📖 Nội dung bài học
Lùi← Họ phông chữ
Tóm tắt
Chia nhỏ văn bản là một trong những bước quan trọng nhất trong việc xây dựng một pipeline RAG (Retrieval Augmented Generation). Cách bạn chia nhỏ tài liệu ảnh hưởng trực tiếp đến chất lượng của toàn bộ hệ thống. Một chiến lược chia nhỏ kém có thể dẫn đến việc đưa ngữ cảnh không liên quan vào prompt của bạn, khiến AI của bạn đưa ra câu trả lời hoàn toàn sai.

Hãy xem xét ví dụ này: bạn có một tài liệu với các phần về nghiên cứu y học và kỹ thuật phần mềm. Nếu bạn chia nhỏ kém, một người dùng hỏi "Các kỹ sư đã sửa bao nhiêu lỗi trong năm nay?" có thể nhận được thông tin về nghiên cứu y học thay vì kỹ thuật phần mềm, chỉ vì phần y tế có chứa từ "bug" trong một ngữ cảnh khác.
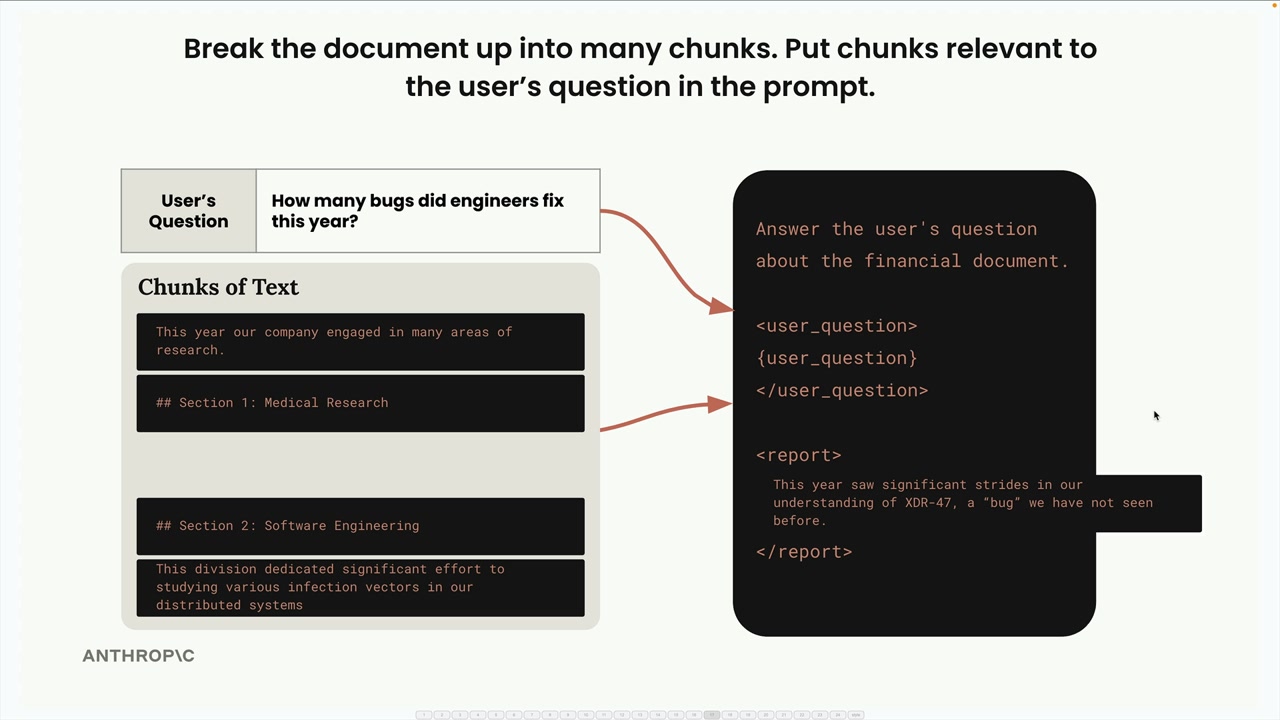
Đây là lý do tại sao việc chọn đúng chiến lược chia nhỏ lại quan trọng đến vậy. Hãy cùng khám phá ba phương pháp chính.
