📖 Lesson content
Summary
Text chunking is one of the most critical steps in building a RAG (Retrieval Augmented Generation) pipeline. How you break up your documents directly impacts the quality of your entire system. A poor chunking strategy can lead to irrelevant context being inserted into your prompts, causing your AI to give completely wrong answers.

Consider this example: you have a document with sections on medical research and software engineering. If you chunk poorly, a user asking "How many bugs did engineers fix this year?" might get information about medical research instead of software engineering, simply because the medical section happened to contain the word "bug" in a different context.
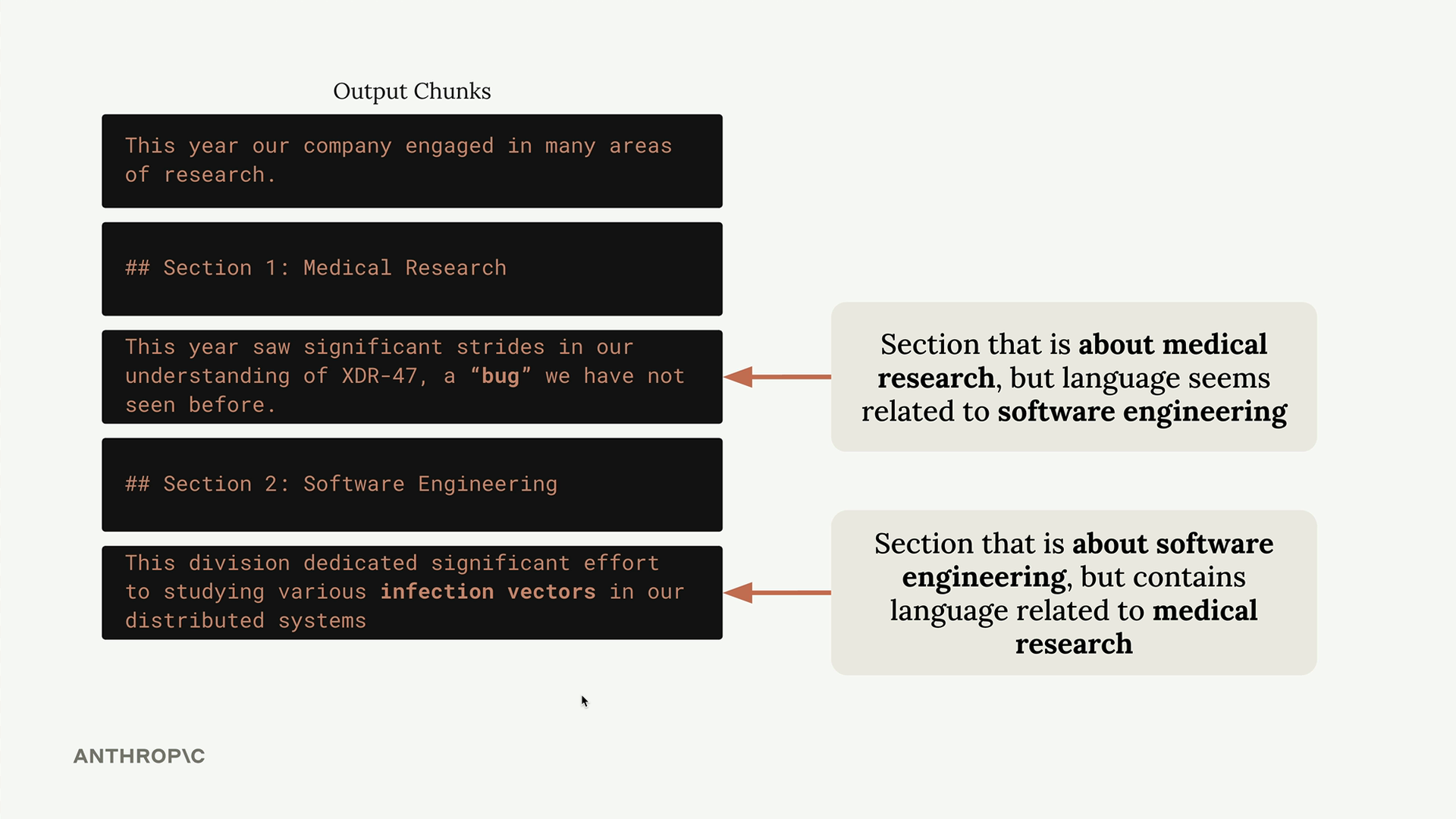
This demonstrates why chunking strategy matters so much. The goal is to create chunks that maintain semantic coherence and provide meaningful context when retrieved.

