📖 Nội dung bài học
Video này đang được xử lý. Vui lòng quay lại sau và tải lại trang.
Tóm tắt
Giờ chúng ta đã có tập dữ liệu đánh giá (evaluation dataset) sẵn sàng, đã đến lúc xây dựng quy trình đánh giá (evaluation pipeline) cốt lõi. Việc này bao gồm lấy từng test case, kết hợp với prompt, gửi cho Claude và sau đó chấm điểm kết quả.
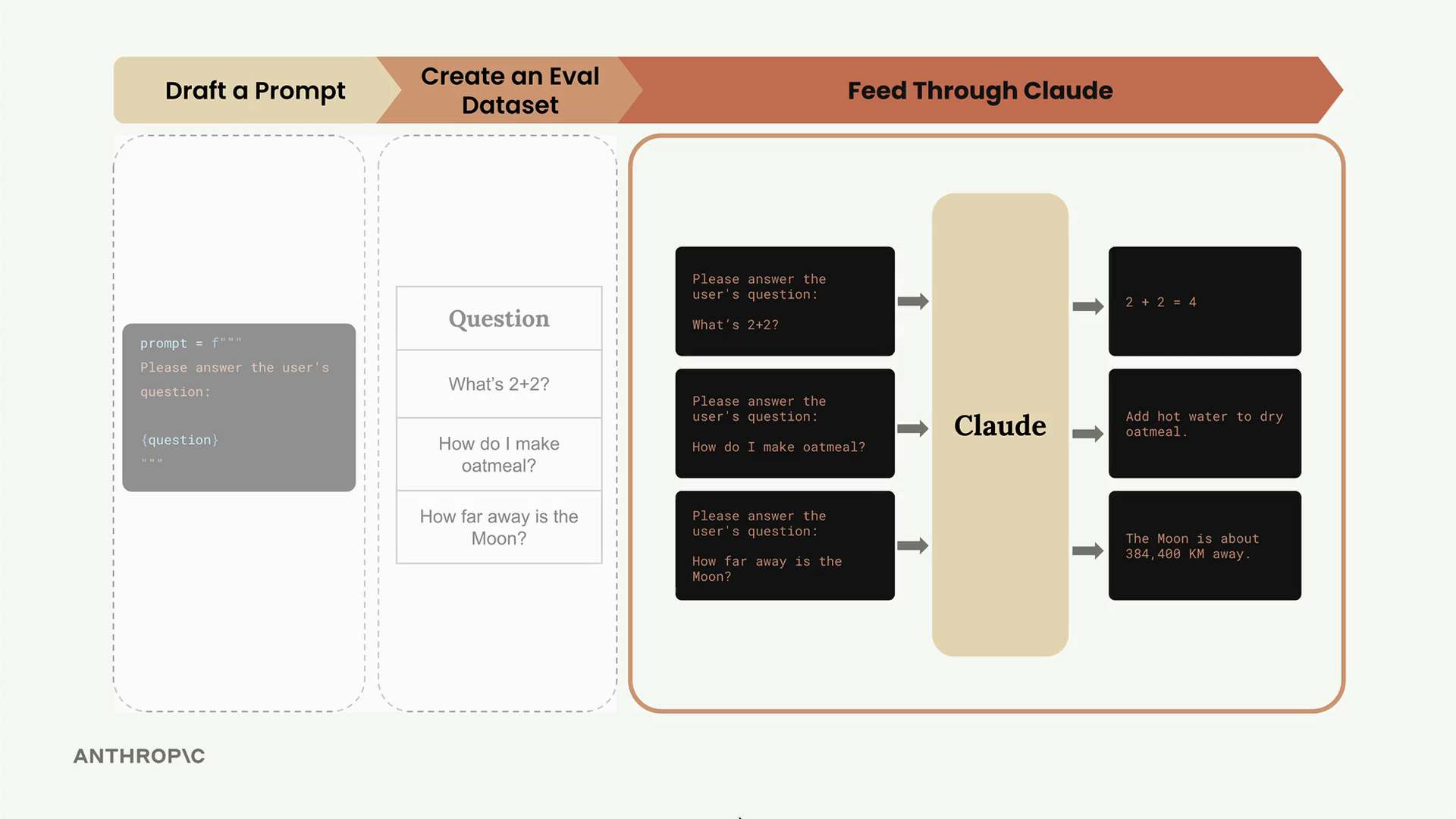
Quy trình eval tuân theo một luồng công việc rõ ràng: chúng ta lấy dataset gồm các test case, kết hợp từng cái với một mẫu prompt (prompt template), gửi cho Claude xử lý, và sau đó đánh giá đầu ra bằng một hệ thống chấm điểm (grader system).