Chia nhỏ dựa trên kích thước
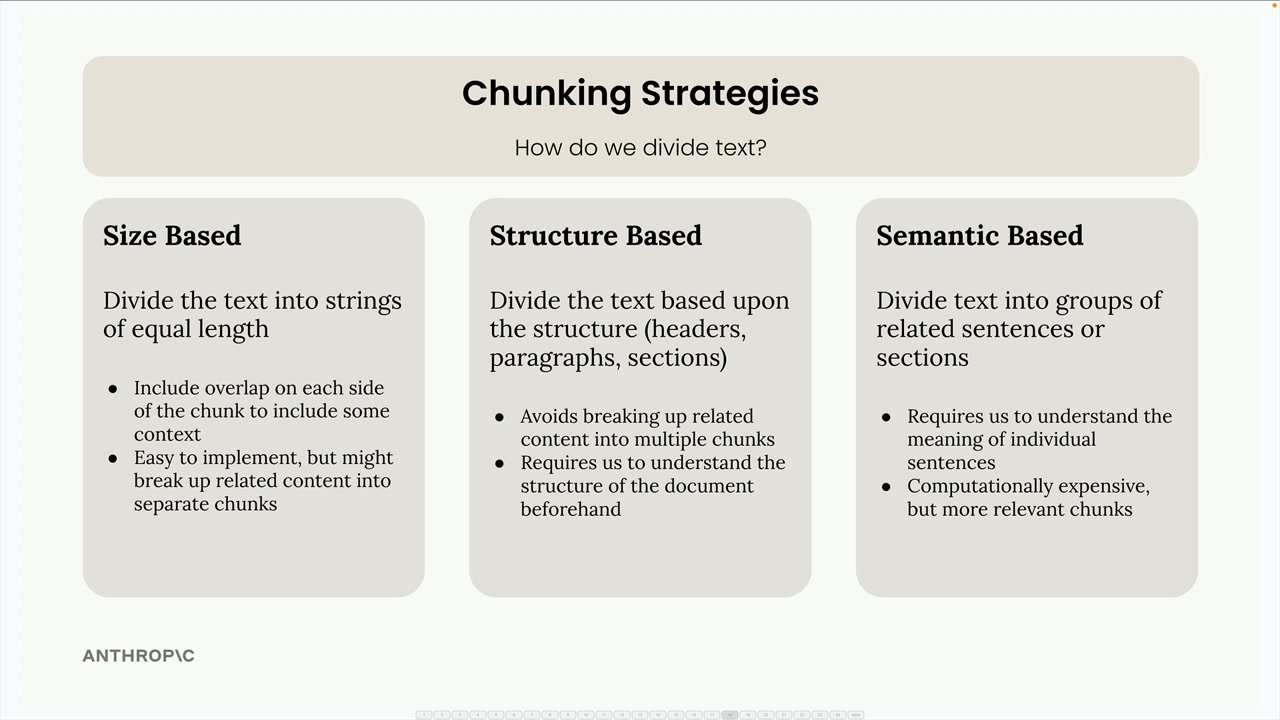
Chia nhỏ dựa trên kích thước là phương pháp đơn giản nhất - bạn chia văn bản của mình thành các chuỗi có độ dài bằng nhau. Nếu bạn có một tài liệu 325 ký tự, bạn có thể chia nó thành ba phần, mỗi phần khoảng 108 ký tự.

Phương pháp này dễ thực hiện và hoạt động với bất kỳ loại tài liệu nào, nhưng nó có những nhược điểm rõ ràng:
- Các từ bị cắt giữa câu
- Các phần bị mất ngữ cảnh quan trọng từ văn bản xung quanh
- Tiêu đề phần có thể bị tách khỏi nội dung của chúng

Để giải quyết những vấn đề này, bạn có thể thêm sự chồng chéo giữa các phần. Điều này có nghĩa là mỗi phần bao gồm một số ký tự từ các phần lân cận, cung cấp ngữ cảnh tốt hơn và đảm bảo các từ và câu hoàn chỉnh.
