📖 Nội dung bài học
Tóm tắt
Khi xây dựng quy trình đánh giá prompt (evaluation workflows), các hệ thống chấm điểm cung cấp tín hiệu khách quan về chất lượng đầu ra. Một bộ chấm điểm (grader) nhận đầu ra của mô hình và trả về một loại phản hồi có thể đo lường được - thường là một con số từ 1 đến 10, trong đó 10 đại diện cho chất lượng cao và 1 đại diện cho chất lượng kém.
Các loại bộ chấm điểm (Graders)
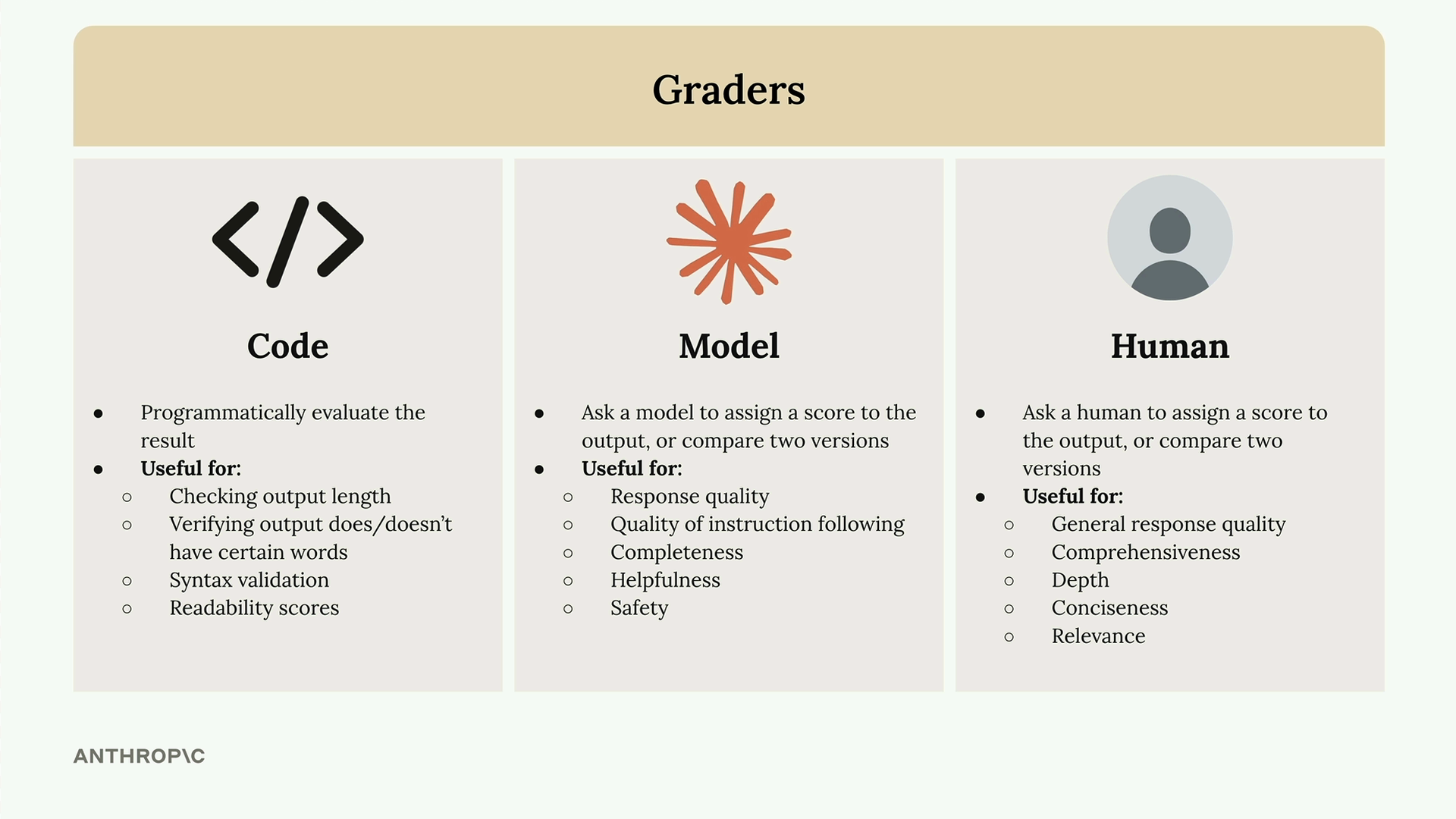
Có ba phương pháp chính để chấm điểm đầu ra của mô hình:
- Bộ chấm điểm bằng mã nguồn (Code graders) - Đánh giá đầu ra bằng lập trình bằng các logic tùy chỉnh.
