📖 Nội dung bài học
Tóm tắt
Xây dựng quy trình đánh giá prompt tùy chỉnh bắt đầu bằng việc tạo một prompt vững chắc và sau đó tạo dữ liệu kiểm thử để xem nó hoạt động tốt như thế nào. Hãy cùng xem qua việc thiết lập hệ thống đánh giá cho một prompt giúp người dùng viết mã dành riêng cho AWS.
Thiết lập Mục tiêu
Prompt của chúng ta cần hỗ trợ người dùng viết ba loại đầu ra cụ thể cho các trường hợp sử dụng AWS:
- Mã Python
- Tệp cấu hình JSON
- Biểu thức chính quy (Regular expressions)
Yêu cầu chính là khi người dùng yêu cầu trợ giúp về một tác vụ, chúng ta sẽ trả về đầu ra sạch sẽ dưới một trong các định dạng này mà không có bất kỳ giải thích, tiêu đề hoặc chân trang bổ sung nào.

Đây là mẫu prompt ban đầu của chúng ta:
prompt = f"""
Vui lòng cung cấp một giải pháp cho tác vụ sau:
{task}
"""
Tạo Tập dữ liệu Đánh giá
Một tập dữ liệu đánh giá chứa các đầu vào mà chúng ta sẽ cung cấp cho prompt của mình để kiểm tra hiệu suất của nó. Đối với trường hợp của chúng ta, chúng ta cần một mảng các đối tượng JSON, trong đó mỗi đối tượng có một thuộc tính "task" mô tả những gì chúng ta muốn Claude thực hiện.

Bạn có thể tạo tập dữ liệu theo hai cách:
- Tự lắp ráp chúng
- Tự động tạo chúng bằng Claude
Đối với việc tạo tự động, việc sử dụng một mô hình nhanh hơn như Haiku là hợp lý vì chúng ta đang tạo dữ liệu kiểm thử thay vì đầu ra sản xuất.
