📖 Nội dung bài học
Tóm tắt
Khi đánh giá các mô hình AI tạo mã code, bạn cần nhiều hơn là chỉ kiểm tra xem phản hồi có hợp lý không. Bạn cũng cần xác minh rằng mã code được tạo ra thực sự có cú pháp hợp lệ và tuân theo đúng định dạng. Đây là lúc đánh giá dựa trên mã code phát huy tác dụng.
Cách đánh giá mã code hoạt động
Đánh giá mã code xác thực hai khía cạnh chính của phản hồi do AI tạo ra:
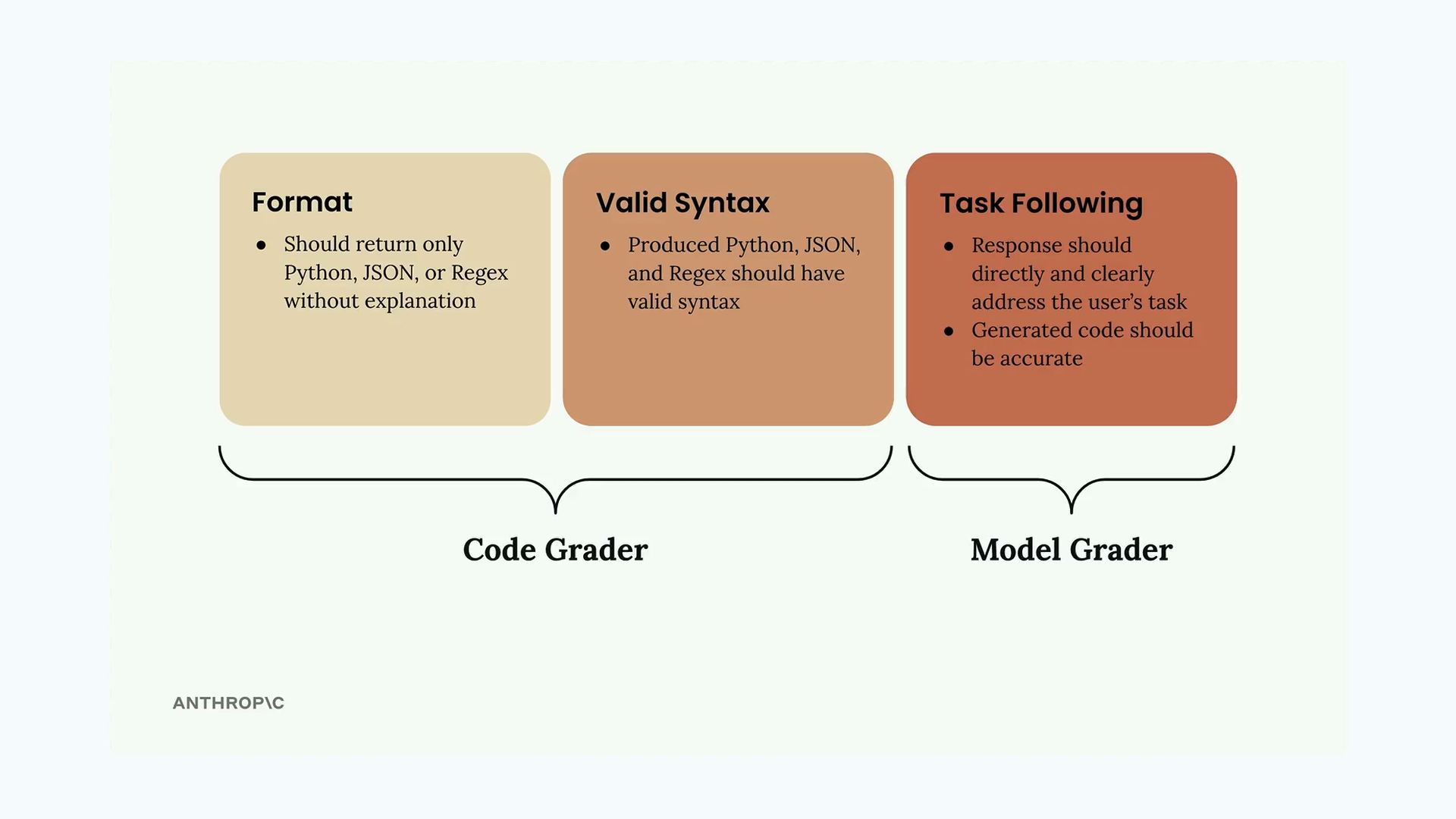
- Định dạng - Phản hồi chỉ nên trả về loại mã code được yêu cầu (Python, JSON hoặc Regex) mà không có giải thích.