Three Main Chunking Strategies
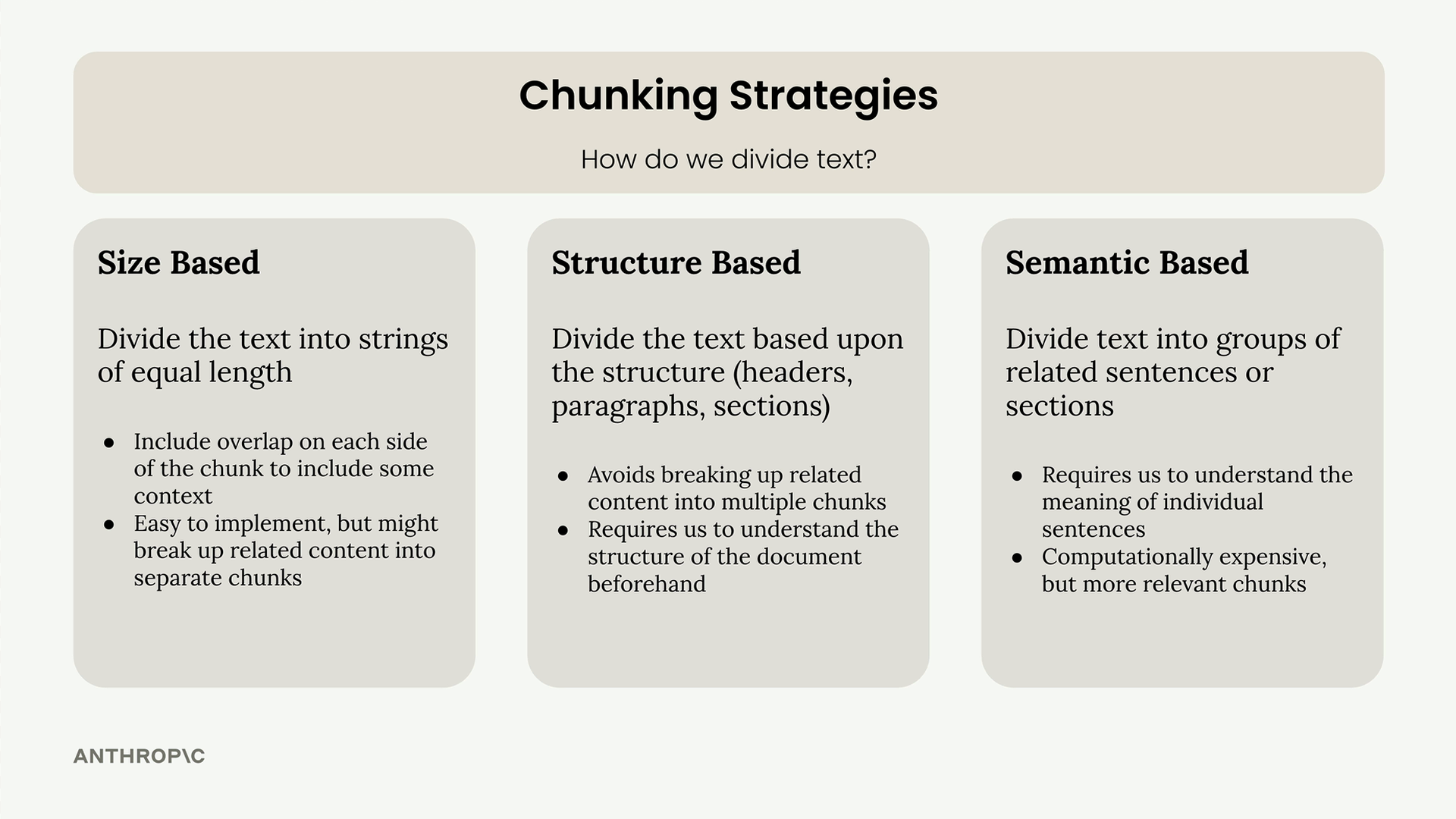
There are three primary approaches to chunking text, each with distinct advantages and trade-offs:
- Size-based: Divide text into strings of equal length
- Structure-based: Split based on document structure (headers, paragraphs, sections)
- Semantic-based: Group related sentences or sections using NLP techniques
Size-Based Chunking
Size-based chunking is the most straightforward approach. You simply divide your document into chunks of approximately equal character or word count. It's easy to implement and works reliably across different document types.
