📖 Lesson content
Summary
Text chunking is one of the most critical steps in building a RAG (Retrieval Augmented Generation) pipeline. How you break up your documents directly impacts the quality of your entire system. A poor chunking strategy can lead to irrelevant context being inserted into your prompts, causing your AI to give completely wrong answers.

Consider this example: you have a document with sections on medical research and software engineering. If you chunk poorly, a user asking "How many bugs did engineers fix this year?" might get information about medical research instead of software engineering, simply because the medical section happened to contain the word "bug" in a different context.
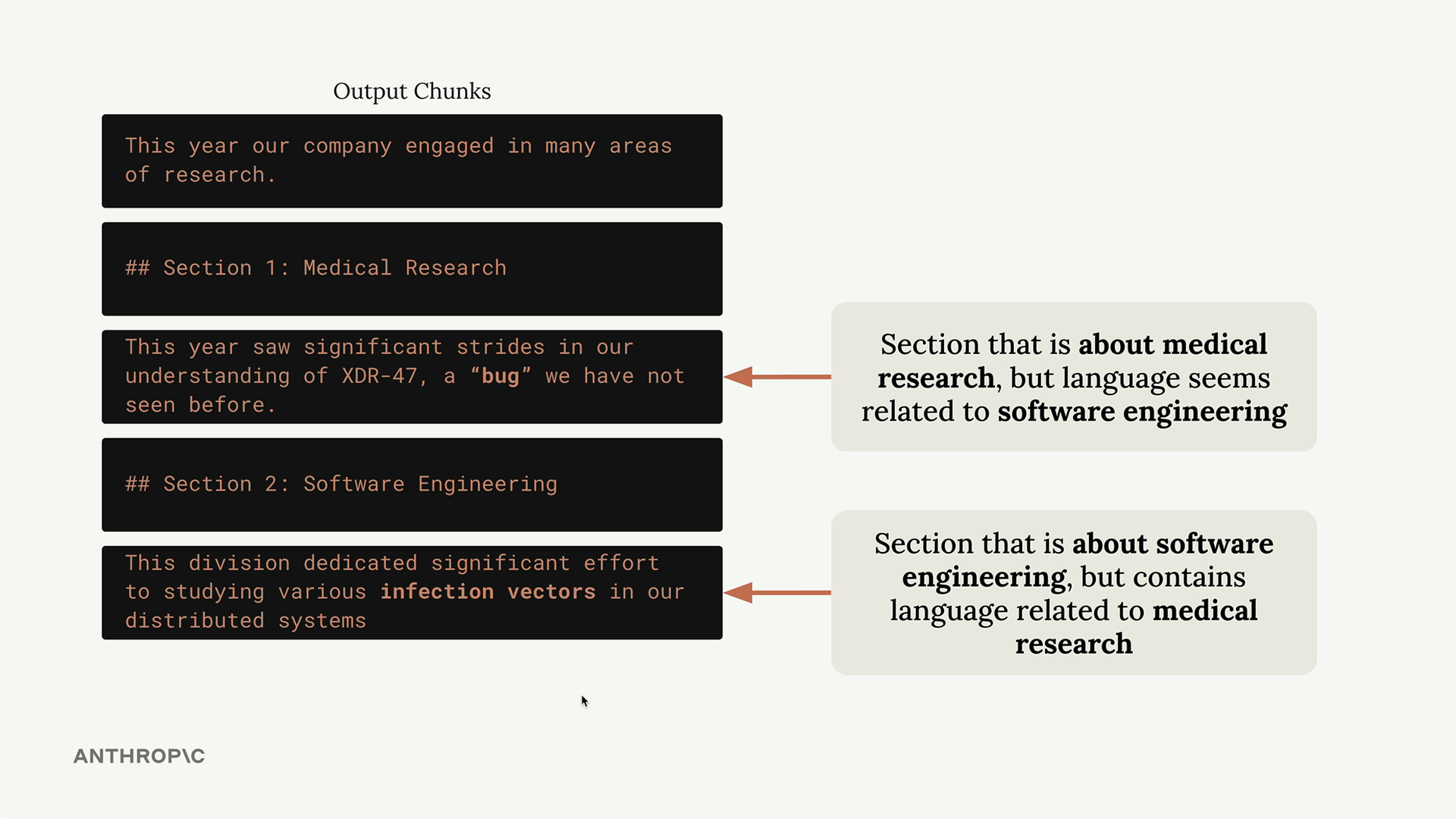
This demonstrates why chunking strategy matters so much. The goal is to create chunks that maintain semantic coherence and provide useful context when retrieved.

