📖 Lesson content
Summary
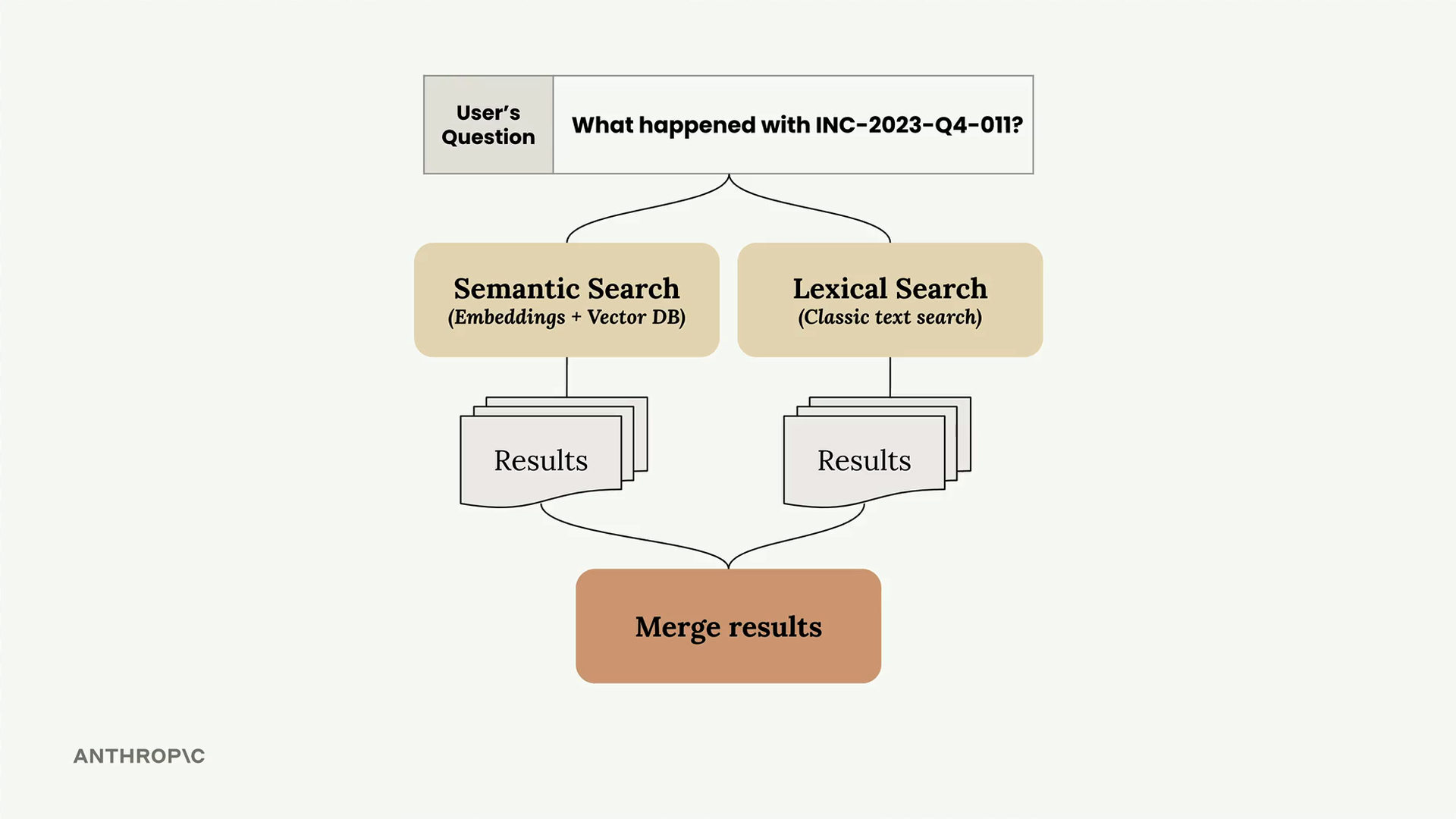
When you have both semantic search (vector embeddings) and lexical search (BM25) working independently, the next step is combining them into a unified search pipeline. This hybrid approach leverages the strengths of both methods to deliver more accurate results.