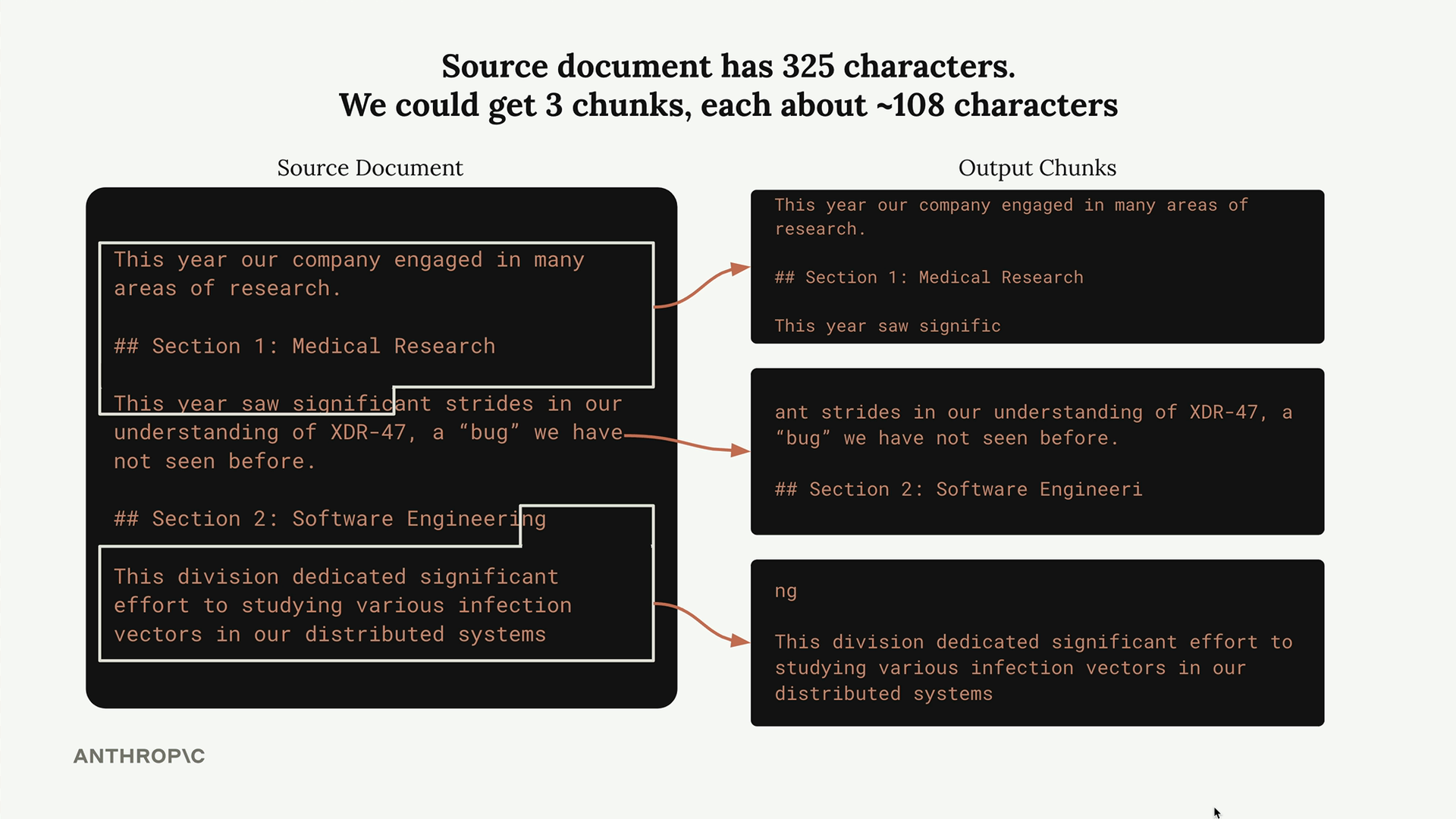
However, this approach has clear downsides. Words get cut off mid-sentence, and chunks lose important context. For example, a chunk might not include the section header that would explain what the content is actually about.

