📖 Nội dung bài học
Tóm tắt
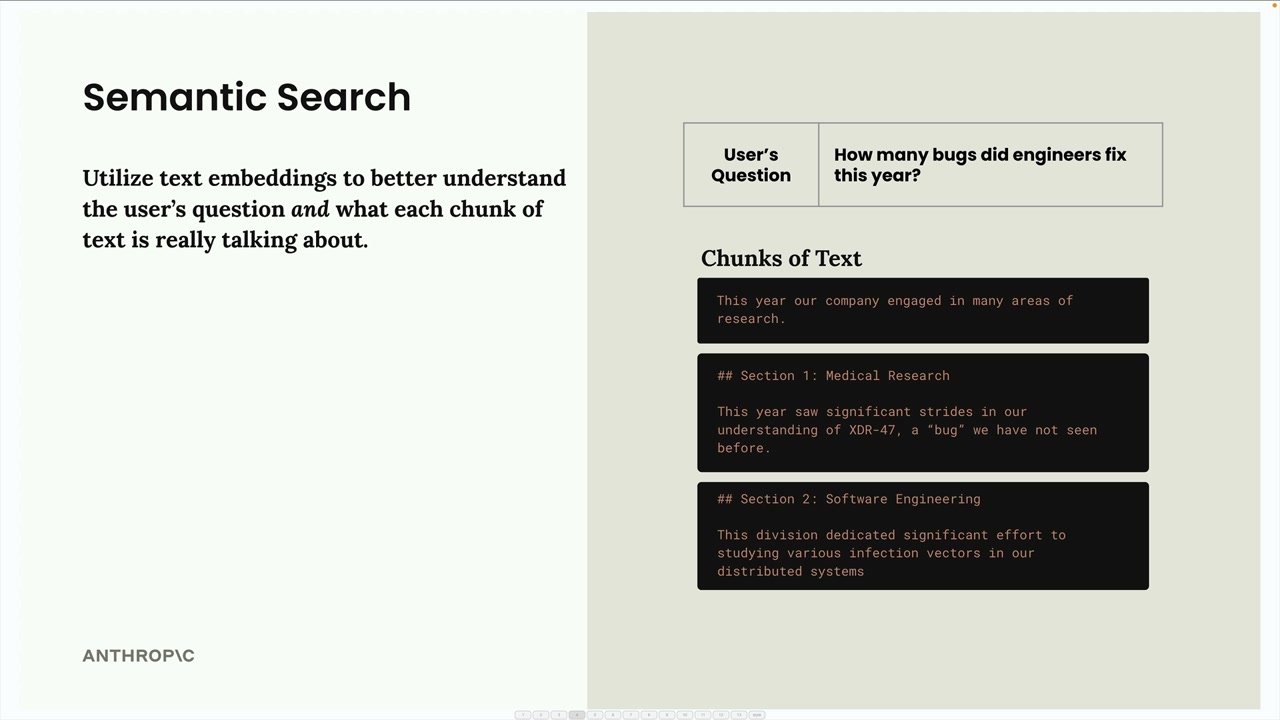
Sau khi chia tài liệu thành các đoạn (chunks), bước tiếp theo trong một RAG pipeline là tìm ra những đoạn nào liên quan nhất đến câu hỏi của người dùng. Về cơ bản, đây là một bài toán tìm kiếm - bạn cần xem qua tất cả các đoạn văn bản và xác định những đoạn liên quan đến điều người dùng đang hỏi.

Tìm kiếm ngữ nghĩa (Semantic Search)
Cách tiếp cận phổ biến nhất để tìm các đoạn liên quan là tìm kiếm ngữ nghĩa. Khác với tìm kiếm dựa trên từ khóa (keyword-based search) chỉ tìm các từ khớp chính xác, tìm kiếm ngữ nghĩa sử dụng text embeddings để hiểu ý nghĩa và ngữ cảnh của cả câu hỏi người dùng và từng đoạn văn bản.
Text Embeddings
Text embedding là một biểu diễn dạng số của ý nghĩa chứa trong một đoạn văn bản. Hãy coi nó như việc chuyển đổi từ và câu thành một định dạng mà máy tính có thể xử lý bằng toán học.