Tạo Dữ liệu Kiểm thử bằng Mã
Hãy xây dựng một hàm yêu cầu Claude tạo các trường hợp kiểm thử cho chúng ta. Hàm này sẽ tạo một prompt toàn diện yêu cầu các loại tác vụ liên quan đến AWS cụ thể.
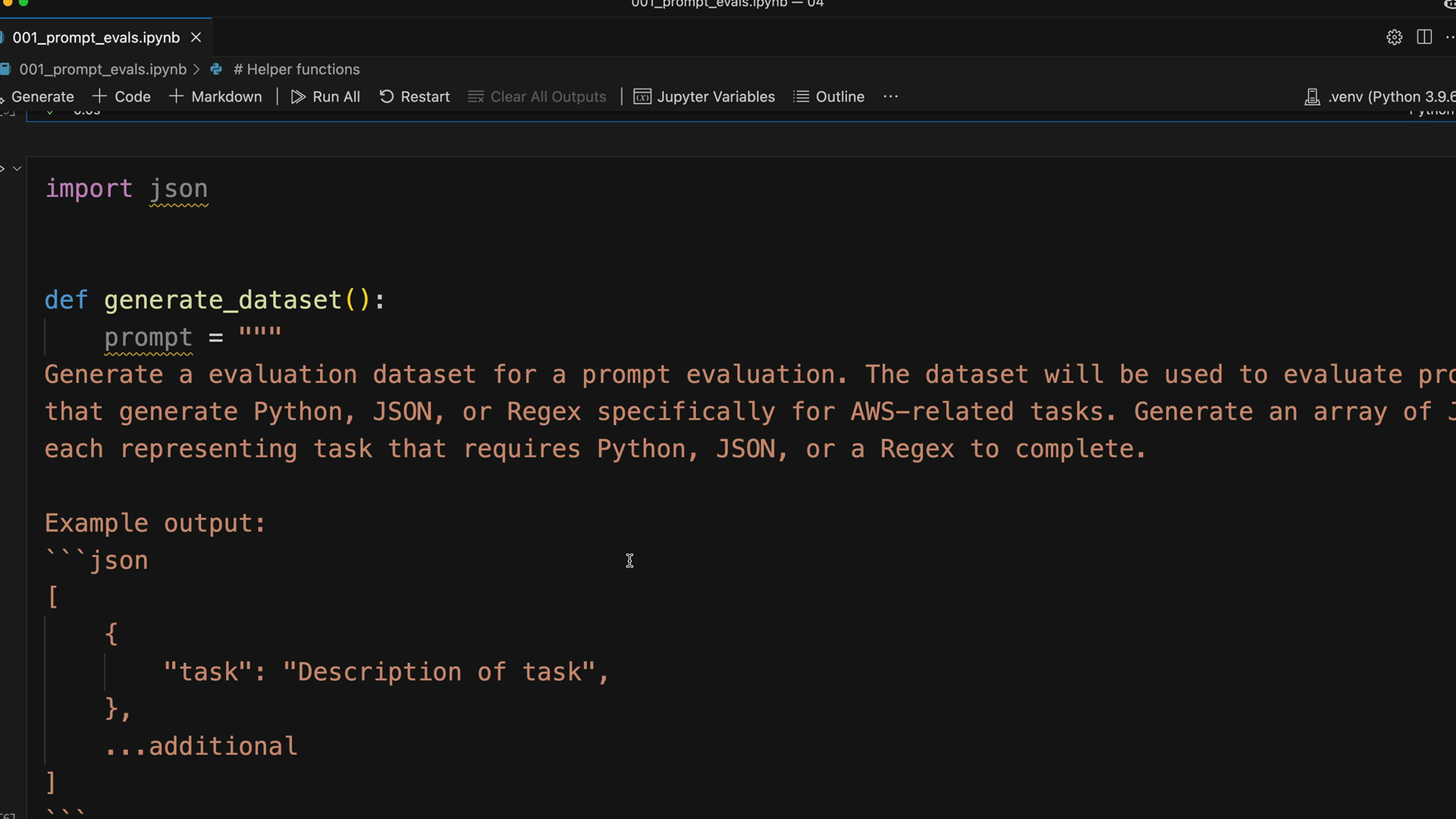
Đây là cấu trúc hàm cốt lõi:
def generate_dataset():
prompt = """
Tạo một tập dữ liệu đánh giá cho việc đánh giá prompt. Tập dữ liệu sẽ được sử dụng để đánh giá các prompt
tạo ra Python, JSON hoặc Regex dành riêng cho các tác vụ liên quan đến AWS. Tạo một mảng các đối tượng,
mỗi đối tượng đại diện cho một tác vụ yêu cầu Python, JSON hoặc Regex để hoàn thành.
Ví dụ đầu ra:
```json
[
{
"task": "Mô tả tác vụ",
},
...bổ sung
]
```
* Tập trung vào các tác vụ có thể được giải quyết bằng cách viết một hàm Python duy nhất, một đối tượng JSON duy nhất hoặc một regex duy nhất
* Tập trung vào các tác vụ không yêu cầu viết nhiều mã
Vui lòng tạo 3 đối tượng.
"""
Triển khai Logic Tạo Dữ liệu
Để nhận được đầu ra JSON sạch từ Claude, chúng ta sẽ sử dụng kỹ thuật điền trước (pre-filling) với các chuỗi dừng (stop sequences):
messages = []
add_user_message(messages, prompt)
add_assistant_message(messages, "```json")
text = chat(messages, stop_sequences=["```"])
return json.loads(text)
Cách tiếp cận này đảm bảo Claude bắt đầu phản hồi của mình bằng JSON được định dạng đúng và dừng lại ở dấu phân cách markdown đóng.