Building a Unified Interface
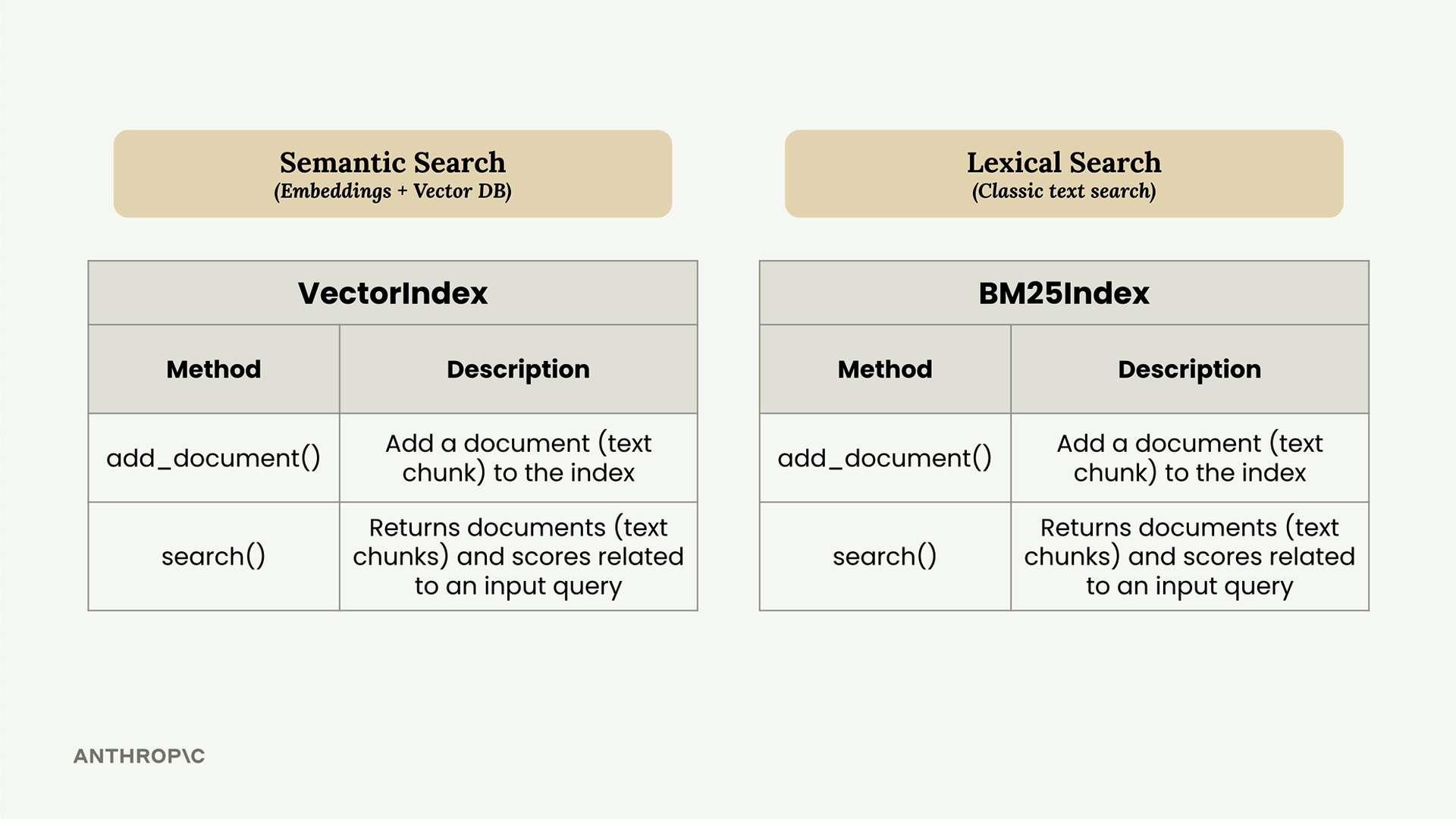
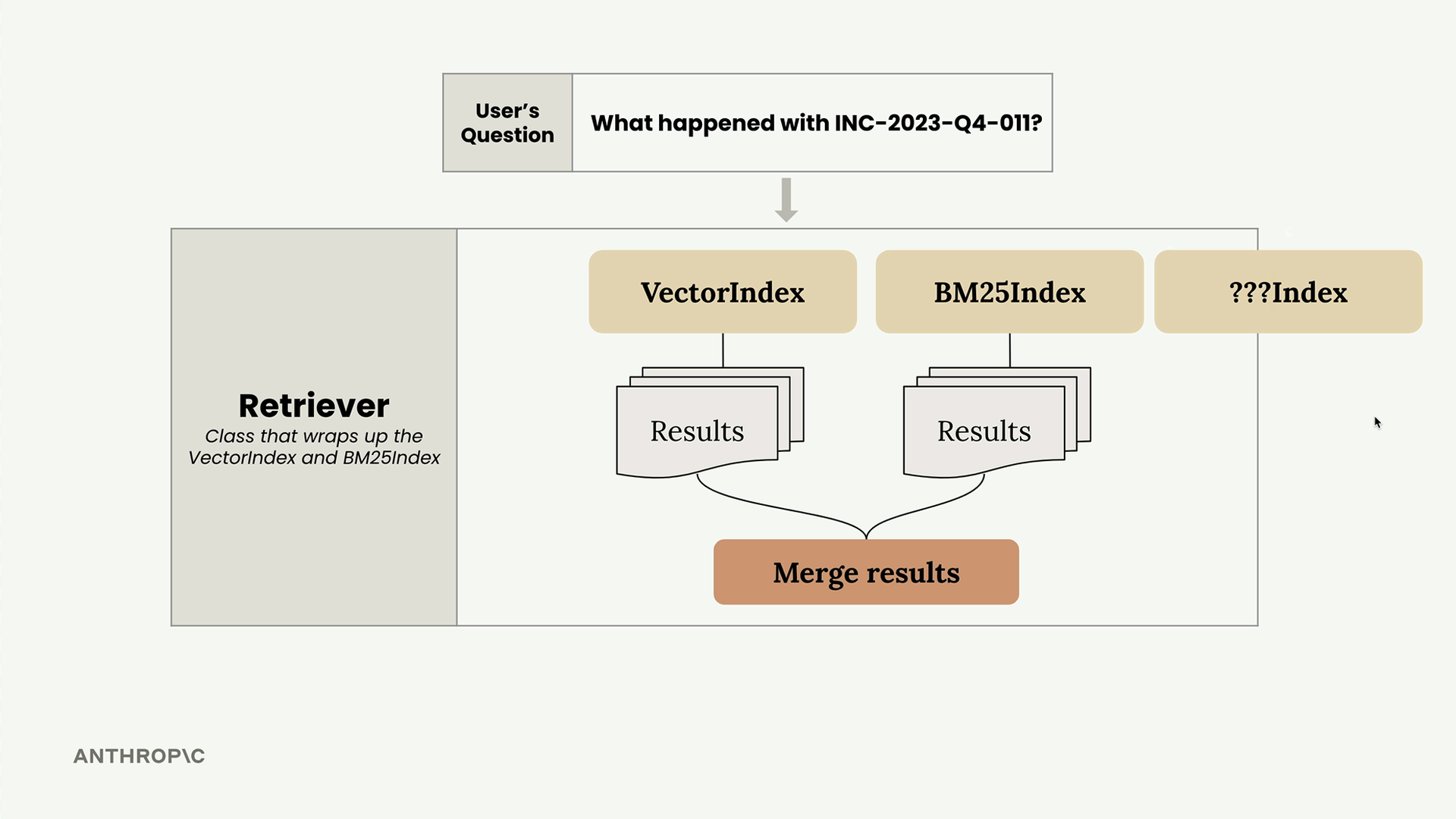
Both search implementations share nearly identical APIs - they both have add_document() and search() methods. This consistency makes it straightforward to wrap them in a single Retriever class that coordinates between the two approaches.