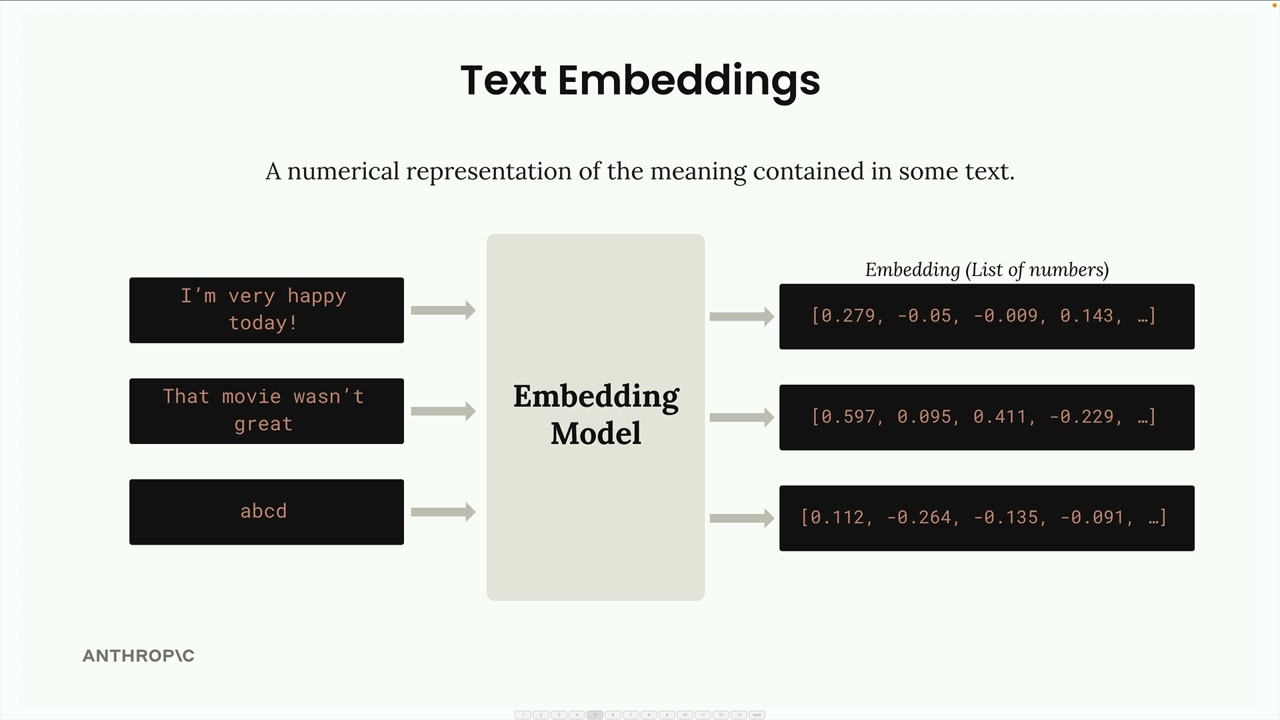
Quy trình hoạt động như sau:
- Bạn đưa văn bản vào một embedding model.
- Model trả về một danh sách dài các con số (embedding).
- Mỗi con số nằm trong khoảng từ -1 đến +1.
- Các con số này đại diện cho các đặc điểm hoặc thuộc tính khác nhau của văn bản đầu vào.
Hiểu về các con số
Mỗi con số trong một embedding thực chất là một "điểm số" cho một thuộc tính nào đó của văn bản đầu vào. Tuy nhiên, đây là lưu ý quan trọng: chúng ta không biết chính xác mỗi con số đại diện cho điều gì.