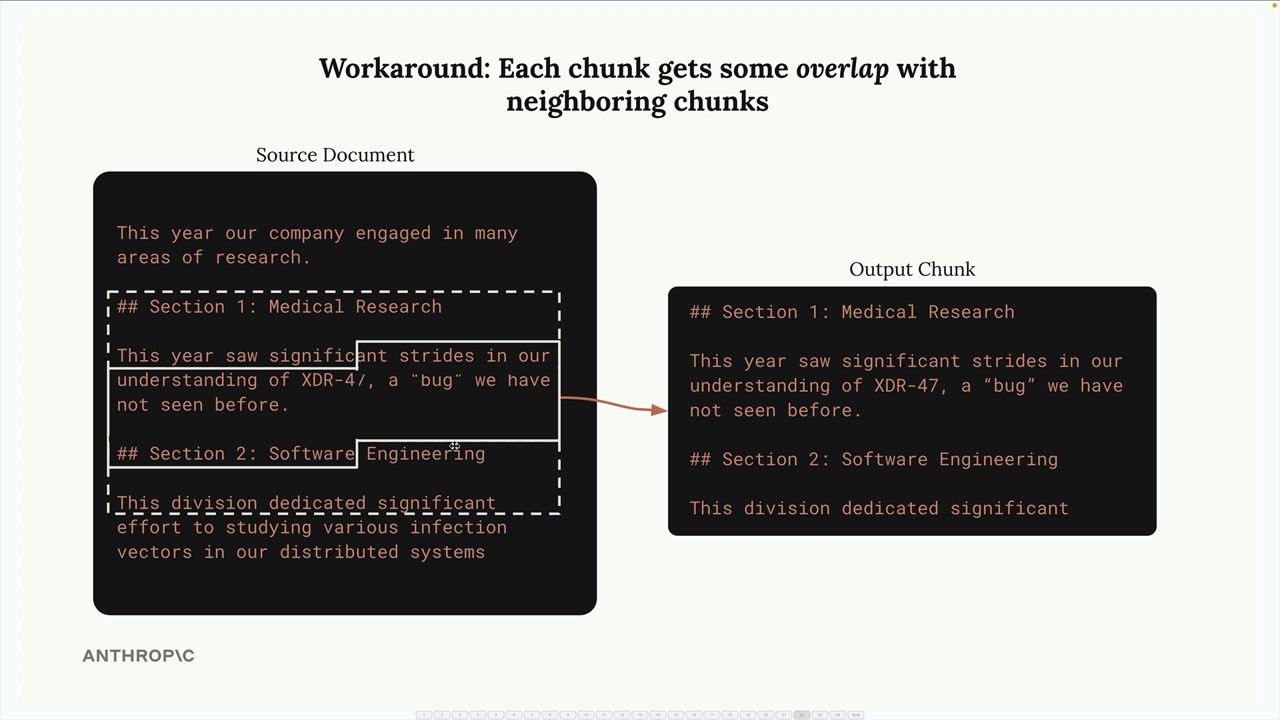
Đây là một triển khai cơ bản:
def chunk_by_char(text, chunk_size=150, chunk_overlap=20):
chunks = []
start_idx = 0
while start_idx < len(text):
end_idx = min(start_idx + chunk_size, len(text))
chunk_text = text[start_idx:end_idx]
chunks.append(chunk_text)
start_idx = (
end_idx - chunk_overlap if end_idx < len(text) else len(text)
)
return chunks
Chia nhỏ dựa trên cấu trúc
Chia nhỏ dựa trên cấu trúc chia văn bản dựa trên cấu trúc tự nhiên của tài liệu - tiêu đề, đoạn văn và phần. Điều này hoạt động rất tốt khi bạn có các tài liệu được định dạng tốt như các tệp Markdown.
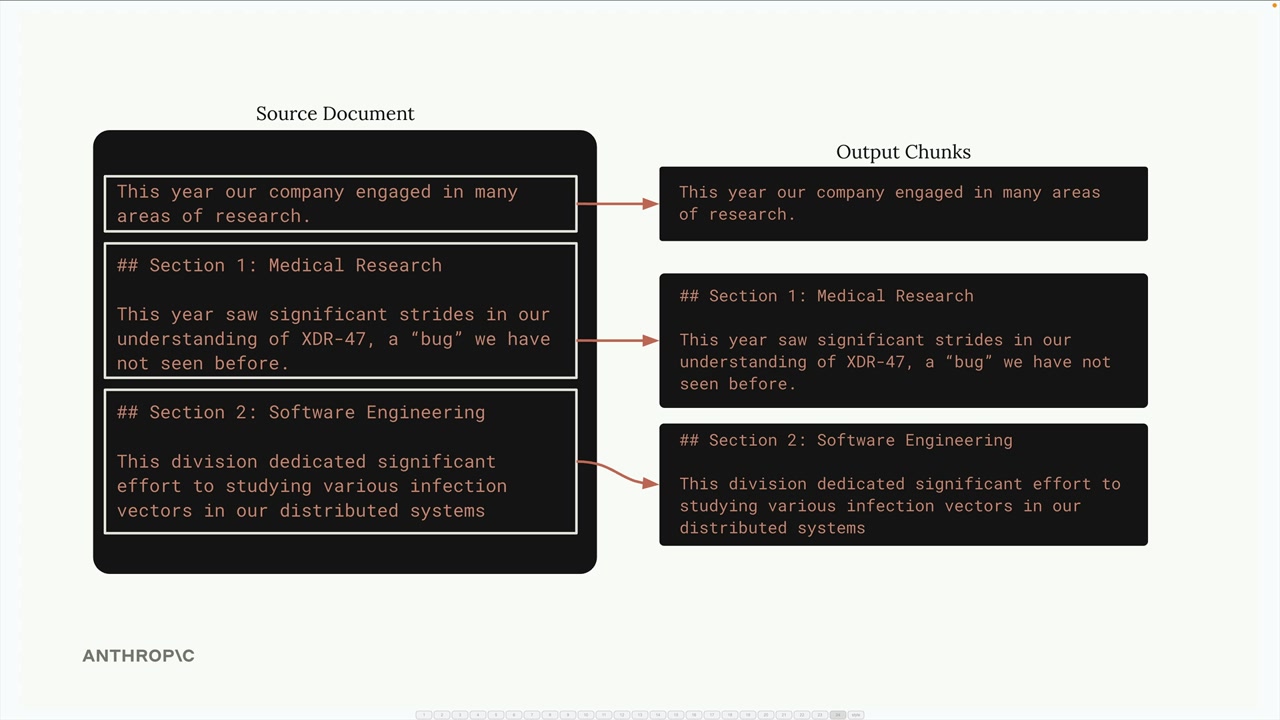
Đối với một tài liệu Markdown, bạn có thể chia theo các dấu hiệu tiêu đề:
def chunk_by_section(document_text):
pattern = r"\n## "
return re.split(pattern, document_text)
Phương pháp này cung cấp cho bạn các phần rõ ràng và có ý nghĩa nhất vì mỗi phần đại diện cho một phần hoàn chỉnh. Tuy nhiên, nó chỉ hoạt động khi bạn có đảm bảo về cấu trúc tài liệu của mình. Nhiều tài liệu trong thế giới thực là văn bản thuần túy hoặc PDF mà không có các dấu hiệu cấu trúc rõ ràng.
