📖 Nội dung bài học
Bật/Tắt tiếngm Kích cỡ chữ Video này đang được xử lý. Vui lòng quay lại sau và tải lại trang.
Tóm tắt
Sau khi trích xuất các đoạn văn bản (text chunks) từ tài liệu, bước tiếp theo trong một quy trình RAG là tìm xem đoạn nào liên quan nhất đến câu hỏi của người dùng. Đây thực chất là một bài toán tìm kiếm - bạn cần rà soát tất cả các chunk và xác định những đoạn liên quan đến nội dung người dùng đang hỏi.

Tìm kiếm ngữ nghĩa (Semantic Search)
Cách tiếp cận phổ biến nhất để tìm các chunk liên quan là tìm kiếm ngữ nghĩa (semantic search). Khác với tìm kiếm dựa trên từ khóa truyền thống, semantic search sử dụng text embeddings để hiểu ý nghĩa thực sự của cả câu hỏi người dùng và từng đoạn văn bản. Điều này cho phép hệ thống tìm thấy nội dung liên quan về mặt khái niệm ngay cả khi các từ ngữ chính xác không khớp nhau.

Text Embeddings là gì?
Một text embedding là một biểu diễn bằng số của ý nghĩa chứa trong một đoạn văn bản. Hãy coi đó là việc chuyển đổi từ ngữ và câu văn sang một định dạng mà máy tính có thể xử lý bằng toán học.
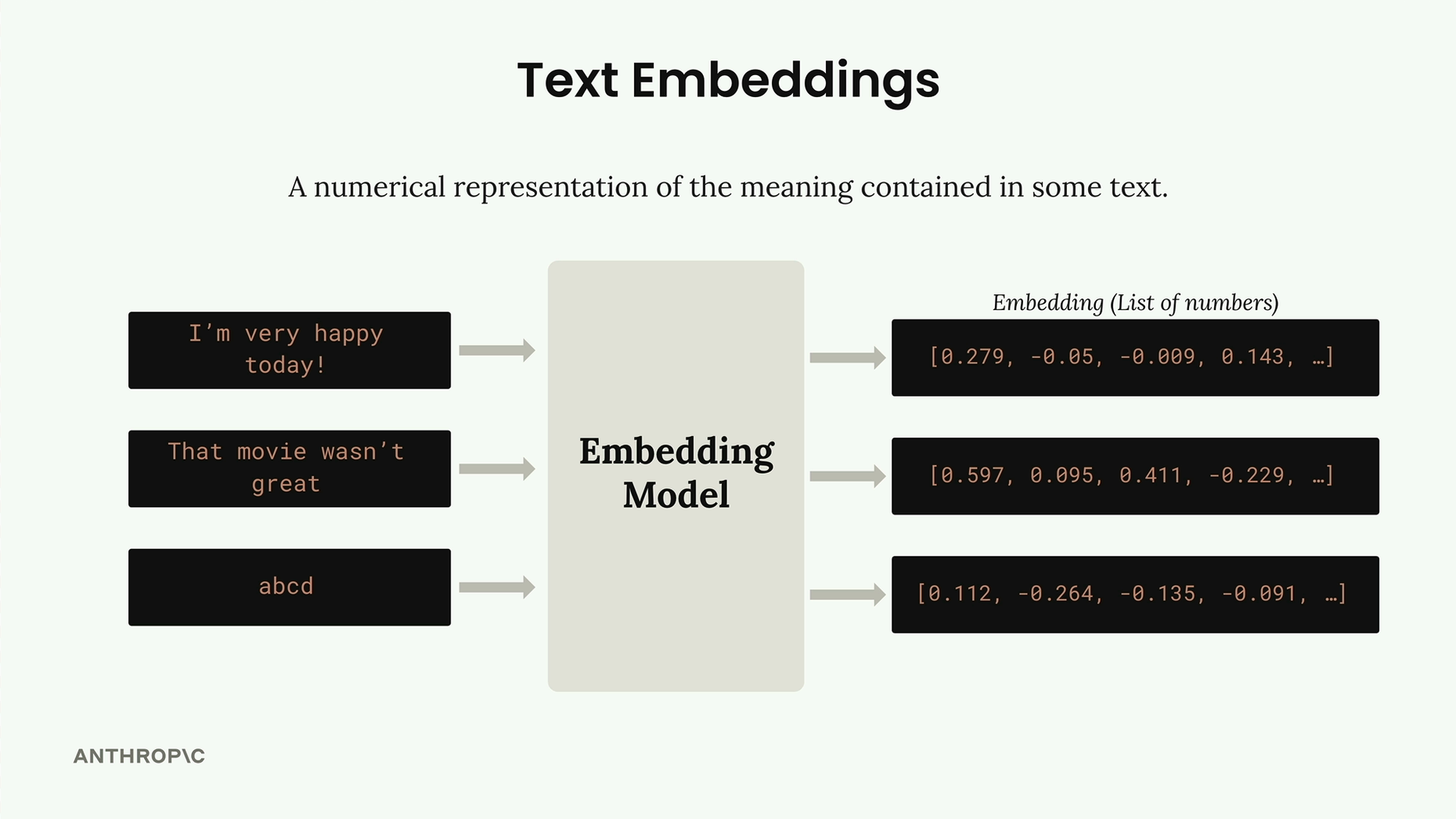
Quy trình hoạt động như sau:
- Bạn đưa văn bản vào một embedding model.