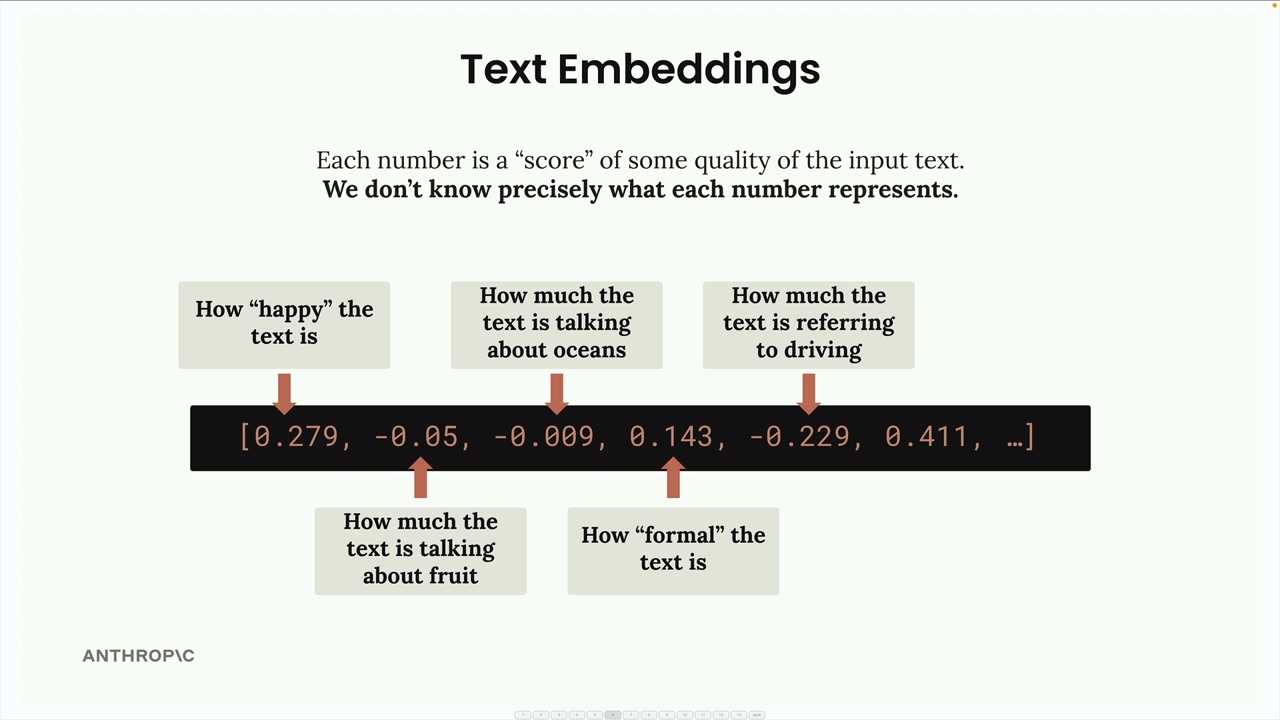
Mặc dù hữu ích khi hình dung rằng một con số có thể đại diện cho "mức độ vui vẻ của văn bản" hoặc "mức độ văn bản nói về đại dương", đây chỉ là các ví dụ mang tính khái niệm. Ý nghĩa thực tế của mỗi chiều (dimension) được model học trong quá trình huấn luyện và con người không thể diễn giải trực tiếp.
VoyageAI cho Embeddings
Vì Anthropic hiện không cung cấp chức năng tạo embedding, nhà cung cấp được đề xuất là VoyageAI. Bạn cần:
- Đăng ký một tài khoản VoyageAI riêng.
- Lấy API key (miễn phí để bắt đầu).
- Thêm key vào biến môi trường (environment variables).
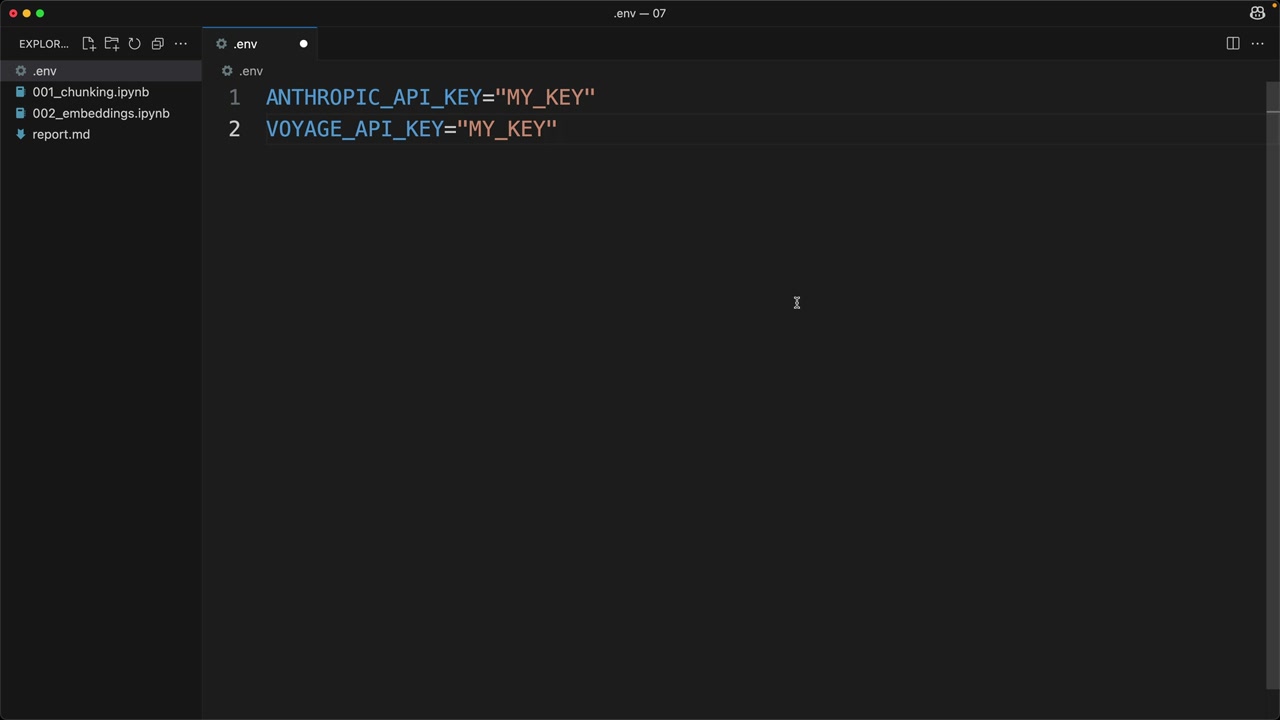
Trong tệp .env của bạn, thêm:
VOYAGE_API_KEY="your_key_here"