Three Main Chunking Strategies
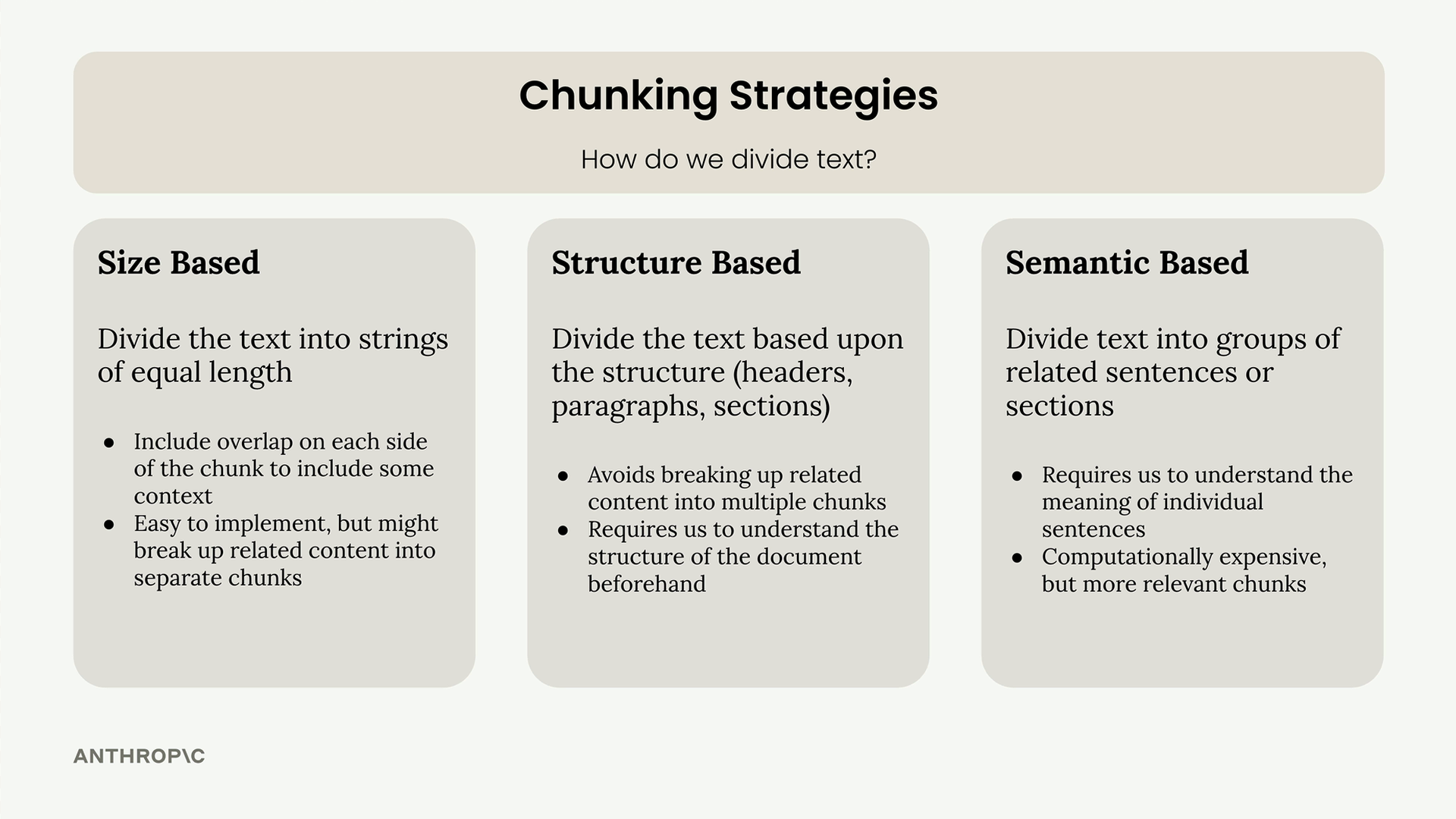
There are three primary approaches to dividing text into chunks:
- Size-based: Divide text into strings of equal length
- Structure-based: Split based on document structure (headers, paragraphs, sections)
- Semantic-based: Group related sentences or sections using NLP techniques
Size-Based Chunking
Size-based chunking is the most straightforward approach. You simply divide your document into chunks of roughly equal character or word count. It's easy to implement and works reliably across different document types.
