📖 Nội dung bài học
Summary
Khi xây dựng ứng dụng chat với Claude, có một thách thức lớn về trải nghiệm người dùng: phản hồi có thể mất 10-30 giây để tạo ra, khiến người dùng nhìn chằm chằm vào vòng quay tải. Giải pháp là response streaming, cho phép người dùng thấy văn bản xuất hiện từng phần nhỏ khi Claude tạo ra nó, tạo cảm giác phản hồi nhanh hơn nhiều.
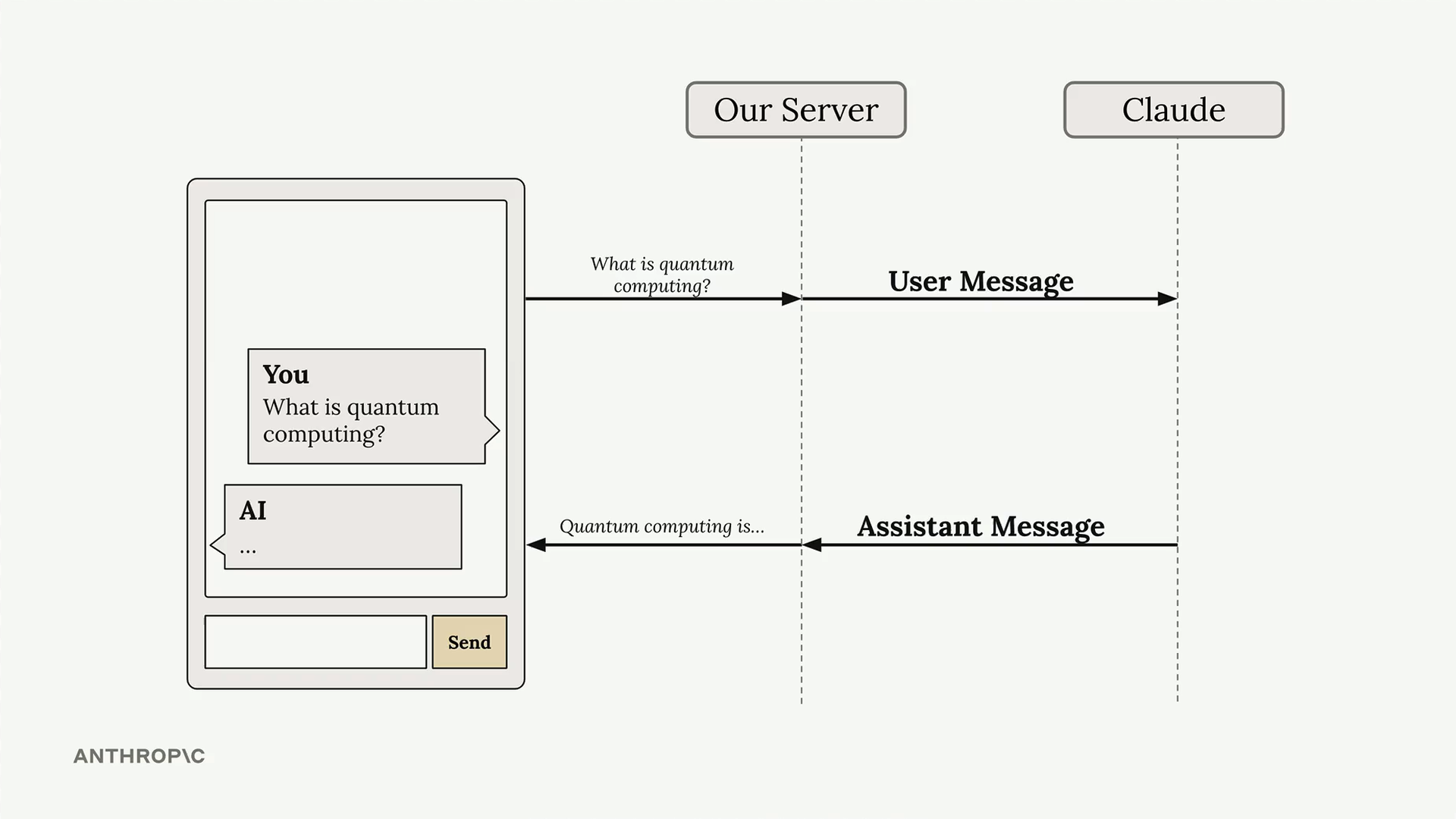
Vấn đề với Phản hồi Tiêu chuẩn
Trong một thiết lập chat thông thường, server của bạn gửi tin nhắn người dùng đến Claude và chờ phản hồi hoàn chỉnh trước khi gửi bất cứ thứ gì trở lại client. Điều này tạo ra một độ trễ khó chịu, nơi người dùng không nhận được phản hồi nào về việc có điều gì đó đang xảy ra.