Triển khai
Đầu tiên, cài đặt thư viện VoyageAI:
%pip install voyageai
Sau đó thiết lập client và tạo một hàm để tạo embeddings:
from dotenv import load_dotenv
import voyageai
load_dotenv()
client = voyageai.Client()
def generate_embedding(text, model="voyage-3-large", input_type="query"):
result = client.embed([text], model=model, input_type=input_type)
return result.embeddings[0]
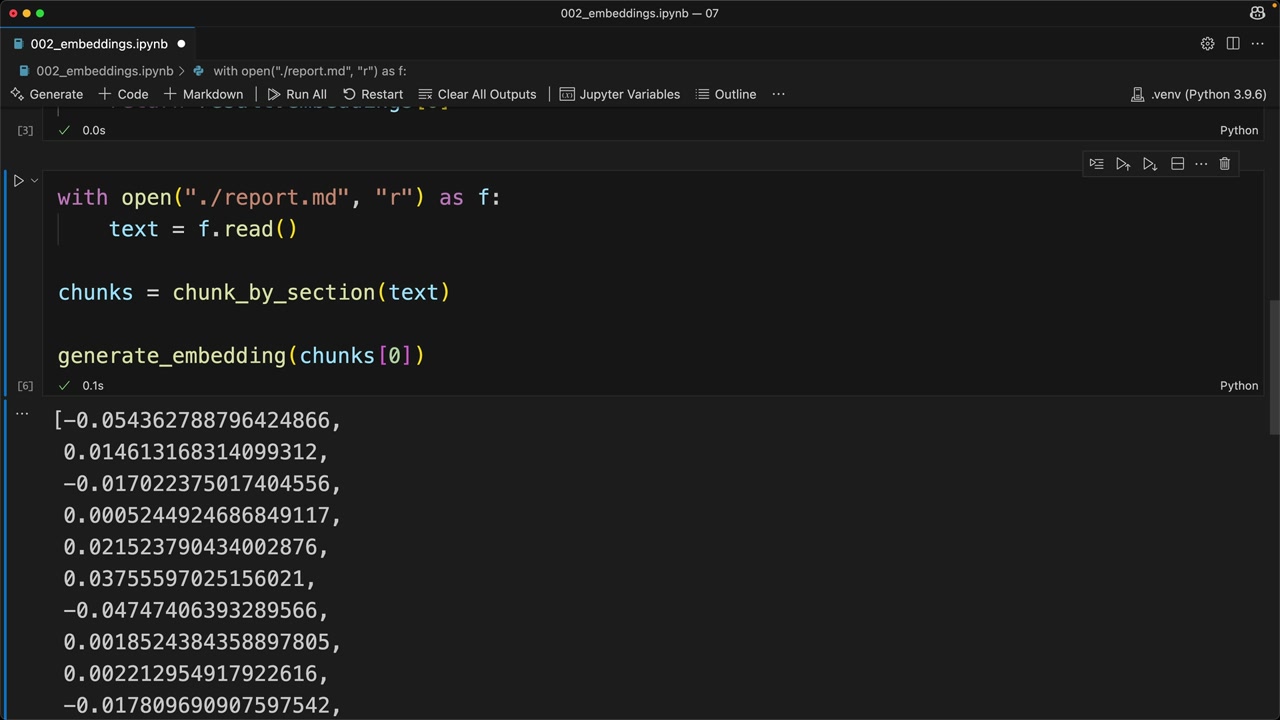
Khi bạn chạy hàm này trên một đoạn văn bản, bạn sẽ nhận lại một danh sách các số thực đại diện cho embedding. Quá trình này nhanh chóng và đơn giản - thách thức thực sự là hiểu cách sử dụng hiệu quả các embeddings này trong RAG pipeline của bạn để tìm nội dung liên quan nhất.