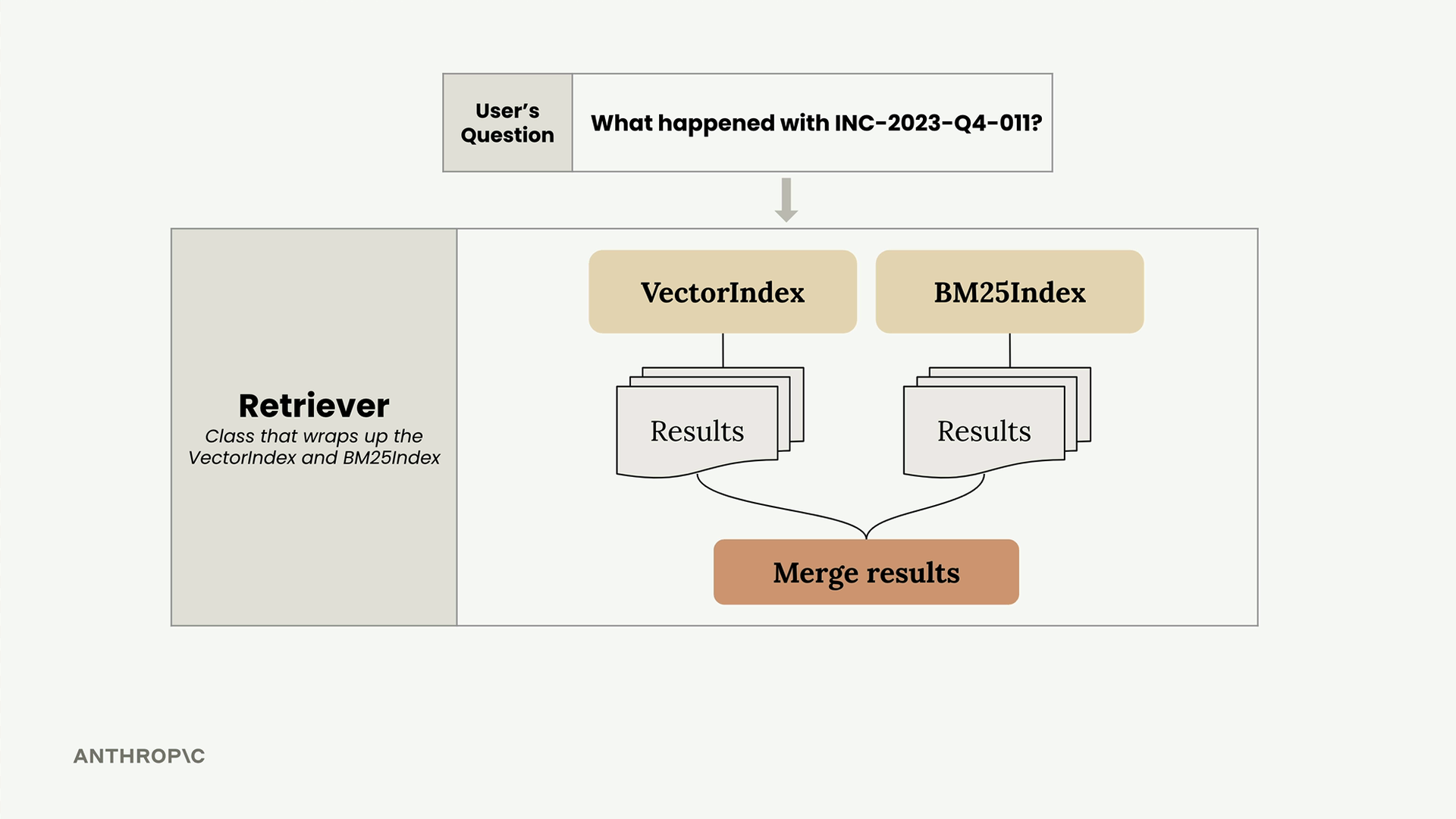
The Retriever acts as a coordinator that:
- Receives a user's question
- Forwards it to both the VectorIndex and BM25Index
- Collects results from both systems
- Merges the results using a ranking algorithm
Reciprocal Rank Fusion
The challenge lies in merging results from different search methods. Each system returns results with different