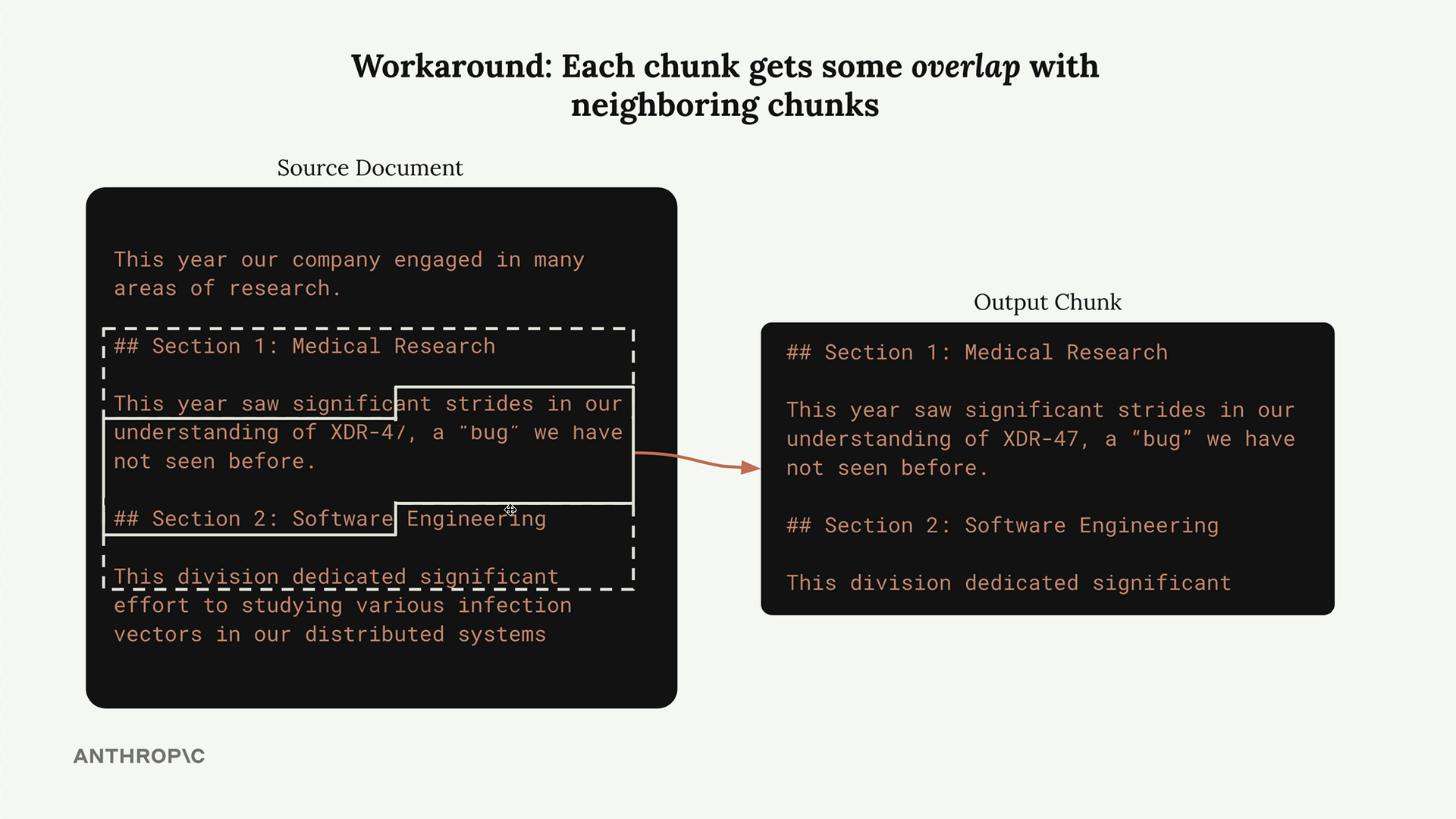
The solution is to add overlap between chunks. Each chunk includes some characters from neighboring chunks, ensuring better context preservation and avoiding abrupt cutoffs.