- Bộ chấm điểm bằng mô hình (Model graders) - Sử dụng một mô hình AI khác để đánh giá chất lượng.
- Bộ chấm điểm bằng con người (Human graders) - Để con người xem xét và chấm điểm đầu ra một cách thủ công.
Bộ chấm điểm bằng mã nguồn (Code Graders)
Code graders cho phép bạn triển khai bất kỳ hình thức kiểm tra lập trình nào mà bạn có thể nghĩ ra. Các công dụng phổ biến bao gồm:
- Kiểm tra độ dài đầu ra.
- Xác minh đầu ra có hoặc không có các từ nhất định.
- Xác thực cú pháp (syntax validation) cho JSON, Python hoặc regex.
- Điểm số khả năng đọc (readability scores).
Yêu cầu duy nhất là mã nguồn của bạn phải trả về một tín hiệu hữu dụng - thường là một con số từ 1 đến 10.
Bộ chấm điểm bằng mô hình (Model Graders)
Model graders đưa đầu ra gốc của bạn vào một lệnh gọi API khác để đánh giá. Phương pháp này mang lại sự linh hoạt to lớn để đánh giá:
- Chất lượng phản hồi.
- Chất lượng của việc tuân thủ chỉ dẫn (instruction following).
- Tính đầy đủ.
- Tính hữu ích.
- Độ an toàn (safety).
Bộ chấm điểm bằng con người (Human Graders)
Human graders mang lại sự linh hoạt cao nhất nhưng lại tốn thời gian và nhàm chán. Chúng hữu ích để đánh giá:
- Chất lượng phản hồi chung.
- Tính toàn diện.
- Độ sâu.
- Tính súc tích.
- Tính liên quan.
Định nghĩa tiêu chí đánh giá

Trước khi triển khai bất kỳ bộ chấm điểm nào, bạn cần có các tiêu chí đánh giá rõ ràng. Đối với một prompt tạo mã nguồn, bạn có thể tập trung vào:
- Định dạng (Format) - Chỉ nên trả về Python, JSON hoặc Regex mà không kèm theo giải thích.
- Cú pháp hợp lệ (Valid Syntax) - Mã nguồn được tạo ra phải có cú pháp hợp lệ.
- Tuân thủ yêu cầu (Task Following) - Phản hồi phải trực tiếp giải quyết tác vụ của người dùng với mã nguồn chính xác.
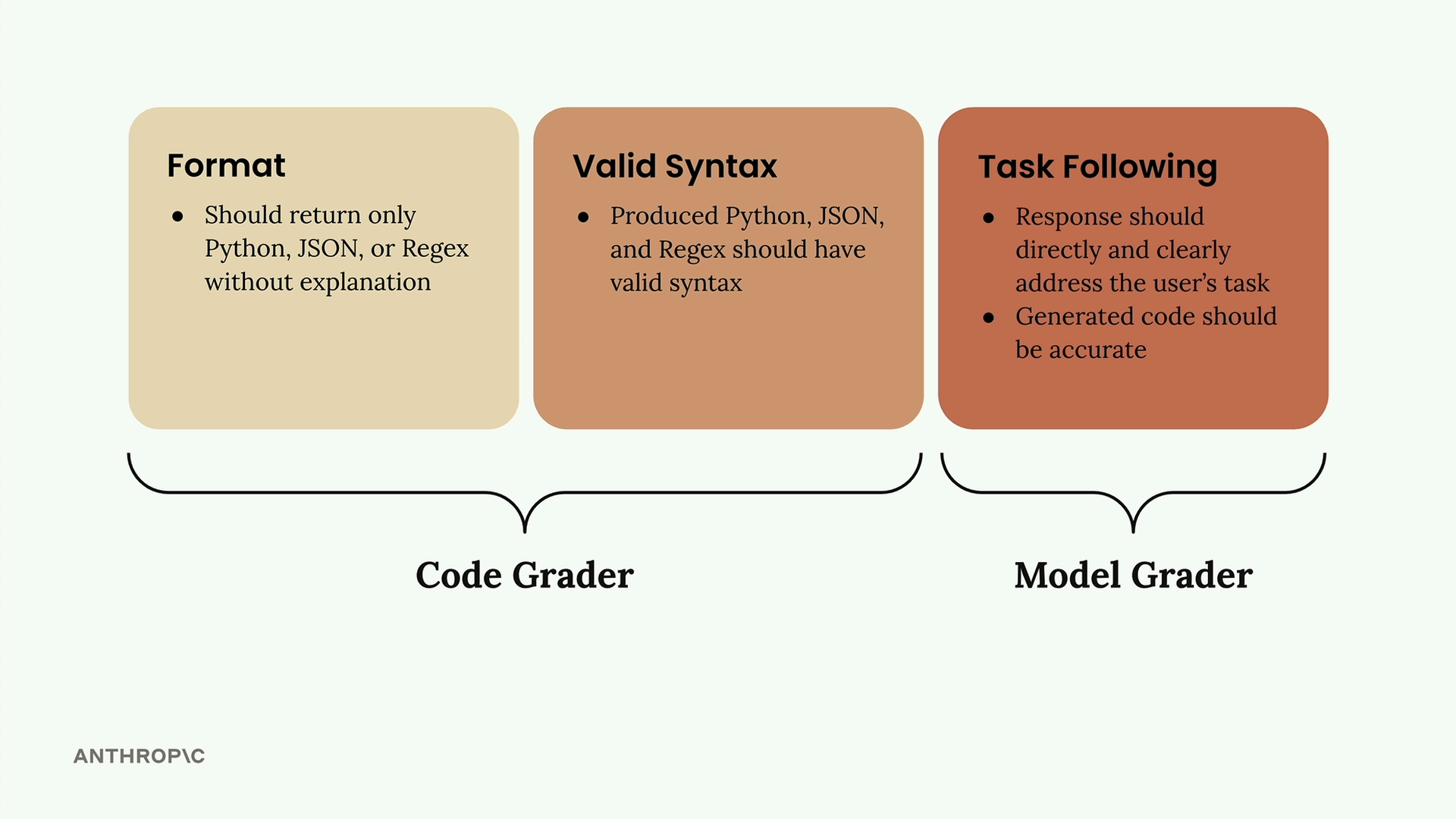
Hai tiêu chí đầu tiên hoạt động tốt với code graders, trong khi việc tuân thủ yêu cầu sẽ phù hợp hơn với model graders nhờ tính linh hoạt của chúng.
Triển khai một Model Grader
Dưới đây là cách xây dựng một hàm model grader:
def grade_by_model(test_case, output):
# Tạo prompt đánh giá
eval_prompt = """
You are an expert code reviewer. Evaluate this AI-generated solution.