scoring mechanisms, so you can't simply combine scores directly. Instead, we use a technique called Reciprocal Rank Fusion (RRF).
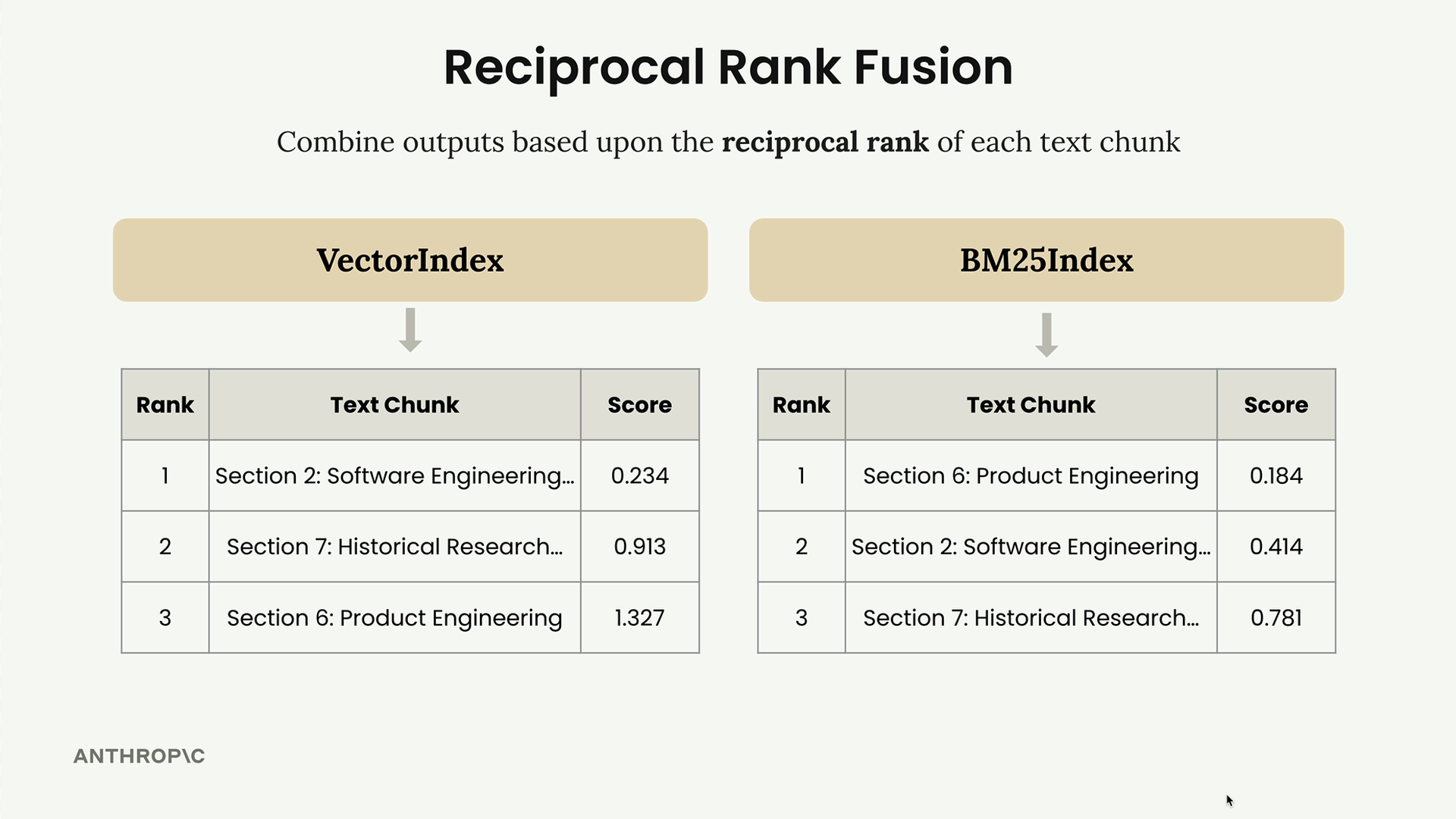
Here's how RRF works with a practical example. Suppose your VectorIndex returns results ranked as: Section 2, Section 7, Section 6. Meanwhile, your BM25Index returns: Section 6, Section 2, Section 7.
