📖 Nội dung bài học
Tóm tắt
Sampling cho phép một server truy cập một mô hình ngôn ngữ như Claude thông qua một client MCP đã kết nối. Thay vì server gọi trực tiếp Claude, nó yêu cầu client thực hiện cuộc gọi thay cho nó. Điều này chuyển trách nhiệm và chi phí tạo văn bản từ server sang client.
Vấn đề mà Sampling giải quyết
Hãy tưởng tượng bạn có một server MCP với một công cụ nghiên cứu để lấy thông tin từ Wikipedia. Sau khi thu thập tất cả dữ liệu đó, bạn cần tóm tắt nó thành một báo cáo mạch lạc. Bạn có hai lựa chọn:
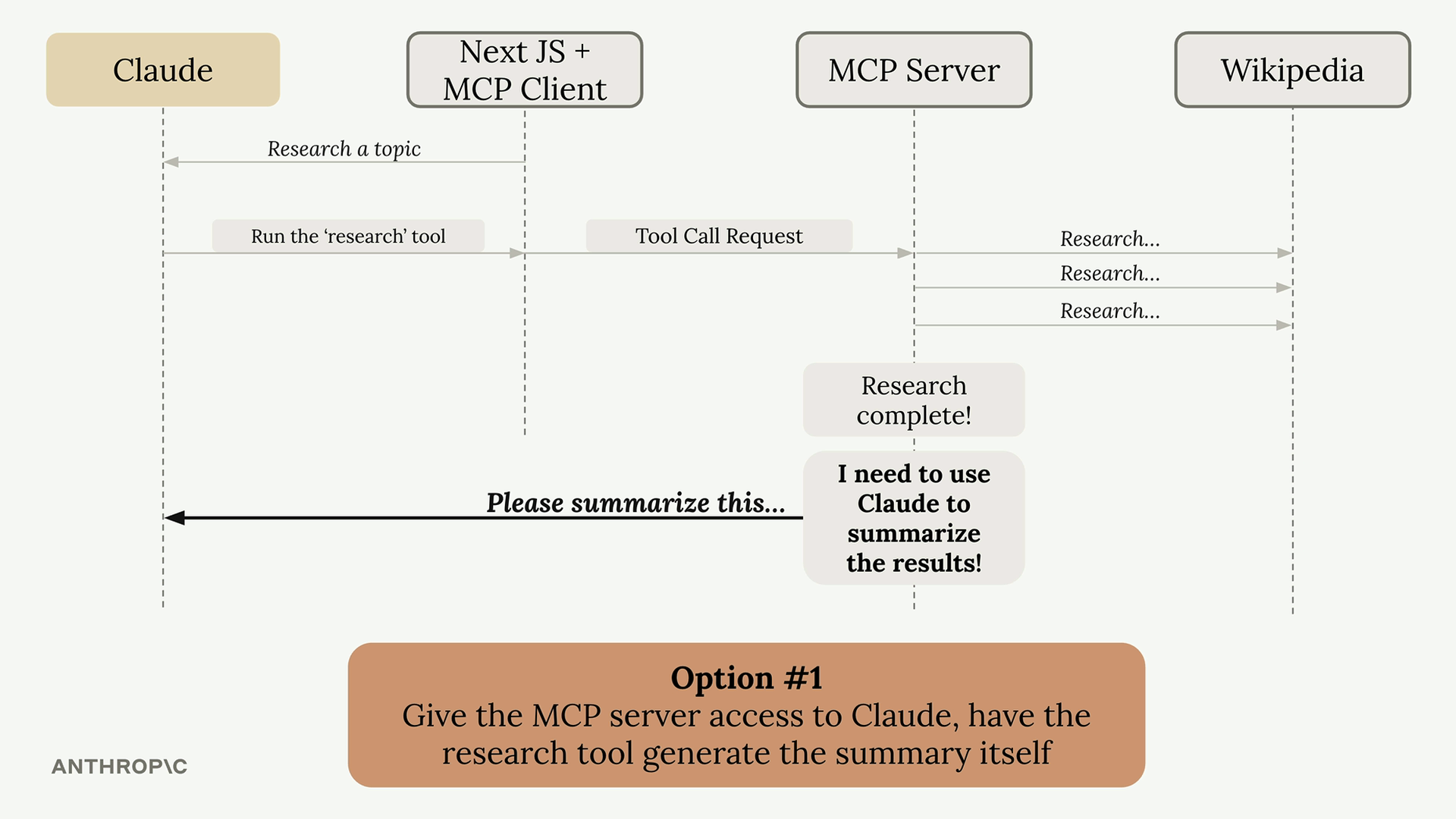
Lựa chọn 1: Cung cấp cho server MCP quyền truy cập trực tiếp vào Claude. Server sẽ cần key API riêng, xử lý xác thực, quản lý chi phí và triển khai tất cả mã tích hợp Claude. Cách này hoạt động nhưng làm tăng đáng kể độ phức tạp.
