📖 Nội dung bài học
Tóm tắt
Chúng ta đã xây dựng các triển khai riêng biệt cho tìm kiếm ngữ nghĩa (semantic search - sử dụng vector embedding) và tìm kiếm từ vựng (lexical search - sử dụng BM25). Bây giờ là lúc kết hợp chúng vào một pipeline tìm kiếm thống nhất để tận dụng thế mạnh của cả hai phương pháp.
Cấu trúc đa chỉ mục (Multi-Index Architecture)
Cả hai lớp VectorIndex và BM25Index đều chia sẻ các API gần như giống hệt nhau - cả hai đều có các phương thức add_document() và search(). Sự nhất quán này giúp việc bao bọc (wrap) chúng lại trong một lớp mới gọi là Retriever trở nên đơn giản.
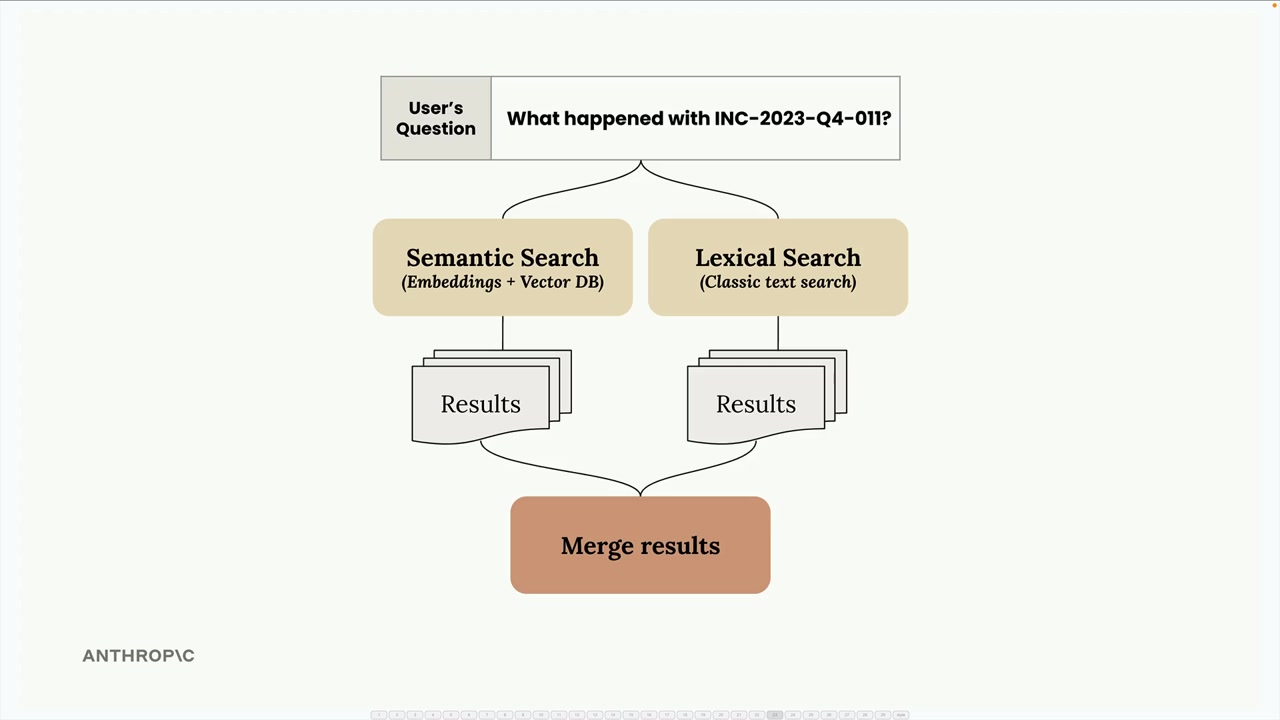
Retriever đóng vai trò như một bộ điều phối, chuyển các truy vấn của người dùng đến cả hai chỉ mục, thu thập kết quả và gộp chúng lại bằng một kỹ thuật gọi là hợp nhất xếp hạng nghịch đảo (reciprocal rank fusion - RRF).