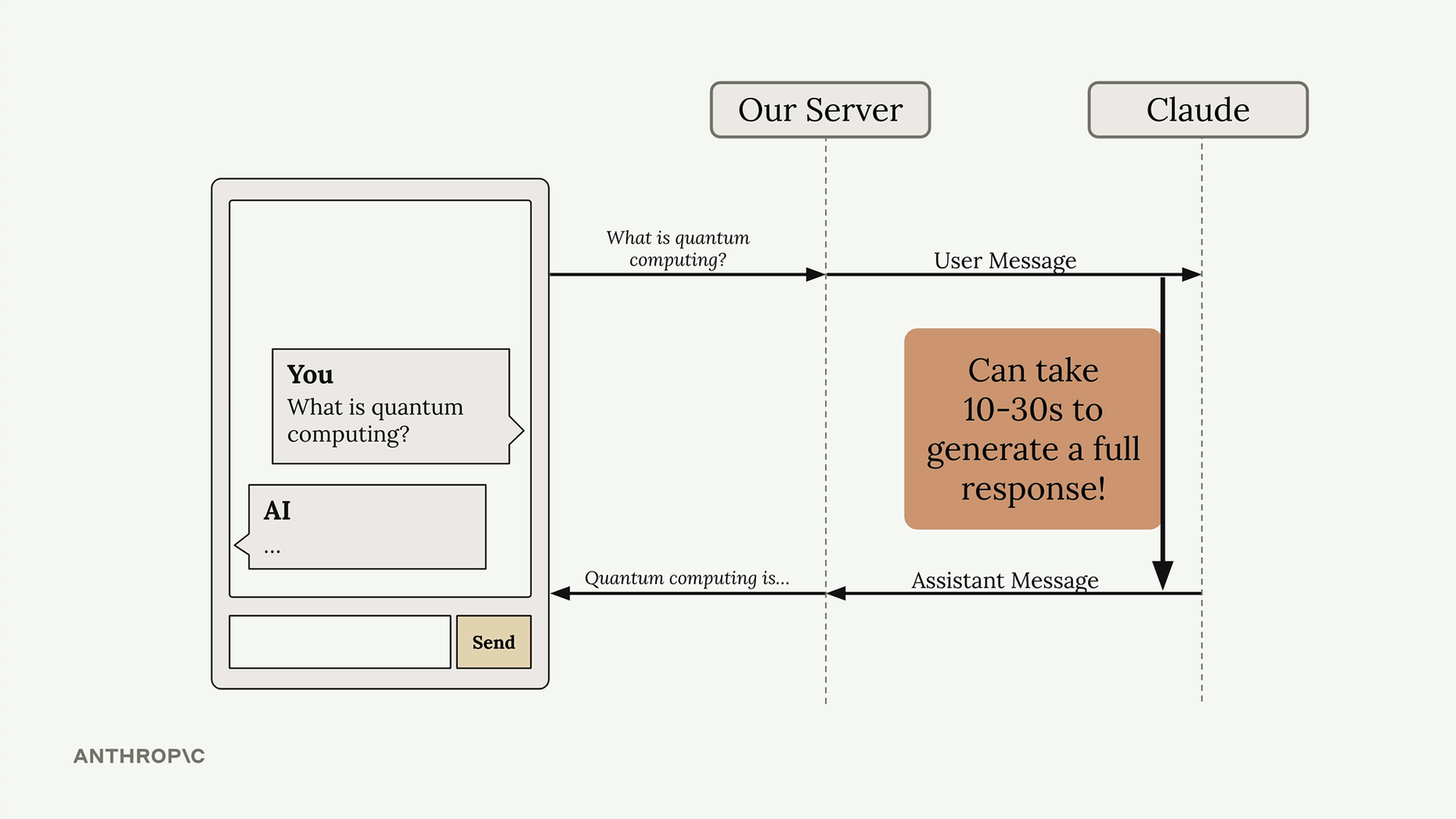
Streaming Hoạt động Như thế nào
Với streaming được bật, Claude ngay lập tức gửi lại phản hồi ban đầu cho biết nó đã nhận yêu cầu của bạn và đang bắt đầu tạo văn bản. Sau đó, bạn nhận được một loạt các sự kiện, mỗi sự kiện chứa một phần nhỏ của phản hồi tổng thể.