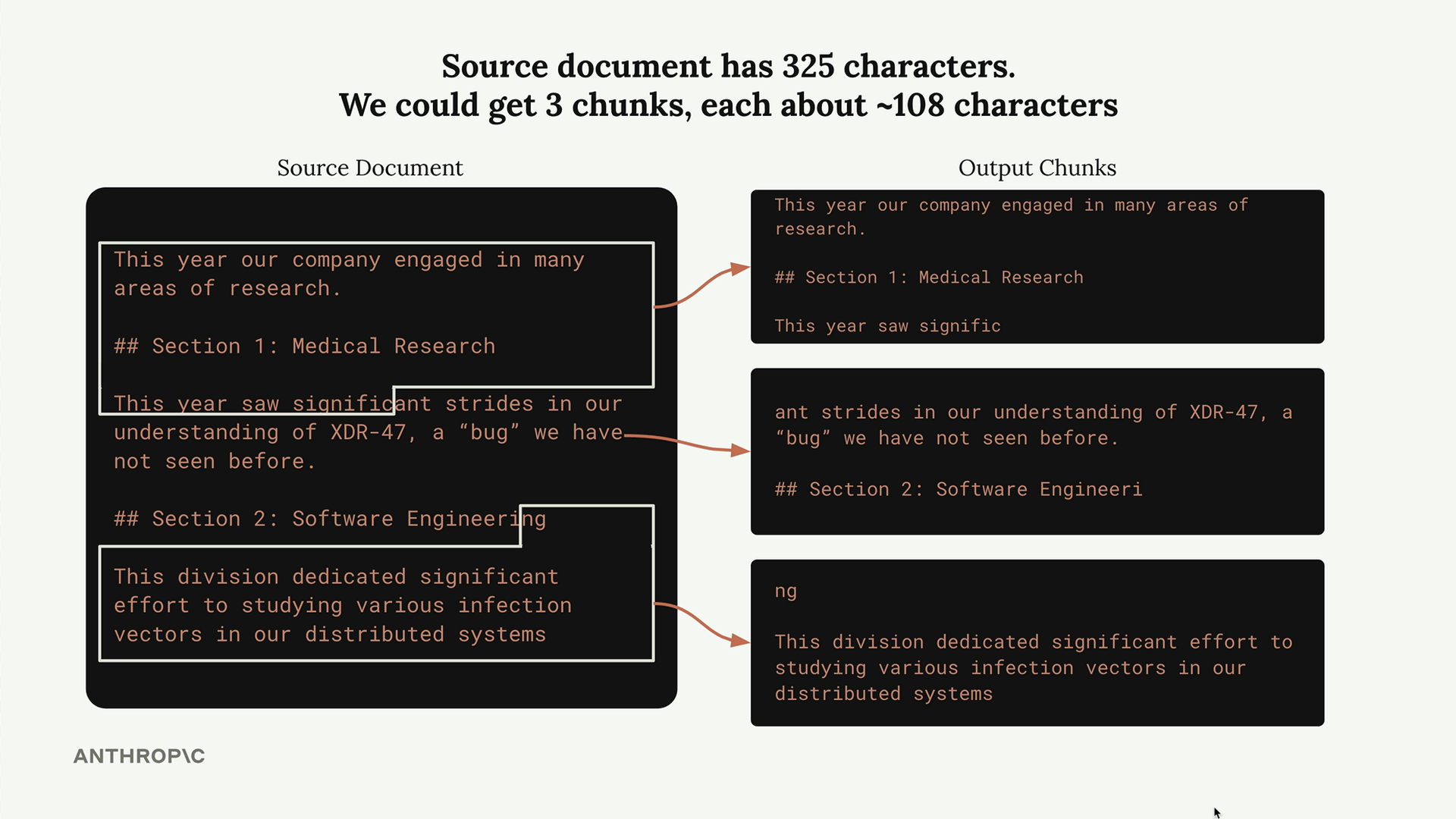
However, this approach has clear downsides:
- Words get cut off mid-sentence
- Chunks lose important context from surrounding text
- Related content might be split across multiple chunks

Adding Overlap
To address the context problem, you can implement an overlap strategy. Each chunk includes some characters from neighboring chunks, providing additional context and ensuring important information isn't lost at chunk boundaries.
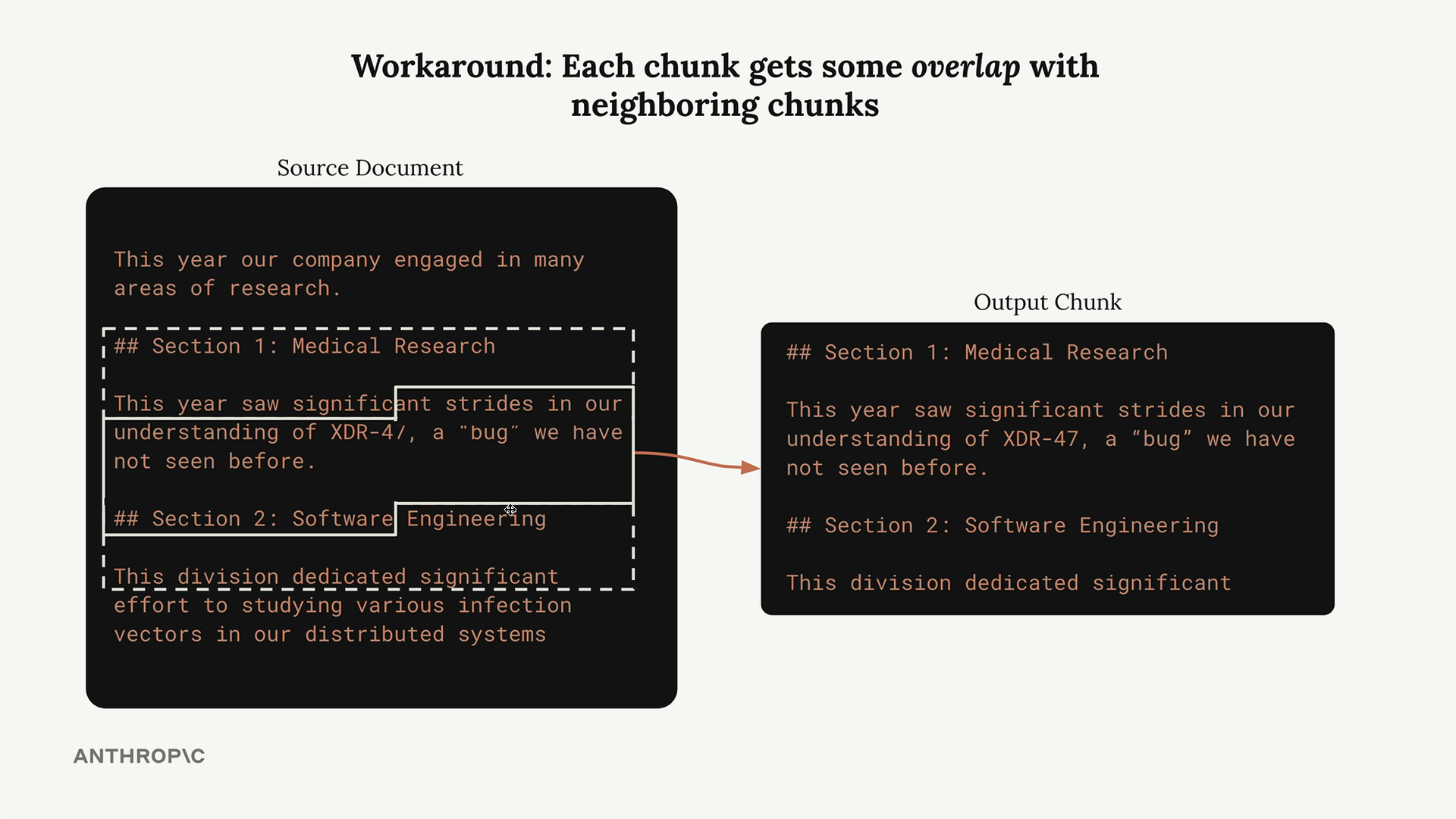
While this creates some duplication, the trade-off is usually worth it for the improved context each chunk receives.
Structure-Based Chunking
When your documents have consistent formatting (like markdown with clear headers), structure-based chunking can produce excellent results. You split on structural elements like headers, creating chunks that align with the document's natural organization.