Xây dựng các hàm cốt lõi
Quy trình eval bao gồm ba hàm chính, mỗi hàm có một trách nhiệm riêng. Hãy bắt đầu với hàm đơn giản nhất - hàm xử lý các prompt đơn lẻ.
Hàm run_prompt
Hàm này nhận một test case và kết hợp nó với mẫu prompt của chúng ta:
def run_prompt(test_case):
"""Trộn prompt và đầu vào test case, sau đó trả về kết quả"""
prompt = f"""
Please solve the following task:
{test_case["task"]}
"""
messages = []
add_user_message(messages, prompt)
output = chat(messages)
return output
Hiện tại, chúng ta đang giữ prompt cực kỳ đơn giản. Chúng ta không bao gồm bất kỳ hướng dẫn định dạng nào, vì vậy Claude có thể sẽ trả về kết quả dài dòng hơn mức cần thiết. Chúng ta sẽ tinh chỉnh việc này sau khi lặp lại thiết kế prompt.
Hàm run_test_case
Hàm này điều phối việc chạy một test case đơn lẻ và chấm điểm kết quả:
def run_test_case(test_case):
"""Gọi run_prompt, sau đó chấm điểm kết quả"""
output = run_prompt(test_case)
# TODO - Chấm điểm
score = 10
return {
"output": output,
"test_case": test_case,
"score": score
}
Hiện tại, chúng ta đang sử dụng một điểm số được gán cứng (hardcoded score) là 10. Logic chấm điểm là nơi chúng ta sẽ dành nhiều thời gian trong các phần sắp tới, nhưng phần giữ chỗ này cho phép chúng ta kiểm tra toàn bộ quy trình.
Hàm run_eval
Hàm này điều phối toàn bộ quá trình eval:
def run_eval(dataset):
"""Tải dataset và gọi run_test_case cho mỗi case"""
results = []
for test_case in dataset:
result = run_test_case(test_case)
results.append(result)
return results
Hàm này xử lý mọi test case trong dataset và thu thập tất cả kết quả vào một danh sách duy nhất.
Thực thi Evaluation
Để thực thi quy trình eval, chúng ta tải dataset và chạy nó thông qua các hàm đã viết:
with open("dataset.json", "r") as f:
dataset = json.load(f)
results = run_eval(dataset)
Lần đầu tiên bạn chạy lệnh này, hãy chuẩn bị tinh thần là nó sẽ mất một chút thời gian - ngay cả với Claude Haiku, có thể mất khoảng 30 giây để xử lý toàn bộ tập dữ liệu. Chúng ta sẽ tìm hiểu các kỹ thuật tối ưu hóa sau.
