📖 Nội dung bài học
Tóm tắt
Chấm điểm dựa trên mã nguồn (Code-based grading) bổ sung thêm một lớp kiểm chứng (validation) cho các đánh giá prompt của bạn bằng cách kiểm tra xem đầu ra của mô hình có tuân thủ đúng định dạng và cú pháp hay không. Điều này đặc biệt hữu ích khi bạn yêu cầu mô hình tạo mã nguồn, JSON hoặc biểu thức chính quy (regex).
Cách thức hoạt động của Code Grading
Bộ chấm điểm mã nguồn đánh giá dựa trên hai tiêu chí chính:
- Tuân thủ định dạng (Format compliance) - Đầu ra có chỉ chứa định dạng được yêu cầu (Python, JSON, hoặc regex) mà không kèm theo lời giải thích nào không?
- Cú pháp hợp lệ (Valid syntax) - Đầu ra có thực sự được phân tích (parse) hoặc biên dịch thành công không?
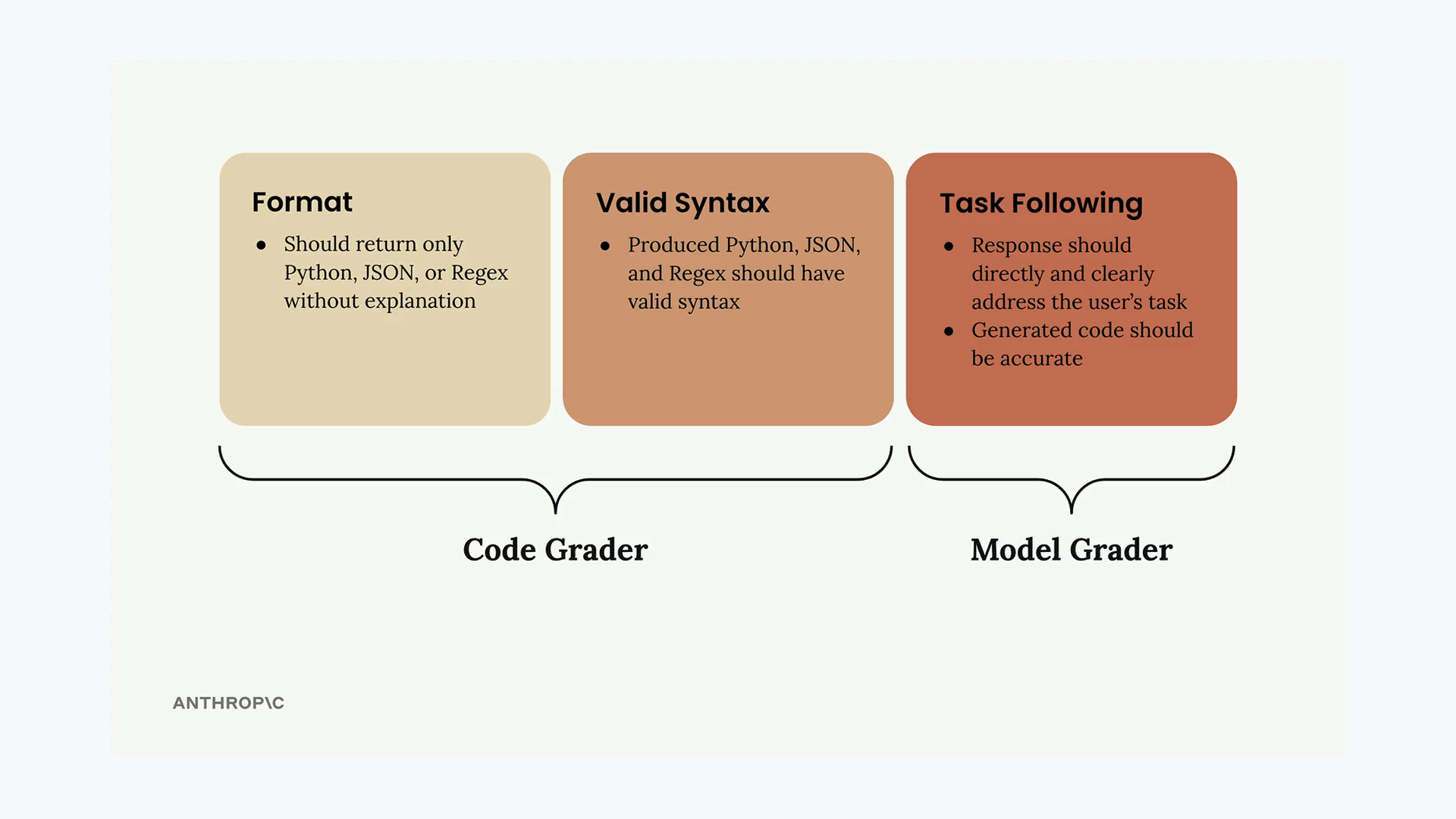
Hệ thống sử dụng các hàm kiểm chứng riêng biệt cho từng loại định dạng. Nếu mã nguồn được phân tích thành công, nó sẽ nhận điểm tối đa là 10. Nếu phân tích thất bại do lỗi, điểm sẽ là 0.