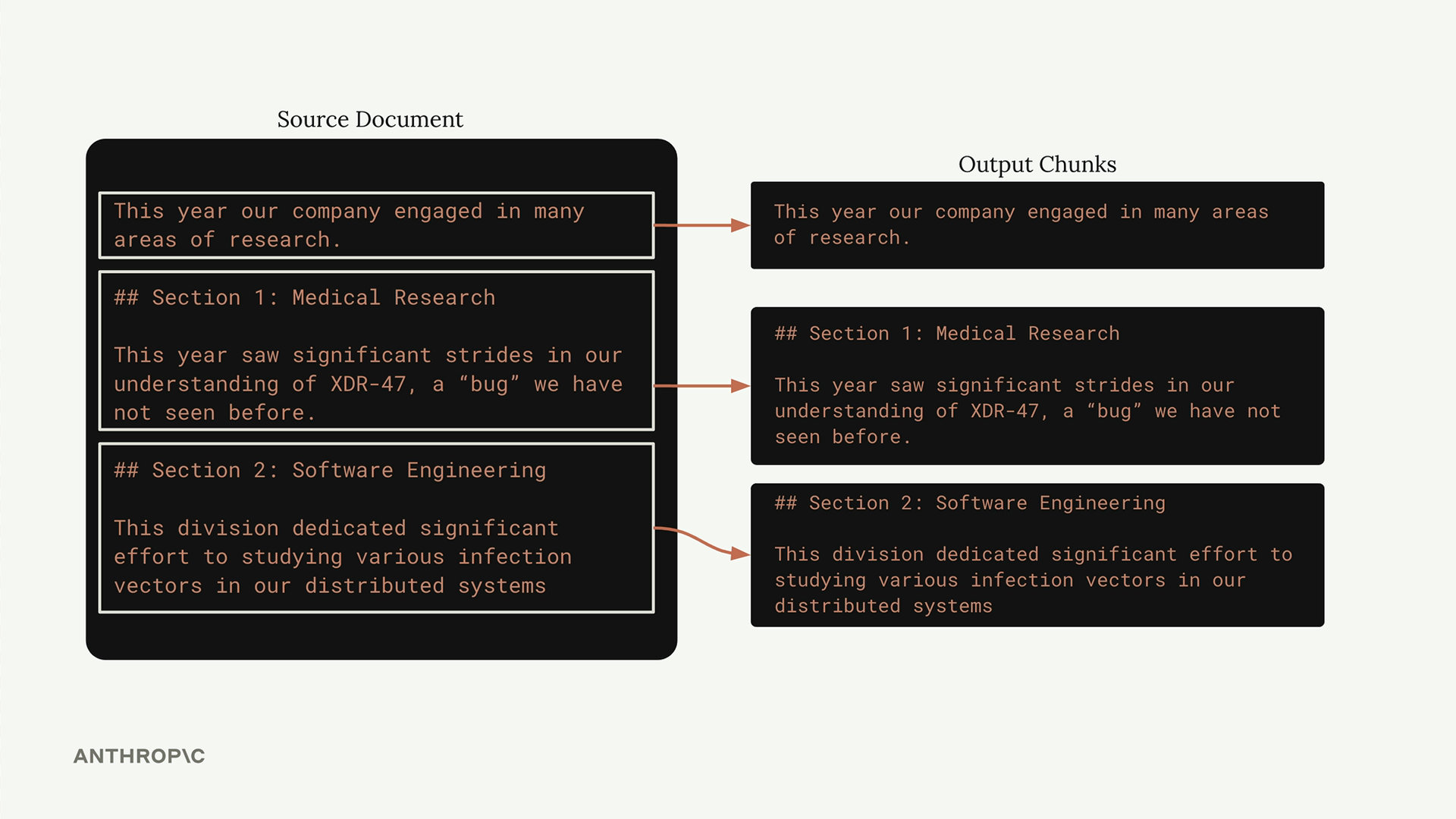
This works beautifully for well-formatted documents but requires guarantees about document structure. It won't work reliably with plain text files or inconsistently formatted documents.
Implementation Examples
Here are three practical chunking functions you can implement:
Character-Based Chunking
def chunk_by_char(text, chunk_size=150, chunk_overlap=20):
chunks = []
start_idx = 0
while start_idx < len(text):
end_idx = min(start_idx + chunk_size, len(text))
chunk_text = text[start_idx:end_idx]
chunks.append(chunk_text)
start_idx = (
end_idx - chunk_overlap if end_idx < len(text) else len(text)
)
return chunks
Sentence-Based Chunking
def chunk_by_sentence(text, max_sentences_per_chunk=5, overlap_sentences=1):
sentences = re.split(r"(?<=[.!?])\s+", text)
chunks = []