Here's a basic implementation of character-based chunking with overlap:
def chunk_by_char(text, chunk_size=150, chunk_overlap=20):
chunks = []
start_idx = 0
while start_idx < len(text):
end_idx = min(start_idx + chunk_size, len(text))
chunk_text = text[start_idx:end_idx]
chunks.append(chunk_text)
start_idx = (
end_idx - chunk_overlap if end_idx < len(text) else len(text)
)
return chunks
Structure-Based Chunking
Structure-based chunking leverages the natural organization of your documents. If you're working with markdown files, you can split on headers. For other formats, you might split on paragraphs or other structural elements.
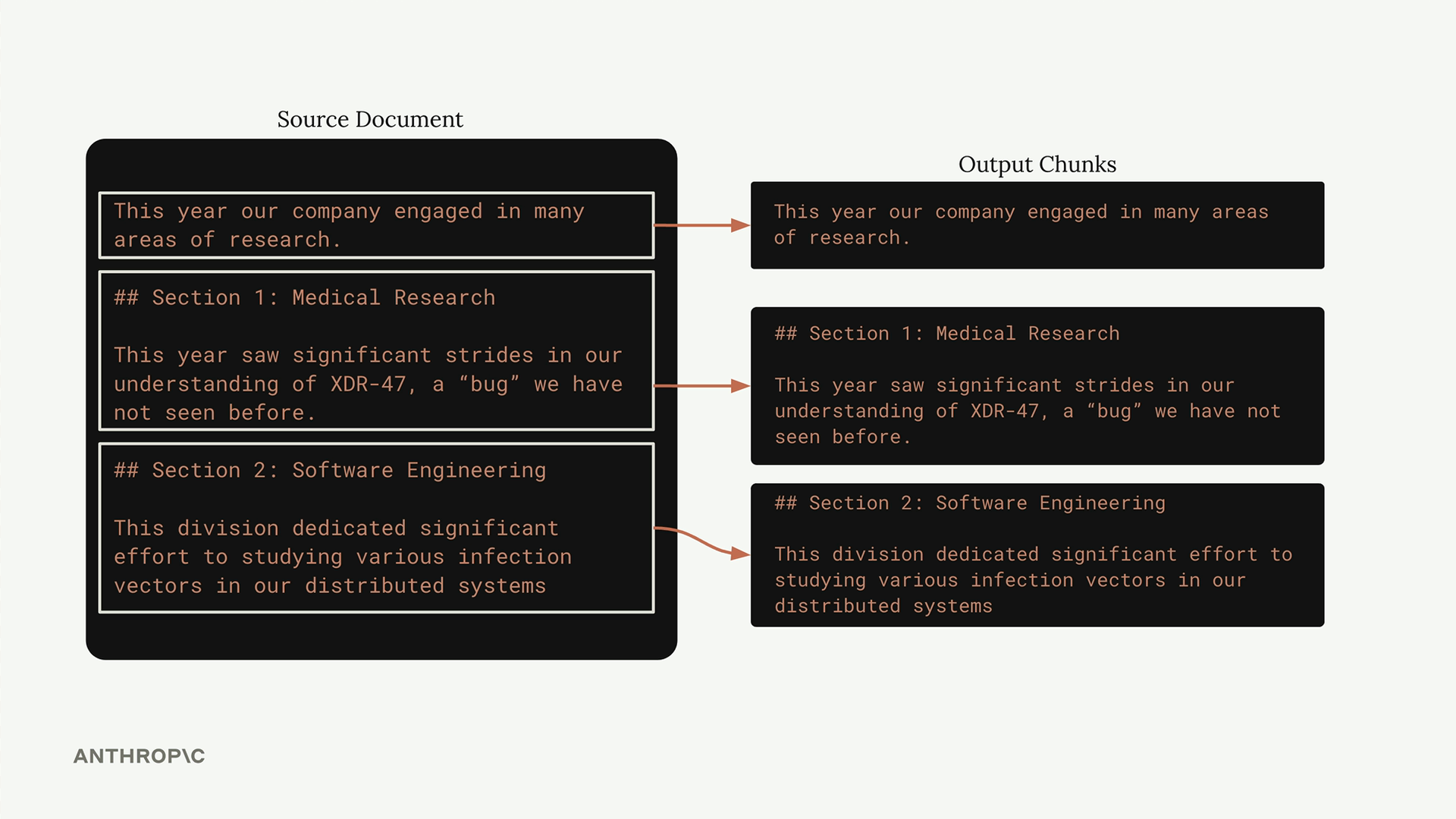
This approach works beautifully when you have guarantees about document structure. For markdown documents, you can split on section headers:
def chunk_by_section(document_text):
pattern = r'\n## '
return re.split(pattern, document_text)
The major limitation is that many documents don't have consistent structure. Plain text files, PDFs, or user-uploaded documents might not have clear structural markers to split on.
Semantic-Based Chunking
Semantic-based chunking is the most sophisticated approach. It analyzes the meaning and relationships between sentences to group related content together. This typically involves:
- Breaking text into sentences
- Using NLP techniques to measure semantic similarity
- Grouping related sentences into coherent chunks
While this can produce the highest quality chunks, it's computationally expensive and more complex to implement. For most applications, the simpler approaches work well enough.
Practical Implementation