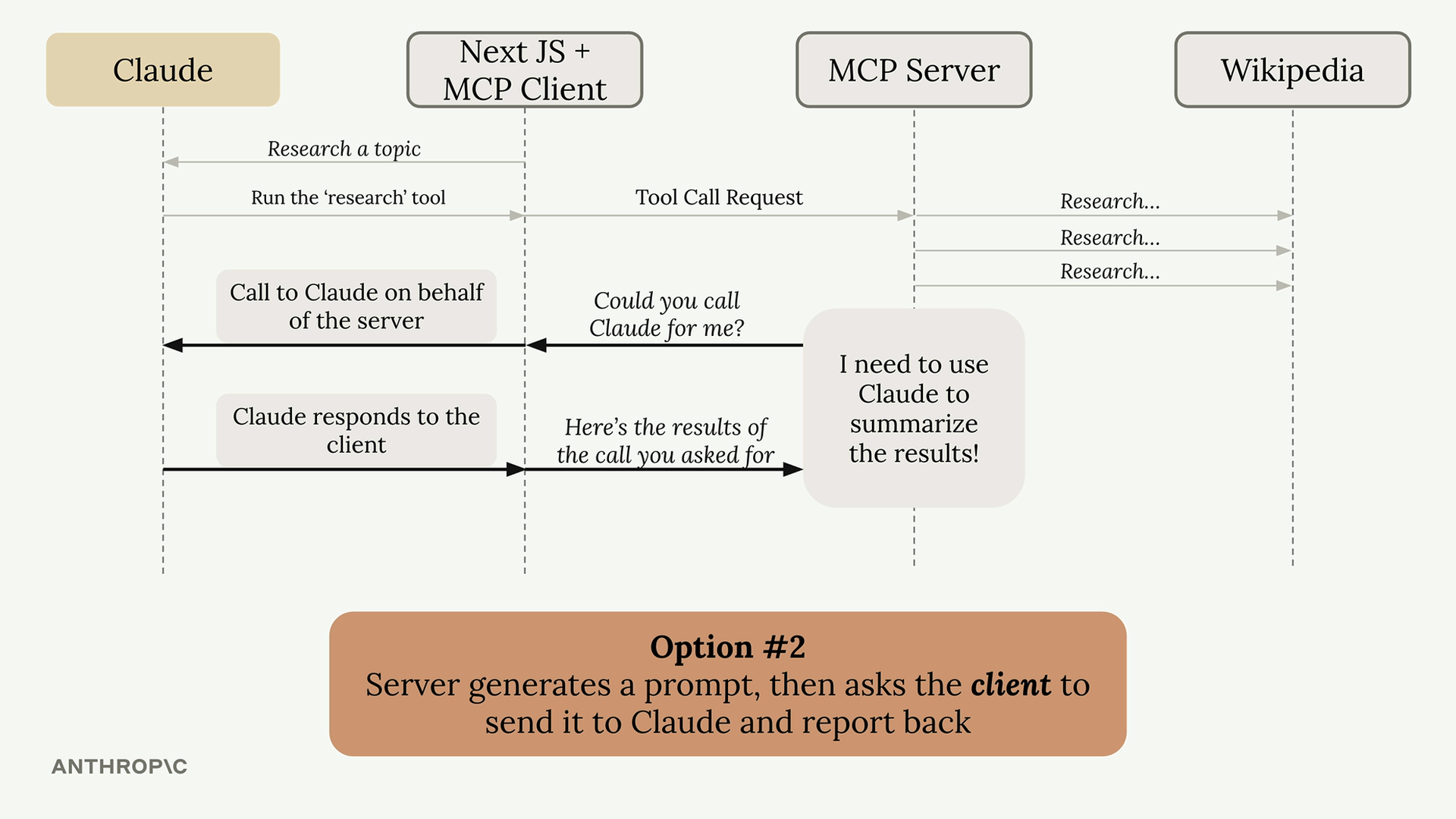
Lựa chọn 2: Dùng sampling. Server tạo một prompt và hỏi client "Bạn có thể gọi Claude giúp tôi được không?" Client, vốn đã có kết nối với Claude, thực hiện cuộc gọi và trả về kết quả.