Kiểm tra kết quả
Quá trình eval trả về một mảng JSON có cấu trúc, trong đó mỗi đối tượng đại diện cho kết quả của một test case:
print(json.dumps(results, indent=2))
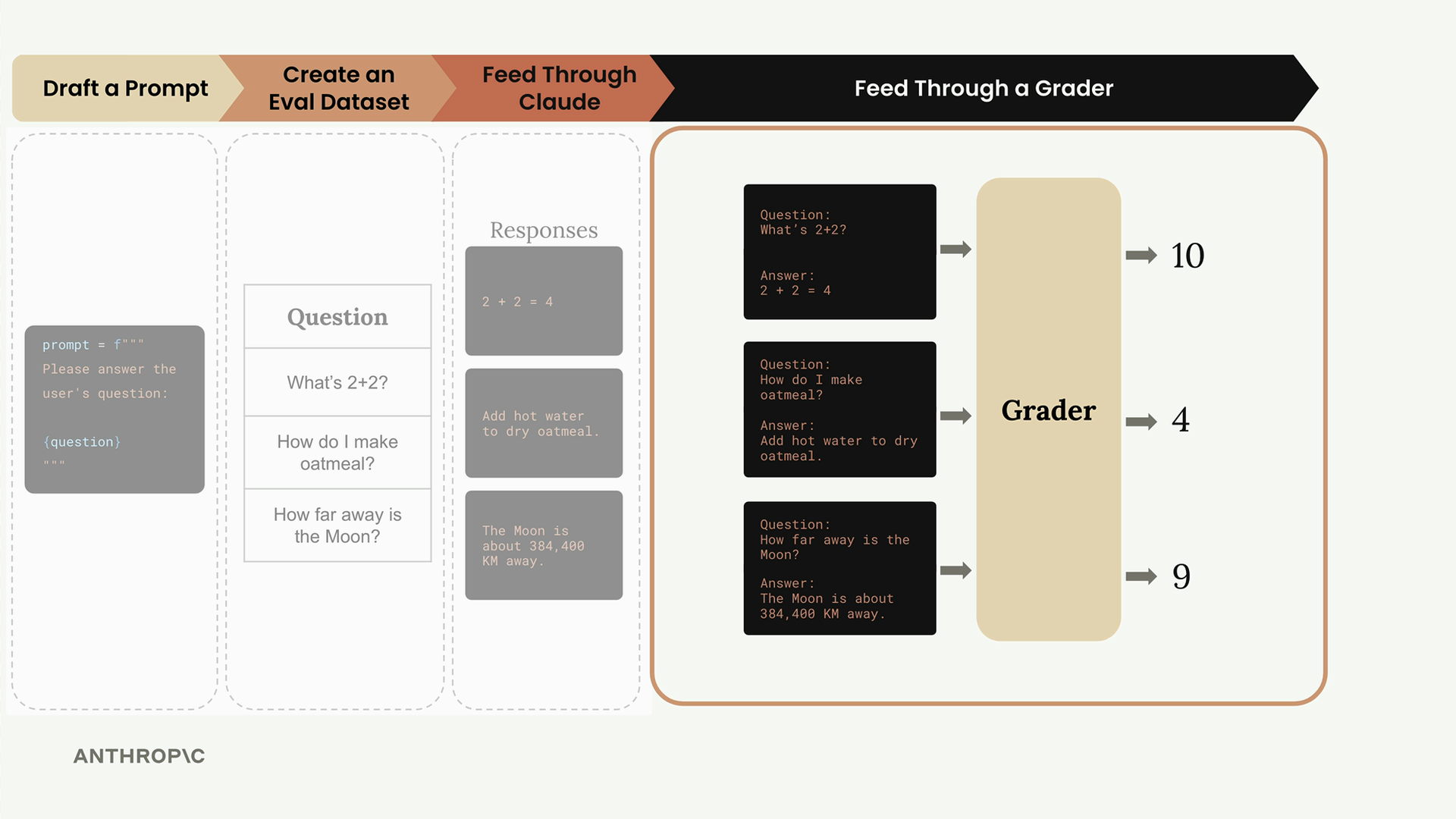
Mỗi kết quả chứa ba thông tin chính:
- output: Phản hồi đầy đủ từ Claude
- test_case: Test case gốc đã được xử lý
- score: Điểm đánh giá (hiện đang được gán cứng)
Như bạn có thể thấy trong kết quả đầu ra, Claude tạo ra các phản hồi khá dài dòng vì chúng ta chưa cung cấp hướng dẫn định dạng cụ thể. Đây chính xác là loại vấn đề chúng ta sẽ giải quyết khi tinh chỉnh prompt.
Những gì chúng ta đã đạt được
Đến thời điểm này, chúng ta đã xây dựng thành công quy trình eval cốt lõi. Chúng ta có thể lấy dataset, xử lý qua Claude và thu thập kết quả có cấu trúc. Mảnh ghép quan trọng còn thiếu là hệ thống chấm điểm - điểm số 10 gán cứng đó cần được thay thế bằng logic đánh giá thực tế.
Quy trình này đại diện cho nền tảng của hầu hết các hệ thống đánh giá AI. Dù có vẻ đơn giản, bạn vừa xây dựng xong phần lớn những gì một quy trình eval thực sự thực hiện. Sự phức tạp sẽ nằm ở các chi tiết - prompt tốt hơn, hệ thống chấm điểm tinh vi và tối ưu hóa hiệu suất.
Tiếp theo, chúng ta sẽ đi sâu vào chủ đề quan trọng về các bộ chấm điểm (grader), thứ sẽ biến các điểm số gán cứng của chúng ta thành những đánh giá có ý nghĩa về hiệu suất của Claude.
🔁 Bài học liên quan
- Bài tiếp: Model based grading
- Bài trước: Generating test datasets
- Cùng section: Making a request · Multi-Turn conversations · Chat exercise
- Thuộc lộ trình: Path C
- Docs tham khảo: Glossary · Skills atlas · By use-case
📚 Nguồn & ghi nhận
- Bài học gốc Anthropic Academy: https://anthropic.skilljar.com/claude-with-the-anthropic-api/287743
- © 2025 Anthropic. Chỉ dùng cho mục đích giáo dục, fair-use.
- Crawl: 2026-04-23 · Chuẩn hoá: 2026-05-01