start_idx = 0
while start_idx < len(sentences):
end_idx = min(start_idx + max_sentences_per_chunk, len(sentences))
current_chunk = sentences[start_idx:end_idx]
chunks.append(" ".join(current_chunk))
start_idx += max_sentences_per_chunk - overlap_sentences
if start_idx < 0:
start_idx = 0
return chunks
Section-Based Chunking
def chunk_by_section(document_text):
pattern = r"\n## "
return re.split(pattern, document_text)
Choosing the Right Strategy
Your choice of chunking strategy depends entirely on your specific use case:
- Character-based: Most reliable fallback, works with any document type
- Sentence-based: Good balance of context and meaning for prose
- Section-based: Excellent results when you have structured documents
For user-uploaded documents with no formatting guarantees, character-based chunking is often your safest bet. For well-structured internal documents, section-based chunking can provide superior results. Sentence-based chunking works well for most prose but can struggle with code or technical documents that use periods in unexpected ways.
Remember that chunking is often an iterative process. Start with a simple approach, test it with your specific documents and use cases, then refine based on the quality of results you're getting from your RAG system.
Downloads
🔁 Related lessons
- Next: Text embeddings
- Previous: Introducing Retrieval Augmented Generation
- Same section: Overview of Claude Models · Accessing the API · Making a request
- Part of paths: Path C
- Reference docs: Glossary · Skills atlas · By use-case
📚 Source & attribution
- Original Anthropic Academy lesson: https://anthropic.skilljar.com/claude-in-amazon-bedrock/276782
- © 2025 Anthropic. Educational fair-use only.