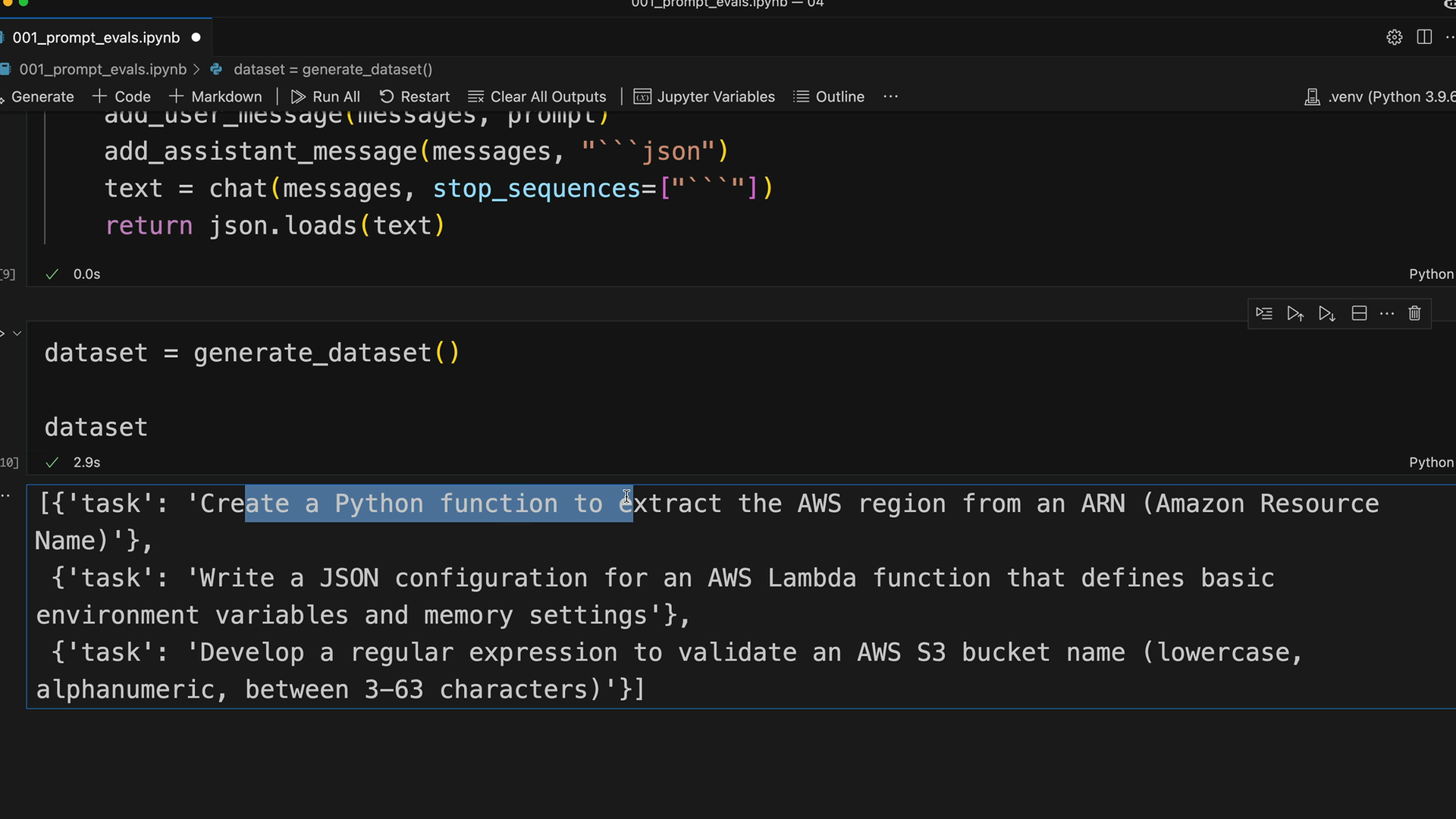
Kiểm thử và Lưu Tập dữ liệu
Sau khi chạy hàm tạo, bạn sẽ nhận được các trường hợp kiểm thử thực tế như:
- Tạo một hàm Python để trích xuất vùng AWS (region) từ ARN
- Viết một cấu hình JSON cho một hàm AWS Lambda
- Phát triển một biểu thức chính quy để xác thực tên bucket AWS S3
Lưu tập dữ liệu đã tạo của bạn vào một tệp để dễ dàng sử dụng lại:
dataset = generate_dataset()
with open('dataset.json', 'w') as f:
json.dump(dataset, f, indent=2)
Thao tác này sẽ tạo một tệp dataset.json trong thư mục notebook của bạn, chứa tất cả các trường hợp kiểm thử của bạn, sẵn sàng để sử dụng cho việc đánh giá prompt trong các bước tiếp theo của quy trình làm việc của bạn.
Tải xuống
🔁 Bài học liên quan
- Bài tiếp: Running the eval
- Bài trước: A typical eval workflow
- Cùng section: Making a request · Multi-turn conversations · Chat exercise
- Thuộc lộ trình: Path C
- Docs tham khảo: Glossary · Skills atlas · By use-case
📚 Nguồn & ghi nhận
- Bài học gốc Anthropic Academy: https://anthropic.skilljar.com/claude-with-google-vertex/289163
- © 2025 Anthropic. Chỉ dùng cho mục đích giáo dục, fair-use.
- Crawl: — · Chuẩn hoá: 2026-05-01