Here's a sentence-based chunking function that offers a good middle ground:
def chunk_by_sentence(text, max_sentences_per_chunk=5, overlap_sentences=1):
sentences = re.split(r'(?<=[.!?])\s+', text)
chunks = []
start_idx = 0
while start_idx < len(sentences):
end_idx = min(start_idx + max_sentences_per_chunk, len(sentences))
current_chunk = sentences[start_idx:end_idx]
chunks.append(' '.join(current_chunk))
start_idx += max_sentences_per_chunk - overlap_sentences
if start_idx < 0:
start_idx = 0
return chunks
Choosing the Right Strategy
Your choice of chunking strategy depends entirely on your specific use case:
- Consistent document structure: Use structure-based chunking for the cleanest results
- Mixed document types: Sentence-based chunking often works well
- Code or technical content: Character-based chunking is most reliable
- Unknown document formats: Character-based chunking is your safest bet
Remember that chunking is often an iterative process. Start with a simple approach, test it with your specific documents and use cases, then refine based on the results. The "best" chunking strategy is the one that works reliably for your particular data and requirements.
Downloads
🔁 Related lessons
- Next: Text embeddings
- Previous: Introducing Retrieval Augmented Generation
- Same section: Making a request · Multi-turn conversations · Chat exercise
- Part of paths: Path C
- Reference docs: Glossary · Skills atlas · By use-case
📚 Source & attribution
- Original Anthropic Academy lesson: https://anthropic.skilljar.com/claude-with-google-vertex/289208
- © 2025 Anthropic. Educational fair-use only.