- Cú pháp hợp lệ - Mã code được tạo ra phải phân tích cú pháp chính xác theo ngôn ngữ dự định.
- Tuân theo tác vụ - Phản hồi phải giải quyết trực tiếp những gì được yêu cầu và chính xác.
Hai tiêu chí đầu tiên được xử lý bởi bộ đánh giá mã code, trong khi việc tuân theo tác vụ được đánh giá bởi bộ đánh giá mô hình. Cùng nhau, chúng cung cấp một đánh giá toàn diện.
Các hàm xác thực cú pháp
Để kiểm tra xem mã code được tạo ra có cú pháp hợp lệ hay không, bạn có thể tạo ba hàm trợ giúp cố gắng phân tích cú pháp đầu ra:

def validate_json(text):
try:
json.loads(text.strip())
return 10
except json.JSONDecodeError:
return 0
def validate_python(text):
try:
ast.parse(text.strip())
return 10
except SyntaxError:
return 0
def validate_regex(text):
try:
re.compile(text.strip())
return 10
except re.error:
return 0
Mỗi hàm cố gắng phân tích cú pháp văn bản dưới dạng định dạng tương ứng. Nếu phân tích cú pháp thành công, nó sẽ trả về điểm tuyệt đối là 10. Nếu thất bại với lỗi, cú pháp không hợp lệ và trả về 0.
Yêu cầu định dạng bộ dữ liệu
Để bộ đánh giá mã code biết nên sử dụng trình xác thực nào, các trường hợp kiểm thử của bạn cần chỉ định định dạng đầu ra mong muốn:
{
"task": "Create a Python function to validate an AWS IAM username",
"format": "python"
}
Bạn có thể cập nhật prompt tạo bộ dữ liệu của mình để tự động bao gồm trường định dạng này bằng cách thêm nó vào cấu trúc đầu ra ví dụ.
Cải thiện độ rõ ràng của prompt
Để có kết quả tốt hơn từ mô hình AI của bạn, hãy làm cho hướng dẫn prompt của bạn cụ thể hơn về định dạng đầu ra mong muốn:
* Respond only with Python, JSON, or a plain Regex
* Do not add any comments or commentary or explanation
Bạn cũng có thể sử dụng tin nhắn trợ lý được điền sẵn với các khối mã code để khuyến khích mô hình chỉ trả về mã code thô:
add_assistant_message(messages, "```code")
Điều này cho Claude biết bắt đầu tạo nội dung mã code mà không cần chỉ định đó là Python, JSON hay Regex ngay từ đầu.
Kết hợp điểm số
Bước cuối cùng là hợp nhất điểm số của bộ đánh giá mô hình với điểm số của bộ đánh giá mã code. Một cách tiếp cận đơn giản là lấy trung bình chúng:
model_grade = grade_by_model(test_case, output)
model_score = model_grade["score"]
syntax_score = grade_syntax(output, test_case)
score = (model_score + syntax_score) / 2
Điều này mang lại trọng số ngang nhau cho cả chất lượng nội dung và tính chính xác về mặt kỹ thuật. Bạn có thể điều chỉnh các trọng số này tùy thuộc vào điều gì quan trọng hơn đối với trường hợp sử dụng cụ thể của bạn.
Kiểm tra việc triển khai của bạn
Sau khi bạn đã triển khai đánh giá mã code, hãy chạy đánh giá của mình để nhận điểm cơ sở. Bản thân điểm số không tốt hay xấu về bản chất - điều quan trọng là bạn có thể cải thiện nó bằng cách tinh chỉnh các prompt của mình hay không. Điều này cung cấp cho bạn một cách định lượng để đo lường tiến trình prompt engineering thay vì dựa vào đánh giá chủ quan.
Tải xuống
🔁 Bài học liên quan
- Bài tiếp: Exercise on prompt evals
- Bài trước: Model based grading
- Cùng section: Making a request · Multi-turn conversations · Chat exercise
- Thuộc lộ trình: Path C
- Docs tham khảo: Glossary · Skills atlas · By use-case
📚 Nguồn & ghi nhận
- Bài học gốc Anthropic Academy: https://anthropic.skilljar.com/claude-with-google-vertex/289167
- © 2025 Anthropic. Chỉ dùng cho mục đích giáo dục, fair-use.
- Crawl: 2026-04-23 · Chuẩn hoá: 2026-05-01