Chia nhỏ dựa trên ngữ nghĩa
Chia nhỏ dựa trên ngữ nghĩa là phương pháp tinh vi nhất. Bạn chia văn bản thành các câu, sau đó dùng xử lý ngôn ngữ tự nhiên để xác định mức độ liên quan của các câu liên tiếp. Bạn xây dựng các phần từ các nhóm câu có liên quan.
Phương pháp này tốn kém về mặt tính toán nhưng tạo ra các phần phù hợp nhất. Nó đòi hỏi phải hiểu ý nghĩa của từng câu và phức tạp hơn để thực hiện so với các chiến lược khác.
Chia nhỏ dựa trên câu
Một giải pháp trung gian thiết thực là chia nhỏ theo câu. Bạn chia văn bản thành các câu riêng lẻ bằng cách dùng regular expression, sau đó nhóm chúng thành các phần với sự chồng chéo tùy chọn:
def chunk_by_sentence(text, max_sentences_per_chunk=5, overlap_sentences=1):
sentences = re.split(r"(?<=[.!?])\s+", text)
chunks = []
start_idx = 0
while start_idx < len(sentences):
end_idx = min(start_idx + max_sentences_per_chunk, len(sentences))
current_chunk = sentences[start_idx:end_idx]
chunks.append(" ".join(current_chunk))
start_idx += max_sentences_per_chunk - overlap_sentences
if start_idx < 0:
start_idx = 0
return chunks
Chọn chiến lược của bạn
Sự lựa chọn của bạn hoàn toàn phụ thuộc vào trường hợp sử dụng và đảm bảo tài liệu của bạn:
- Dựa trên cấu trúc: Kết quả tốt nhất khi bạn kiểm soát định dạng tài liệu (như báo cáo nội bộ công ty)
- Dựa trên câu: Giải pháp trung gian tốt cho hầu hết các tài liệu văn bản
- Dựa trên kích thước: Giải pháp dự phòng đáng tin cậy nhất hoạt động với mọi loại nội dung, bao gồm cả code
Chia nhỏ dựa trên kích thước với sự chồng chéo thường là lựa chọn mặc định trong sản xuất vì nó đơn giản, đáng tin cậy và hoạt động với mọi loại tài liệu. Mặc dù nó có thể không mang lại kết quả hoàn hảo, nhưng nó luôn tạo ra các phần hợp lý sẽ không phá vỡ pipeline của bạn.
Hãy nhớ: không có một chiến lược chia nhỏ "tốt nhất" duy nhất. Cách tiếp cận phù hợp phụ thuộc vào tài liệu cụ thể của bạn, các trường hợp sử dụng và sự đánh đổi mà bạn sẵn sàng thực hiện giữa độ phức tạp của việc triển khai và chất lượng của phần.
Tải xuống
🔁 Bài học liên quan
- Bài tiếp: Text embeddings
- Bài trước: Introducing Retrieval Augmented Generation
- Cùng section: Making a request · Multi-Turn conversations · Chat exercise
- Thuộc lộ trình: Path C
- Docs tham khảo: Glossary · Skills atlas · By use-case
📚 Nguồn & ghi nhận
- Bài học gốc Anthropic Academy: https://anthropic.skilljar.com/claude-with-the-anthropic-api/287776
- © 2025 Anthropic. Chỉ dùng cho mục đích giáo dục, fair-use.
- Crawl: 2026-04-23 · Chuẩn hoá: 2026-05-01