Sampling hoạt động như thế nào
Luồng hoạt động rất đơn giản:
- Server hoàn thành công việc của nó (ví dụ: lấy các bài viết trên Wikipedia)
- Server tạo một
promptyêu cầu tạo văn bản - Server gửi một yêu cầu sampling đến client
- Client gọi Claude với
promptđã cung cấp - Client trả về văn bản được tạo cho server
- Server sử dụng văn bản được tạo trong phản hồi của nó
Lợi ích của Sampling
- Giảm độ phức tạp của server: Server không cần tích hợp trực tiếp với các mô hình ngôn ngữ
- Chuyển gánh nặng chi phí: Client trả tiền cho việc dùng
token, không phải server - Không cần key API: Server không cần thông tin đăng nhập cho Claude
- Hoàn hảo cho các server công cộng: Bạn không muốn một server công cộng phải chịu chi phí AI cho mọi người dùng
Triển khai
Thiết lập sampling yêu cầu code ở cả hai phía:
Phía Server
Trong hàm công cụ của bạn, dùng hàm create_message để yêu cầu tạo văn bản:
@mcp.tool()
async def summarize(text_to_summarize: str, ctx: Context):
prompt = f"""
Please summarize the following text:
{text_to_summarize}
"""
result = await ctx.session.create_message(
messages=[
SamplingMessage(
role="user",
content=TextContent(
type="text",
text=prompt
)
)
],
max_tokens=4000,
system_prompt="You are a helpful research assistant",
)
if result.content.type == "text":
return result.content.text
else:
raise ValueError("Sampling failed")
Phía Client
Tạo một callback sampling để xử lý các yêu cầu của server:
async def sampling_callback(
context: RequestContext, params: CreateMessageRequestParams
):
# Gọi Claude dùng Anthropic SDK
text = await chat(params.messages)
return CreateMessageResult(
role="assistant",
model=model,
content=TextContent(type="text", text=text),
)
Sau đó, truyền callback này khi khởi tạo phiên client của bạn:
async with ClientSession(
read,
write,
sampling_callback=sampling_callback
) as session:
await session.initialize()
Khi nào dùng Sampling
Sampling có giá trị nhất khi xây dựng các server MCP có thể truy cập công khai. Bạn không muốn người dùng ngẫu nhiên tạo văn bản không giới hạn với chi phí của bạn. Bằng cách dùng sampling, mỗi client trả tiền cho việc dùng AI của riêng họ trong khi vẫn được hưởng lợi từ chức năng của server của bạn.
Kỹ thuật này về cơ bản di chuyển độ phức tạp tích hợp AI từ server của bạn sang client, vốn thường đã có các kết nối và thông tin đăng nhập cần thiết.
🔁 Bài học liên quan
- Bài tiếp: Sampling walkthrough
- Bài trước: Let's get started!
- Thuộc lộ trình: Path D
- Docs tham khảo: Glossary · Skills atlas · By use-case
📚 Nguồn & ghi nhận
- Bài học gốc Anthropic Academy: https://anthropic.skilljar.com/model-context-protocol-advanced-topics/296288
- © 2025 Anthropic. Chỉ dùng cho mục đích giáo dục, fair-use.
- Crawl: — · Chuẩn hoá: 2026-05-01