- Mô hình xuất ra một danh sách dài các con số (chính là embedding).
- Mỗi số nằm trong khoảng từ -1 đến +1.
- Những con số này đại diện cho các đặc tính hoặc tính chất khác nhau của văn bản đầu vào.
Hiểu về các con số
Mỗi con số trong một embedding về cơ bản là một "điểm số" cho một đặc tính nào đó của văn bản đầu vào. Tuy nhiên, có một lưu ý quan trọng: chúng ta không thực sự biết mỗi con số cụ thể đại diện cho điều gì.

Mặc dù việc tưởng tượng rằng một số đại diện cho "văn bản này vui vẻ đến mức nào" và một số khác đại diện cho "văn bản nói về đại dương nhiều hay ít" là rất hữu ích, nhưng đó chỉ là các ví dụ mang tính khái niệm. Embedding model tự học các đặc tính này trong quá trình huấn luyện, nhưng chúng không được dán nhãn rõ ràng hoặc có thể giải thích được đối với chúng ta.
Bất chấp sự mơ hồ này, embeddings cực kỳ mạnh mẽ vì chúng nắm bắt được ý nghĩa ngữ nghĩa theo cách cho phép so sánh toán học giữa các đoạn văn bản khác nhau.
Embeddings trên Vertex AI
Claude không thể tạo embedding trực tiếp. Thay vào đó, bạn cần sử dụng một embedding model chuyên dụng. Trên Vertex AI, mô hình chúng ta sẽ sử dụng có tên là text-embedding-005.
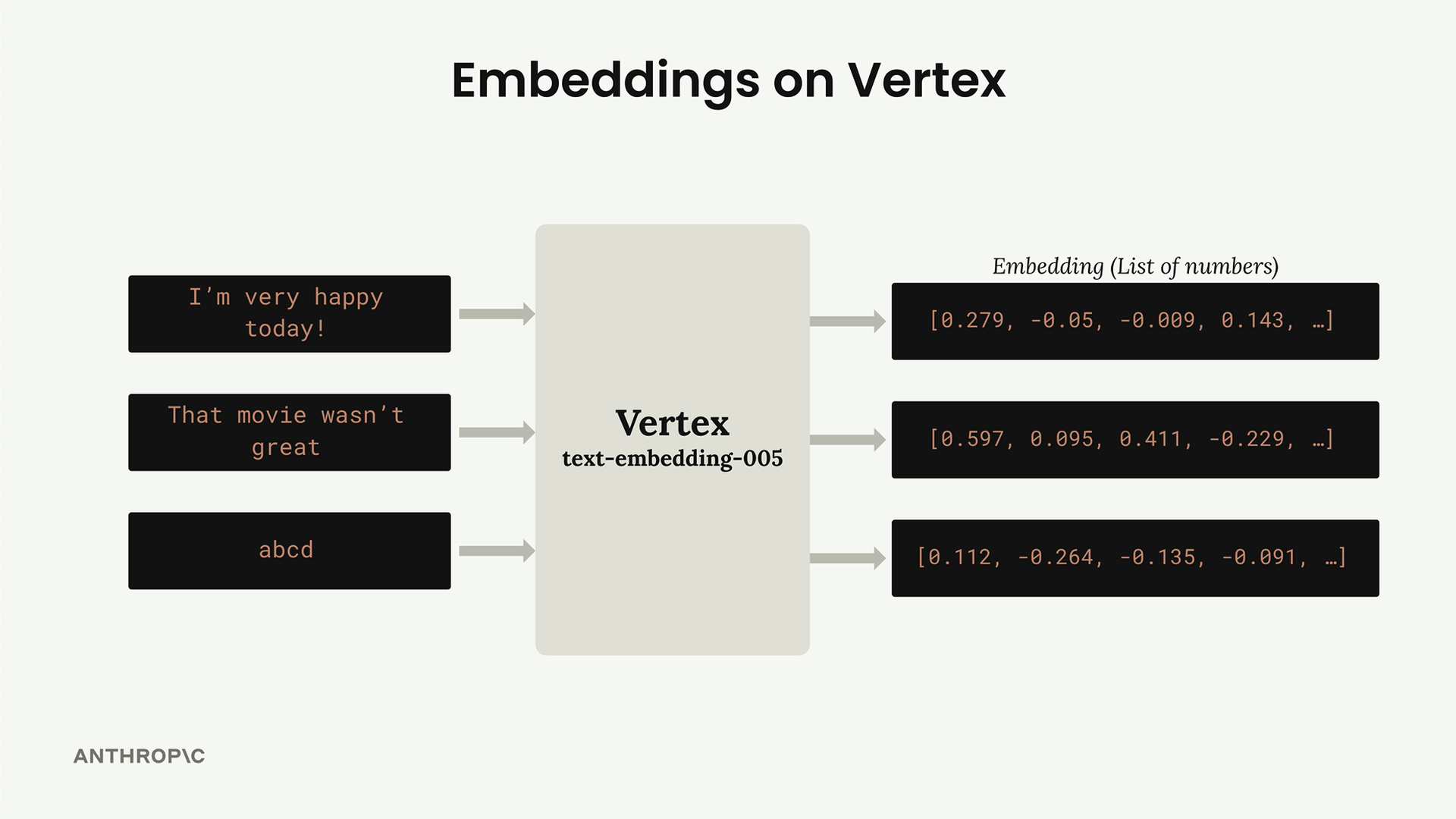
Triển khai
Để làm việc với embeddings trên Vertex AI, bạn cần cài đặt Google GenAI SDK:
pip install google-genai
Đây là thiết lập cơ bản để tạo embeddings:
from google import genai
client = genai.Client(
project="YOUR_PROJECT_ID",
location="global",
vertexai=True
)
def generate_embedding(text):
response = client.models.embed_content(
model="text-embedding-005",
contents=text
)
if not response.embeddings:
return []
return [e.values for e in response.embeddings]
Khi bạn chạy hàm này với một đoạn văn bản, bạn sẽ nhận lại một danh sách các số thực (floating-point numbers) đại diện cho ý nghĩa ngữ nghĩa của đoạn văn đó. Những embedding này tạo nên nền tảng để triển khai semantic search trong hệ thống RAG của bạn.
Bước tiếp theo là hiểu cách sử dụng các embedding này để thực sự tìm ra các chunk liên quan nhất cho câu hỏi của người dùng, bao gồm việc so sánh các embedding bằng toán học để xác định độ tương đồng (similarity).
Tải xuống
- [002_embeddings.ipynb](https://cc.sj-cdn.net/instructor/4hdejjwplbrm-anthropic-poc/assets/1748559816/002_embeddings.ipynb?
🔁 Bài học liên quan
- Bài tiếp: The full RAG flow
- Bài trước: Text chunking strategies
- Cùng section: Making a request · Multi-turn conversations · Chat exercise
- Thuộc lộ trình: Path C
- Docs tham khảo: Glossary · Skills atlas · By use-case
📚 Nguồn & ghi nhận
- Bài học gốc Anthropic Academy: https://anthropic.skilljar.com/claude-with-google-vertex/289188
- © 2025 Anthropic. Chỉ dùng cho mục đích giáo dục, fair-use.
- Crawl: 2026-04-23 · Chuẩn hoá: 2026-05-01