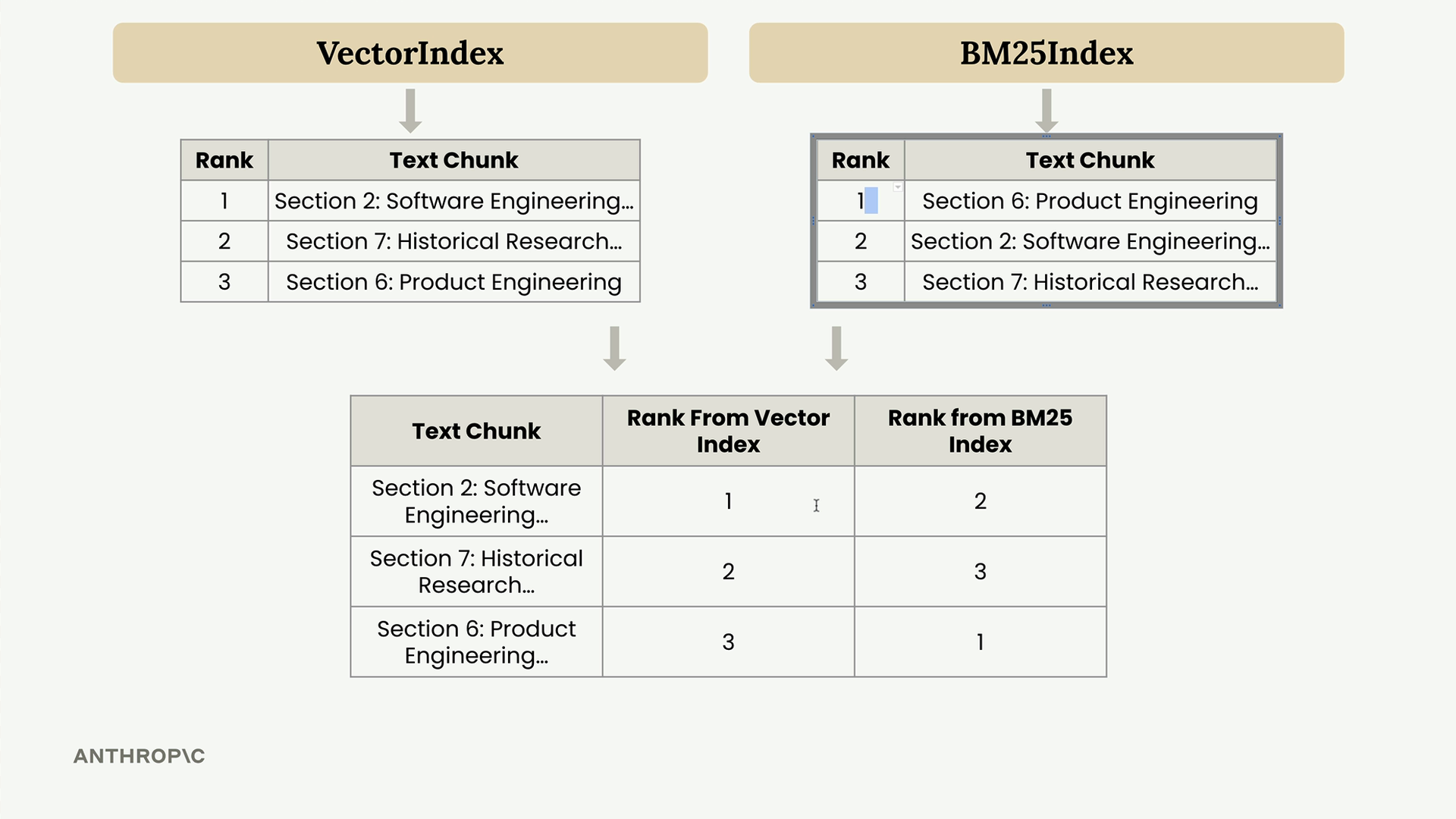
To merge these results, you create a combined table showing each text chunk's rank from both systems:

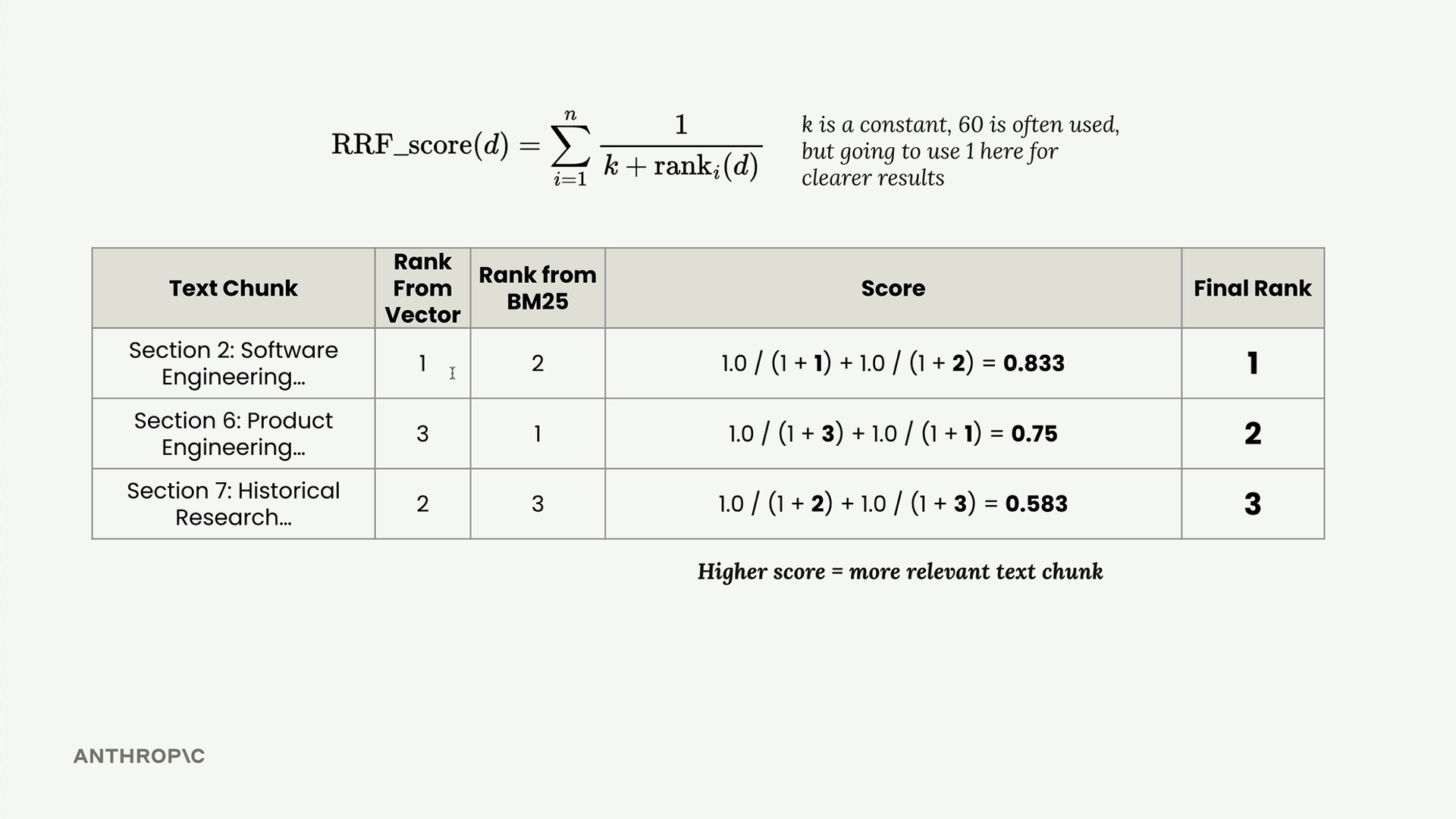
The RRF formula calculates a score for each document:
RRF_score(d) = Σ(1 / (k + rank_i(d)))
Where k is a constant (typically 60, though 1 works well for clearer results) and rank_i(d) is the rank of document d in the i-th ranking system.

For each text chunk, you calculate:
- Section 2: 1.0/(1+1) + 1.0/(1+2) = 0.833
- Section 7: 1.0/(1+2) + 1.0/(1+3) = 0.583
- Section 6: 1.0/(1+3) + 1.0/(1+1) = 0.75
After sorting by score, the final ranking becomes: Section 2 (first), Section 6 (second), Section 7 (third).