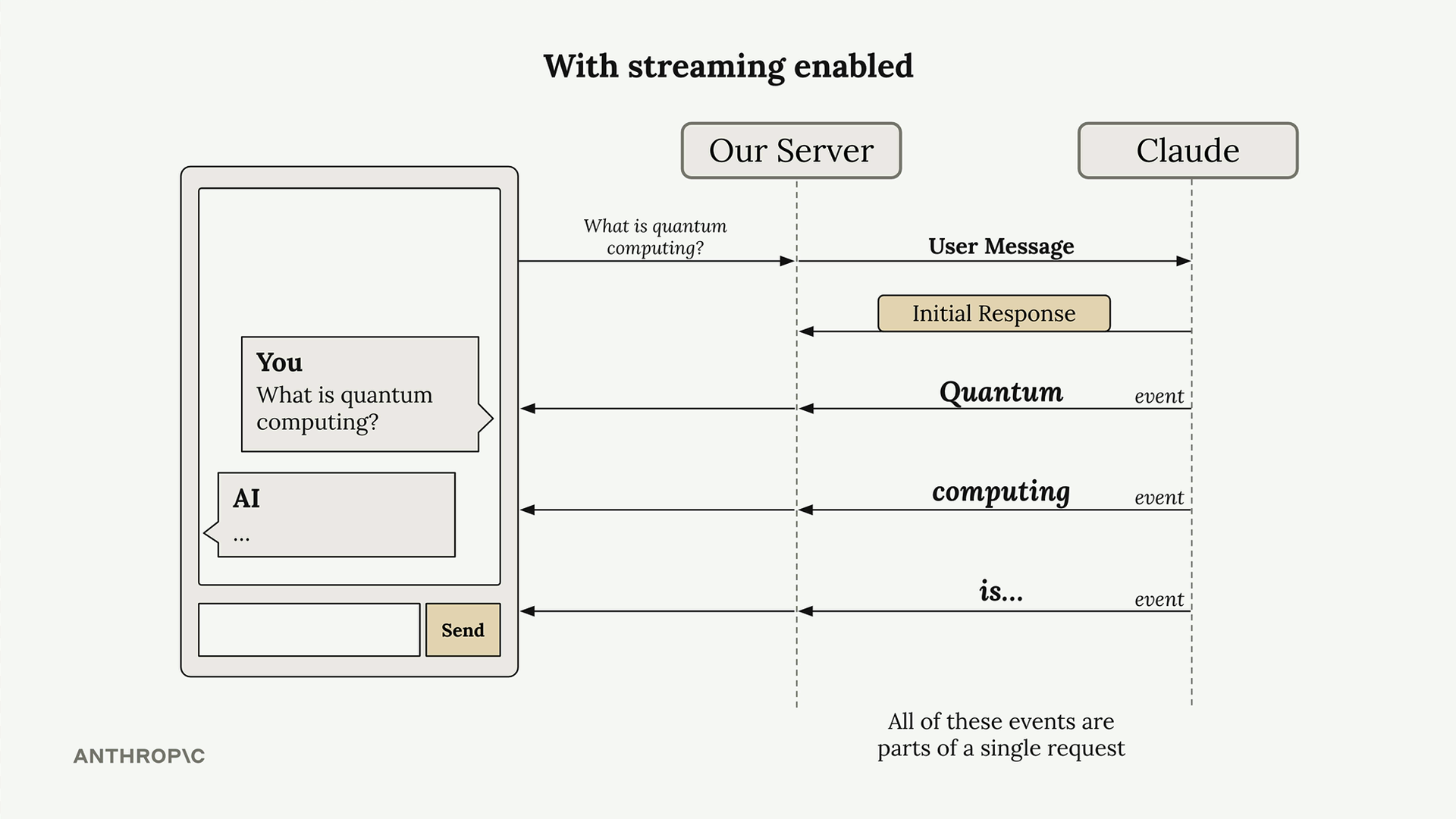
Server của bạn có thể chuyển tiếp các khối văn bản này đến ứng dụng client của bạn khi chúng đến, cho phép người dùng thấy phản hồi được xây dựng từng từ một. Tất cả các sự kiện này là một phần của một yêu cầu duy nhất đến Claude.
