_idx]
chunks.append(' '.join(current_chunk))
start_idx += max_sentences_per_chunk - overlap_sentences
if start_idx < 0:
start_idx = 0
return chunks
Chọn chiến lược phù hợp
Lựa chọn chiến lược chunking của bạn phụ thuộc hoàn toàn vào trường hợp sử dụng cụ thể của bạn:
- Cấu trúc tài liệu nhất quán: Sử dụng chunking dựa trên cấu trúc để có kết quả rõ ràng nhất.
- Nhiều loại tài liệu: Chunking dựa trên câu thường hoạt động tốt.
- Mã hoặc nội dung kỹ thuật: Chunking dựa trên ký tự là đáng tin cậy nhất.
- Định dạng tài liệu không xác định: Chunking dựa trên ký tự là lựa chọn an toàn nhất của bạn.
Hãy nhớ rằng chunking thường là một quá trình lặp đi lặp lại. Bắt đầu với một phương pháp đơn giản, kiểm tra nó với các tài liệu và trường hợp sử dụng cụ thể của bạn, sau đó tinh chỉnh dựa trên kết quả. Chiến lược chunking "tốt nhất" là chiến lược hoạt động đáng tin cậy cho dữ liệu và yêu cầu cụ thể của bạn.
Tải xuống
🔁 Bài học liên quan
- Bài tiếp: Text embeddings
- Bài trước: Introducing Retrieval Augmented Generation
- Cùng section: Making a request · Multi-turn conversations · Chat exercise
- Thuộc lộ trình: Path C
- Docs tham khảo: Glossary · Skills atlas · By use-case
📚 Nguồn & ghi nhận
- Bài học gốc Anthropic Academy: https://anthropic.skilljar.com/claude-with-google-vertex/289208
- © 2025 Anthropic. Chỉ dùng cho mục đích giáo dục, fair-use.
- Crawl: — · Chuẩn hoá: 2026-05-01