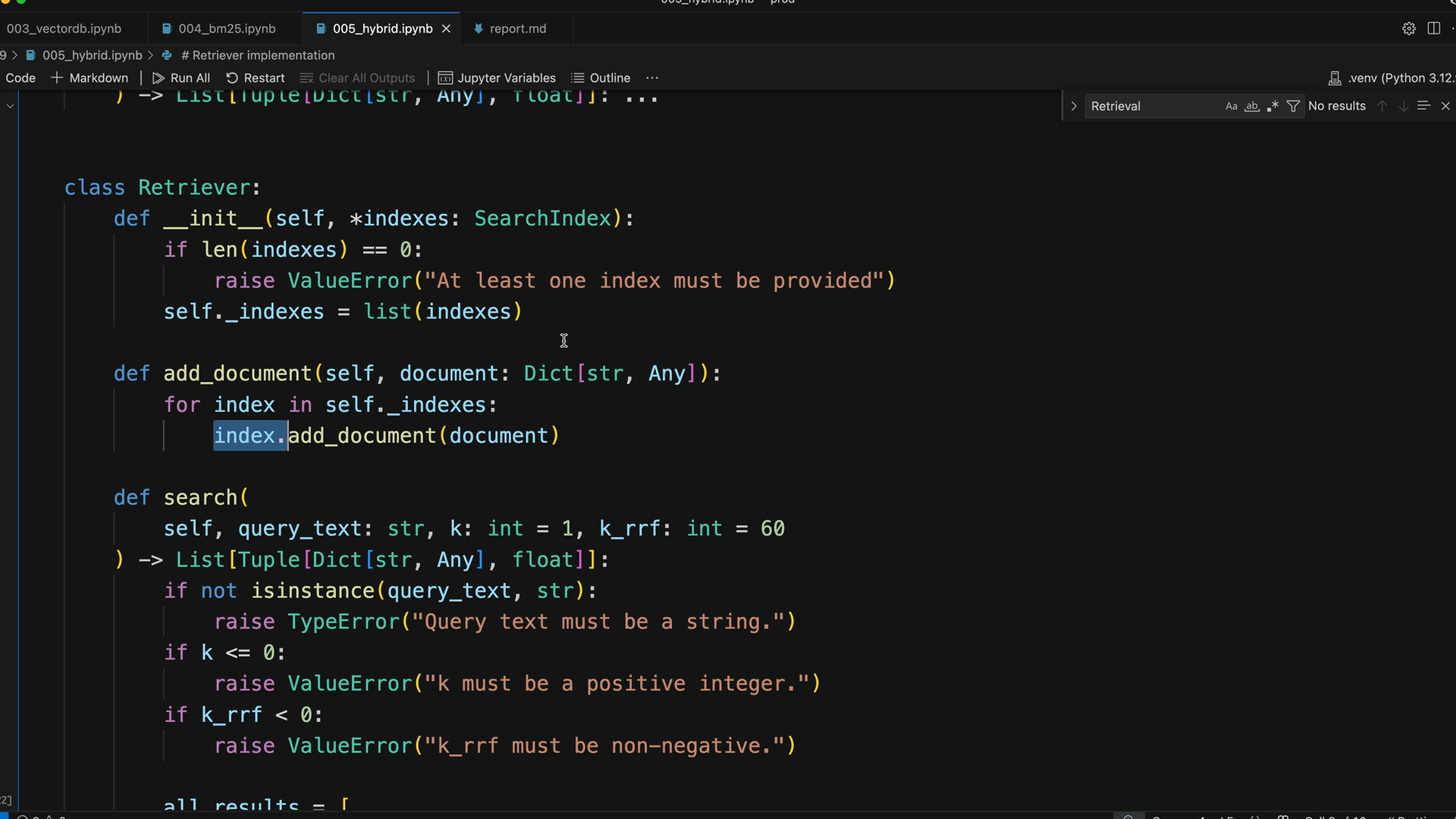
Implementation
The Retriever class implementation is straightforward:
class Retriever:
def __init__(self, *indexes):
self._indexes = list(indexes)
def add_document(self, document):
for index in self._indexes:
index.add_document(document)
def search(self, query_text, k=1, k_rrf=60):
# Get results from all indexes
all_results = []
for idx, results in enumerate(all_results):
for rank, (doc, _) in enumerate(results):
# Track document ranks across systems
# Apply RRF formula
# Return merged, sorted results
The key insight is that the RRF algorithm creates a unified ranking by considering how well each document performs across all search systems, rather than relying on any single scoring method.