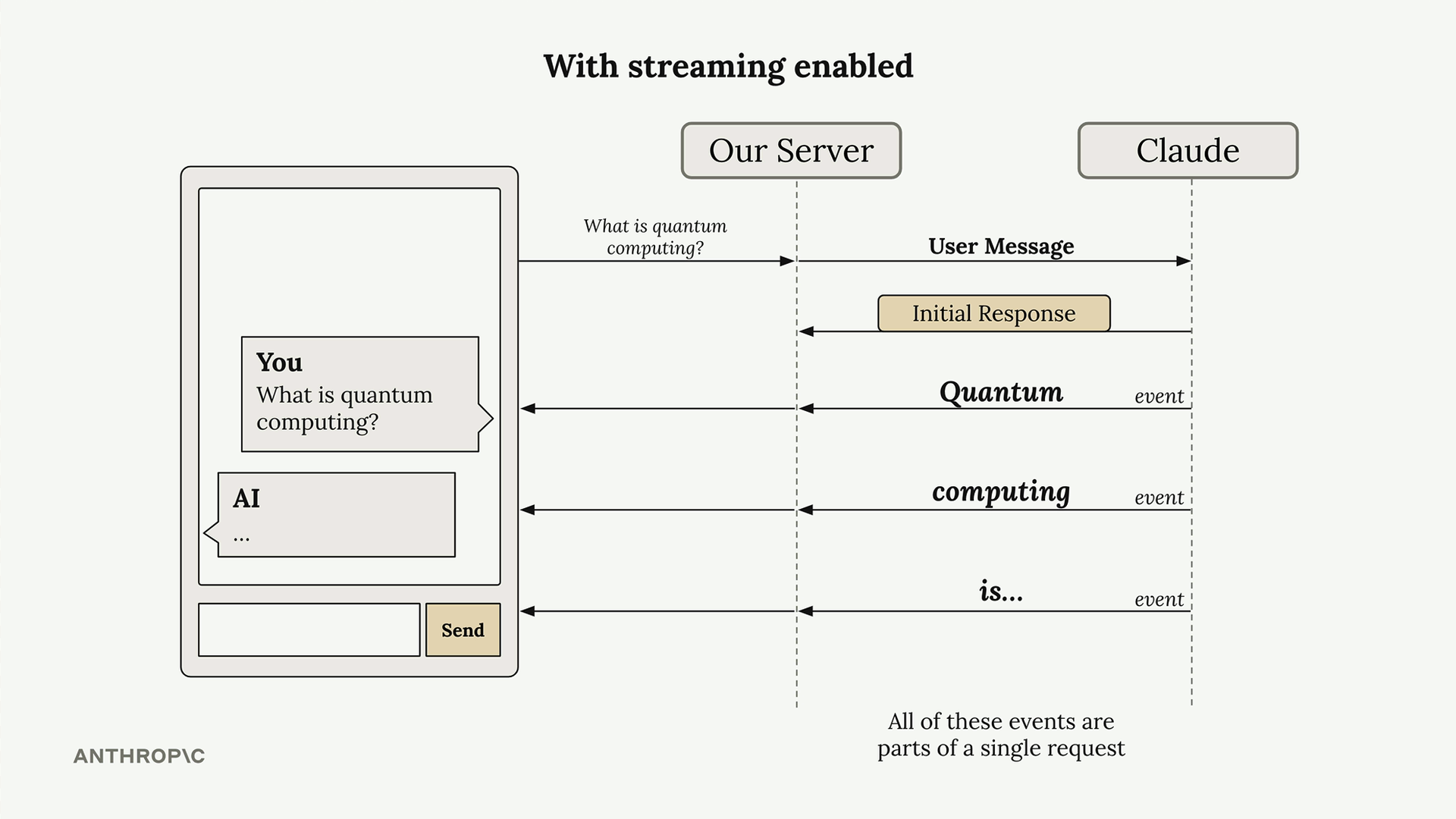
Hiểu các Sự kiện Stream
Khi bạn bật streaming, Claude sẽ gửi lại nhiều loại sự kiện:
- MessageStart - Một tin nhắn mới đang được gửi
- ContentBlockStart - Bắt đầu một khối mới chứa văn bản, sử dụng công cụ hoặc nội dung khác
- ContentBlockDelta - Các khối văn bản thực tế được tạo ra
- ContentBlockStop - Khối nội dung hiện tại đã hoàn thành
- MessageDelta - Tin nhắn hiện tại đã hoàn thành
- MessageStop - Kết thúc thông tin về tin nhắn hiện tại
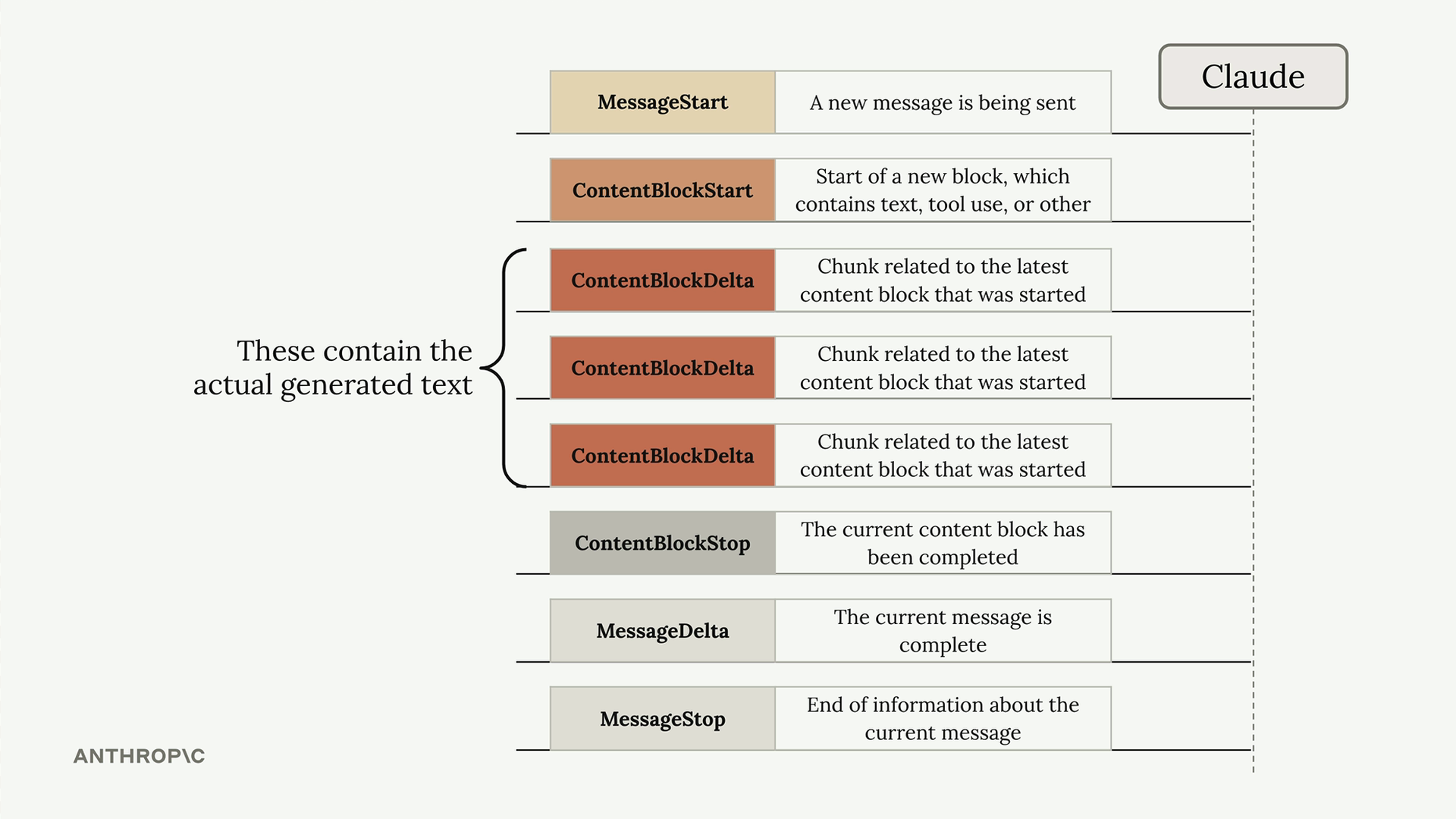
Các sự kiện ContentBlockDelta chứa văn bản thực tế được tạo ra mà bạn sẽ muốn hiển thị cho người dùng.
Triển khai Streaming Cơ bản
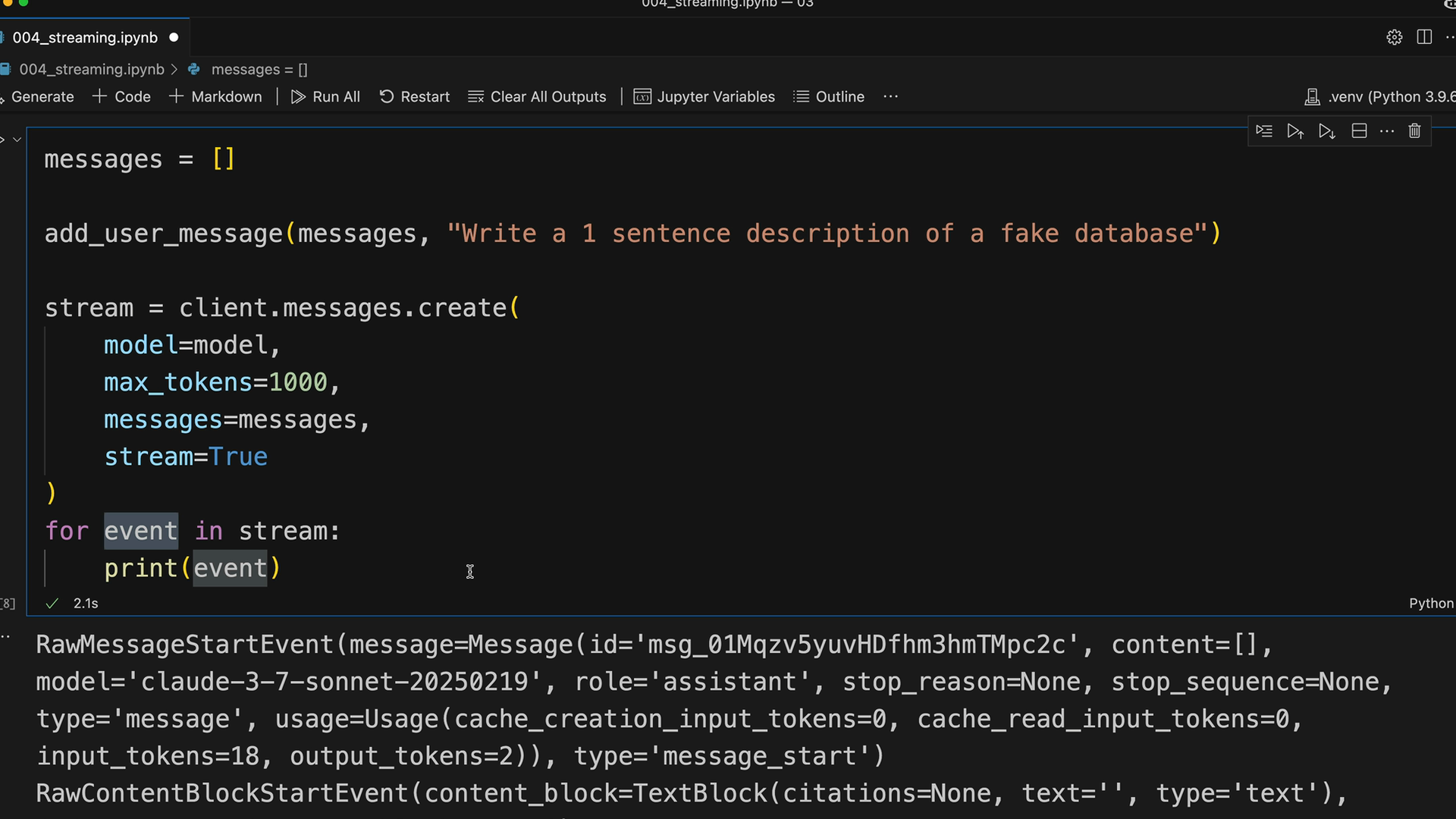
Để bật streaming, hãy thêm stream=True vào lệnh gọi messages.create của bạn:
messages = []
add_user_message(messages, "Write a 1 sentence description of a fake database")
stream = client.messages.create(
model=model,
max_tokens=1000,
messages=messages,
stream=True
)
for event in stream:
print(event)
Streaming Văn bản Đơn giản hóa
Thay vì phân tích cú pháp sự kiện thủ công, bạn có thể sử dụng giao diện streaming đơn giản hóa của SDK để trích xuất chỉ nội dung văn bản:
with client.messages.stream(
model=model,
max_tokens=1000,
messages=messages
) as stream:
for text in stream.text_stream:
print(text, end="")
Cách tiếp cận này tự động lọc bỏ mọi thứ ngoại trừ nội dung văn bản thực tế, thường là những gì bạn cần để hiển thị phản hồi cho người dùng.
Lấy Tin nhắn Cuối cùng
Mặc dù streaming rất tốt cho trải nghiệm người dùng, bạn thường cần tin nhắn hoàn chỉnh để lưu trữ hoặc xử lý thêm. Sau khi streaming hoàn tất, bạn có thể lấy tin nhắn cuối cùng đã được lắp ráp:
with client.messages.stream(
model=model,
max_tokens=1000,
messages=messages
) as stream:
for text in stream.text_stream:
pass # Gửi đến client trong ứng dụng thực tế
final_message = stream.get_final_message()
Điều này cung cấp cho bạn cả khả năng streaming cho trải nghiệm người dùng và đối tượng tin nhắn hoàn chỉnh để lưu trữ cơ sở dữ liệu hoặc lịch sử hội thoại.
Cân nhắc Thực tế
Mỗi khối văn bản trong stream có thể chứa nhiều từ hoặc thậm chí cả câu - bạn không được đảm bảo nhận chính xác một từ cho mỗi sự kiện. Kích thước khối phụ thuộc vào tốc độ Claude tạo ra từng phần văn bản.
Trong các ứng dụng sản xuất, bạn thường sẽ chuyển tiếp các khối văn bản này ngay lập tức đến ứng dụng client của bạn thông qua WebSockets hoặc Server-Sent Events, cho phép người dùng xem phản hồi xuất hiện theo thời gian thực đồng thời duy trì lịch sử hội thoại hoàn chỉnh trên server của bạn.
🔁 Bài học liên quan
- Bài tiếp: Controlling model output
- Bài trước: Course satisfaction survey
- Cùng section: Making a request · Multi-turn conversations · Chat exercise
- Thuộc lộ trình: Path C
- Docs tham khảo: Glossary · Skills atlas · By use-case
📚 Nguồn & ghi nhận
- Bài học gốc Anthropic Academy: https://anthropic.skilljar.com/claude-with-google-vertex/289162
- © 2025 Anthropic. Chỉ dùng cho mục đích giáo dục, fair-use.
- Crawl: 2026-04-23 · Chuẩn hoá: 2026-05-01