Task: {task}
Solution: {solution}
Provide your evaluation as a structured JSON object with:
- "strengths": An array of 1-3 key strengths
- "weaknesses": An array of 1-3 key areas for improvement
- "reasoning": A concise explanation of your assessment
- "score": A number between 1-10
"""
messages = []
add_user_message(messages, eval_prompt)
add_assistant_message(messages, "```json")
eval_text = chat(messages, stop_sequences=["```"])
return json.loads(eval_text)
Điểm mấu chốt là yêu cầu mô hình nêu rõ điểm mạnh, điểm yếu và lập luận bên cạnh điểm số. Nếu không có ngữ cảnh này, các mô hình thường có xu hướng đưa ra mức điểm trung bình khoảng 6.
Tích hợp chấm điểm vào quy trình làm việc
Cập nhật trình chạy test case của bạn để gọi bộ chấm điểm:
def run_test_case(test_case):
output = run_prompt(test_case)
# Chấm điểm đầu ra
model_grade = grade_by_model(test_case, output)
score = model_grade["score"]
reasoning = model_grade["reasoning"]
return {
"output": output,
"test_case": test_case,
"score": score,
"reasoning": reasoning
}
Cuối cùng, tính điểm trung bình trên tất cả các test case:
from statistics import mean
def run_eval(dataset):
results = []
for test_case in dataset:
result = run_test_case(test_case)
results.append(result)
average_score = mean([result["score"] for result in results])
print(f"Average score: {average_score}")
return results
Điều này cung cấp cho bạn một chỉ số khách quan để theo dõi khi bạn tinh chỉnh prompt của mình. Mặc dù các model graders đôi khi có thể hơi thất thường, chúng vẫn cung cấp một mốc cơ sở (baseline) nhất quán để đo lường sự cải thiện.
Tải xuống
🔁 Bài học liên quan
- Bài tiếp: Code based grading
- Bài trước: Running the eval
- Cùng section: Making a request · Multi-Turn conversations · Chat exercise
- Thuộc lộ trình: Path C
- Docs tham khảo: Glossary · Skills atlas · By use-case
📚 Nguồn & ghi nhận
- Bài học gốc Anthropic Academy: https://anthropic.skilljar.com/claude-with-the-anthropic-api/287742
- © 2025 Anthropic. Chỉ dùng cho mục đích giáo dục, fair-use.
- Crawl: 2026-04-23 · Chuẩn hoá: 2026-05-01