Testing the Hybrid Approach
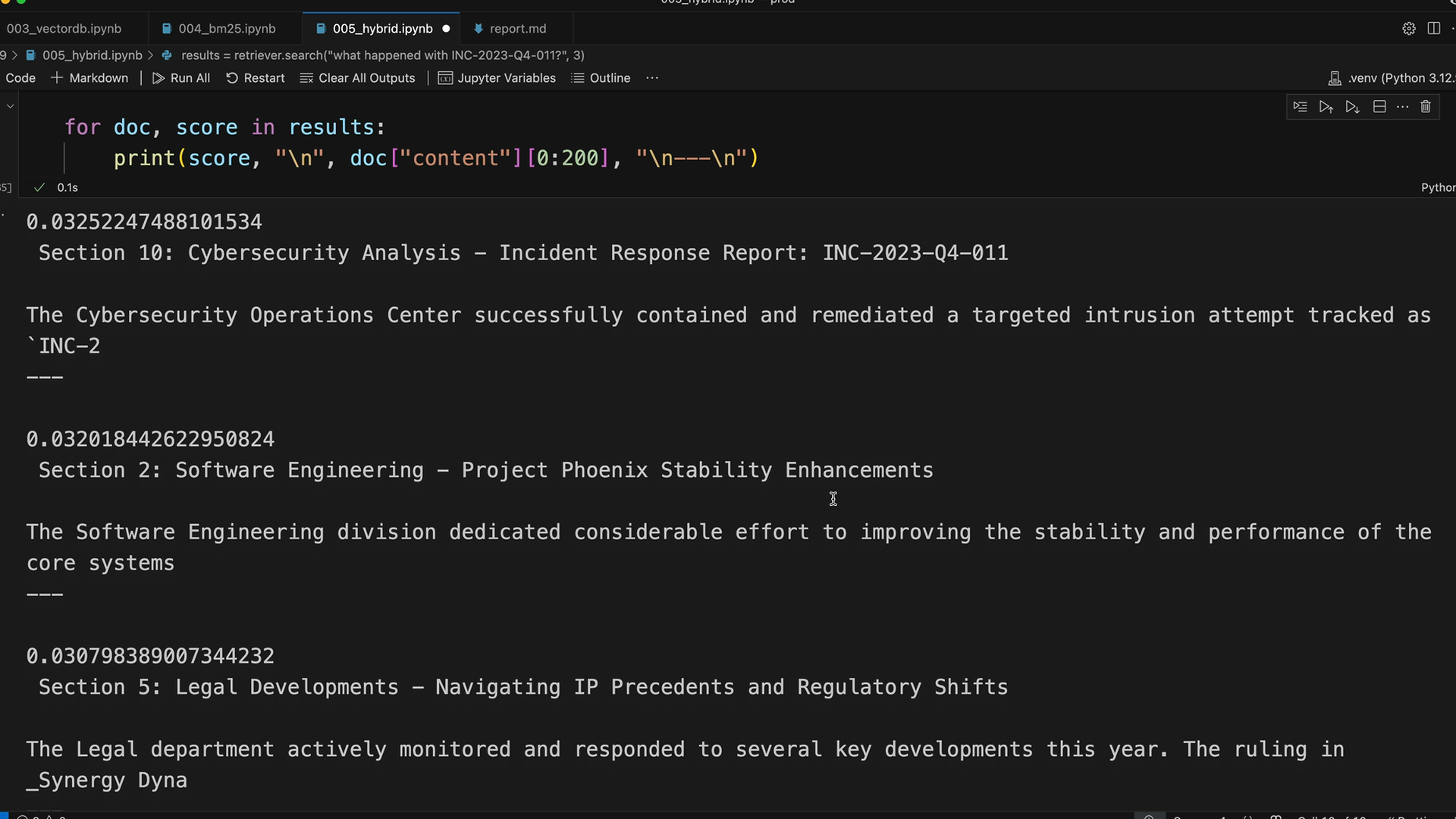
When testing with a query like "what happened with INC-2023-Q4-011?", the hybrid approach delivers significantly better results than either method alone. Instead of getting unexpected results from pure vector search, you now get the most relevant cybersecurity incident report first, followed by related software engineering content.
Extensibility
The beauty of this design is its modularity. Since each search index implements the same interface (add_document() and search()), you can easily add new search methodologies to the system. Whether it's a different embedding model, a specialized domain search, or any other retrieval technique, as long as it follows the established API, it integrates seamlessly into the hybrid pipeline.
This hybrid search approach represents a significant improvement in retrieval accuracy by combining the semantic understanding of vector search with the precise keyword matching of lexical search, all unified through the mathematically sound RRF ranking algorithm.
Downloads
🔁 Related lessons
- Next: Reranking results
- Previous: BM25 lexical search
- Same section: Overview of Claude Models · Accessing the API · Making a request
- Part of paths: Path C
- Reference docs: Glossary · Skills atlas · By use-case
📚 Source & attribution
- Original Anthropic Academy lesson: https://anthropic.skilljar.com/claude-in-amazon-bedrock/276779
- © 2025 Anthropic. Educational fair-use only.