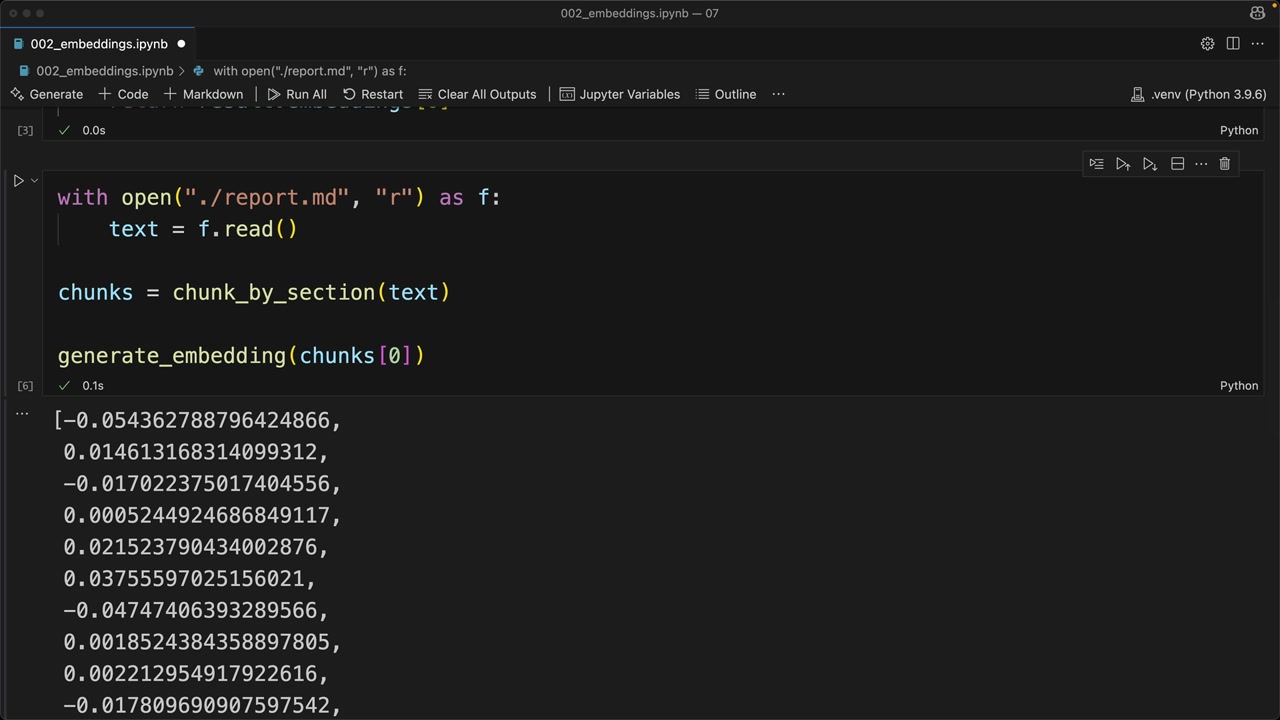
Bước tiếp theo là học cách so sánh các embeddings để xác định đoạn nào giống nhất với câu hỏi của người dùng, điều này tạo nên cốt lõi của quá trình tìm kiếm ngữ nghĩa.
Downloads
🔁 Bài học liên quan
- Bài tiếp: The full RAG flow
- Bài trước: Text chunking strategies
- Cùng section: Making a request · Multi-Turn conversations · Chat exercise
- Thuộc lộ trình: Path C
- Docs tham khảo: Glossary · Skills atlas · By use-case
📚 Nguồn & ghi nhận
- Bài học gốc Anthropic Academy: https://anthropic.skilljar.com/claude-with-the-anthropic-api/287759
- © 2025 Anthropic. Chỉ dùng cho mục đích giáo dục, fair-use.
- Crawl: — · Chuẩn hoá: 2026-05-01