Thiết lập các hàm kiểm chứng (Validation Functions)
Bạn sẽ cần ba hàm bổ trợ để kiểm chứng các loại đầu ra khác nhau:
def validate_json(text):
try:
json.loads(text.strip())
return 10
except json.JSONDecodeError:
return 0
def validate_python(text):
try:
ast.parse(text.strip())
return 10
except SyntaxError:
return 0
def validate_regex(text):
try:
re.compile(text.strip())
return 10
except re.error:
return 0
Các hàm này sử dụng khả năng phân tích cú pháp có sẵn của Python để kiểm tra tính hợp lệ. Hàm json.loads() kiểm chứng JSON, ast.parse() tạo cây cú pháp trừu tượng (abstract syntax tree) cho Python, và re.compile() kiểm chứng biểu thức chính quy.
Thêm thông tin định dạng vào Test Case
Tập dữ liệu thử nghiệm (test dataset) của bạn cần chỉ định định dạng đầu ra mong đợi cho mỗi tác vụ. Hãy cập nhật prompt tạo tập dữ liệu để bao gồm trường định dạng:
{
"task": "Mô tả tác vụ",
"format": "python"
}
Trường định dạng nên chứa "json", "python", hoặc "regex" tùy thuộc vào loại đầu ra bạn mong đợi từ tác vụ cụ thể đó.
Cải thiện Prompt của bạn
Để có kết quả tốt hơn từ bộ chấm điểm mã nguồn, hãy làm cho các hướng dẫn trong prompt của bạn cụ thể hơn:
* Chỉ phản hồi bằng Python, JSON, hoặc Regex thuần túy
* Không thêm bất kỳ bình luận, chú giải hay giải thích nào
Bạn cũng có thể sử dụng tin nhắn phản hồi được điền sẵn (pre-filled assistant message) với các khối mã và stop sequences để đảm bảo định dạng đầu ra sạch sẽ.
Kết hợp các điểm số
Bước cuối cùng là kết hợp điểm từ bộ chấm điểm bằng mô hình (model grader) với điểm từ bộ chấm điểm cú pháp (syntax grader). Một cách tiếp cận đơn giản là lấy trung bình cộng của cả hai điểm:
model_grade = grade_by_model(test_case, output)
model_score = model_grade["score"]
syntax_score = grade_syntax(output, test_case)
score = (model_score + syntax_score) / 2
Cách này gán trọng số ngang nhau cho cả chất lượng nội dung (từ model grader) và tính chính xác kỹ thuật (từ code grader). Bạn có thể điều chỉnh trọng số này dựa trên yếu tố nào quan trọng hơn đối với trường hợp sử dụng cụ thể của mình.
Diễn giải kết quả
Khi bạn chạy eval, bạn sẽ nhận được một điểm số tổng hợp phản ánh cả chất lượng ngữ nghĩa và tính chính xác kỹ thuật của mã nguồn được tạo ra. Hãy nhớ rằng một điểm số đơn lẻ khi đứng riêng lẻ sẽ không nói lên nhiều điều - giá trị thực sự nằm ở việc so sánh các điểm số khi bạn lặp lại (iterate) thiết kế prompt của mình.
Sử dụng điểm cơ sở (baseline) này để thử nghiệm các cải tiến prompt và xem liệu những thay đổi của bạn có thực sự dẫn đến việc tạo mã nguồn tốt hơn và đáng tin cậy hơn hay không.
🔁 Bài học liên quan
- Bài tiếp: Exercise on prompt evals
- Bài trước: Model based grading
- Cùng section: Overview of Claude Models · Accessing the API · Making a request
- Thuộc lộ trình: Path C
- Docs tham khảo: Glossary · Skills atlas · By use-case
📚 Nguồn & ghi nhận
- Bài học gốc Anthropic Academy: https://anthropic.skilljar.com/claude-in-amazon-bedrock/276735
- © 2025 Anthropic. Chỉ dùng cho mục đích giáo dục, fair-use.
- Crawl: 2026-04-23 · Chuẩn hoá: 2026-05-01