📖 Lesson content
Summary
After breaking a document into chunks, the next step in a RAG pipeline is finding which chunks are most relevant to a user's question. This is fundamentally a search problem - you need to look through all your text chunks and identify the ones that relate to what the user is asking about.
Finding Relevant Chunks
The challenge is determining which chunks are "related" to a user's question. This isn't as simple as keyword matching - you need to understand the meaning and context of both the question and the chunks.

The most common solution is semantic search, which uses text embeddings to understand what each piece of text is actually about, rather than just looking for exact word matches.
What Are Text Embeddings?
A text embedding is a numerical representation of the meaning contained in some text. Think of it as converting words and sentences into a format that computers can work with mathematically.
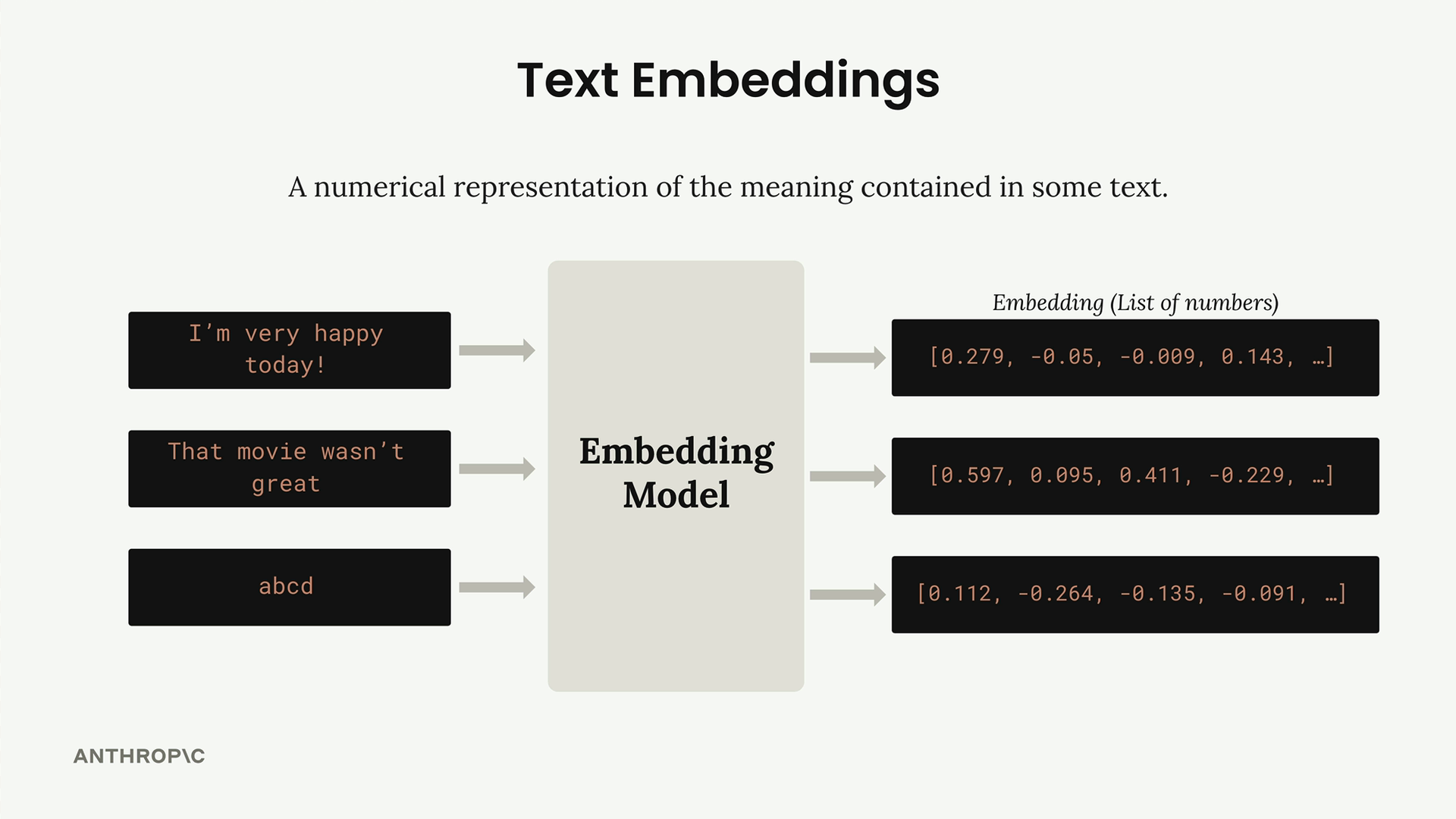
Here's how it works:
- You feed text into an embedding model
- The model outputs a long list of numbers (typically 1024 numbers)
- Each number represents a "score" for some quality of the input text
- The numbers range from -1 to +1
Understanding the Numbers
Each number in an embedding is like a score for some aspect of the text. While we don't know exactly what each position represents, it's helpful to think of them as measuring different qualities.

For example, one number might score "how happy the text is" while another might measure "how much the text talks about oceans." The key point is that we don't actually know what each number represents - the embedding model learns these patterns during training, and they're not human-interpretable.
Generating Embeddings with Code
Creating embeddings is straightforward. Here's the basic process:
def generate_embedding(
text,
embedding_model_id="amazon.titan-embed-text-v2:0",
dimensions=1024,
normalize=True,
):
request_body = {
"inputText": text,
"dimensions": dimensions,
"normalize": normalize,
}
request_json = json.dumps(request_body)
response = client.invoke_model(
modelId=embedding_model_id,
body=request_json,
accept="application/json",
contentType="application/json",
)
response_body = json.loads(response.get("body").read())
return response_body["embedding"]
When you run this function on a text chunk, you get back a list of 1024 numbers that represent the semantic meaning of that text.
Note that you might need to request access to the Titan embedding model in the AWS Bedrock console. If version 2 isn't available, version 1 works just as well for learning purposes.
Why Embeddings Matter for RAG
The power of embeddings becomes clear when you realize that similar texts will have similar embedding values. This means you can mathematically compare a user's question to your document chunks and find the most semantically similar ones - even if they don't share the exact same words.
This numerical representation is what makes semantic search possible and much more effective than simple keyword matching for finding relevant context in RAG systems.
Downloads
🔁 Related lessons
- Next: The full RAG flow
- Previous: Text chunking strategies
- Same section: Overview of Claude Models · Accessing the API · Making a request
- Part of paths: Path C
- Reference docs: Glossary · Skills atlas · By use-case
📚 Source & attribution
- Original Anthropic Academy lesson: https://anthropic.skilljar.com/claude-in-amazon-bedrock/276777
- © 2025 Anthropic. Educational fair-use only.