Hiểu về Hợp nhất xếp hạng nghịch đảo (Reciprocal Rank Fusion)
Việc gộp kết quả từ các phương pháp tìm kiếm khác nhau không đơn giản là nối các danh sách lại với nhau. Mỗi phương pháp sử dụng hệ thống tính điểm khác nhau, vì vậy chúng ta cần một cách để chuẩn hóa và kết hợp thứ hạng của chúng một cách công bằng.
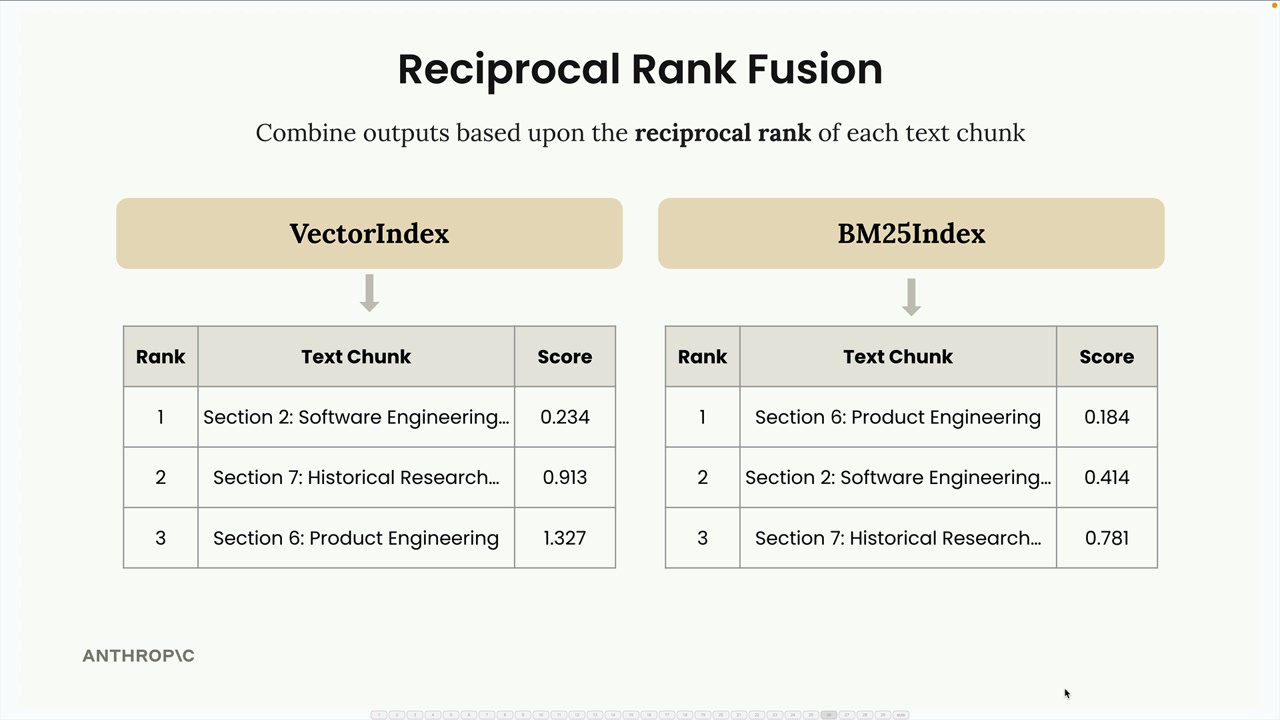
Dưới đây là cách RRF hoạt động thông qua một ví dụ. Giả sử chúng ta tìm kiếm thông tin về "INC-2023-Q4-011" và nhận được các kết quả sau:
- VectorIndex trả về: Section 2 (hạng 1), Section 7 (hạng 2), Section 6 (hạng 3)
- BM25Index trả về: Section 6 (hạng 1), Section 2 (hạng 2), Section 7 (hạng 3)
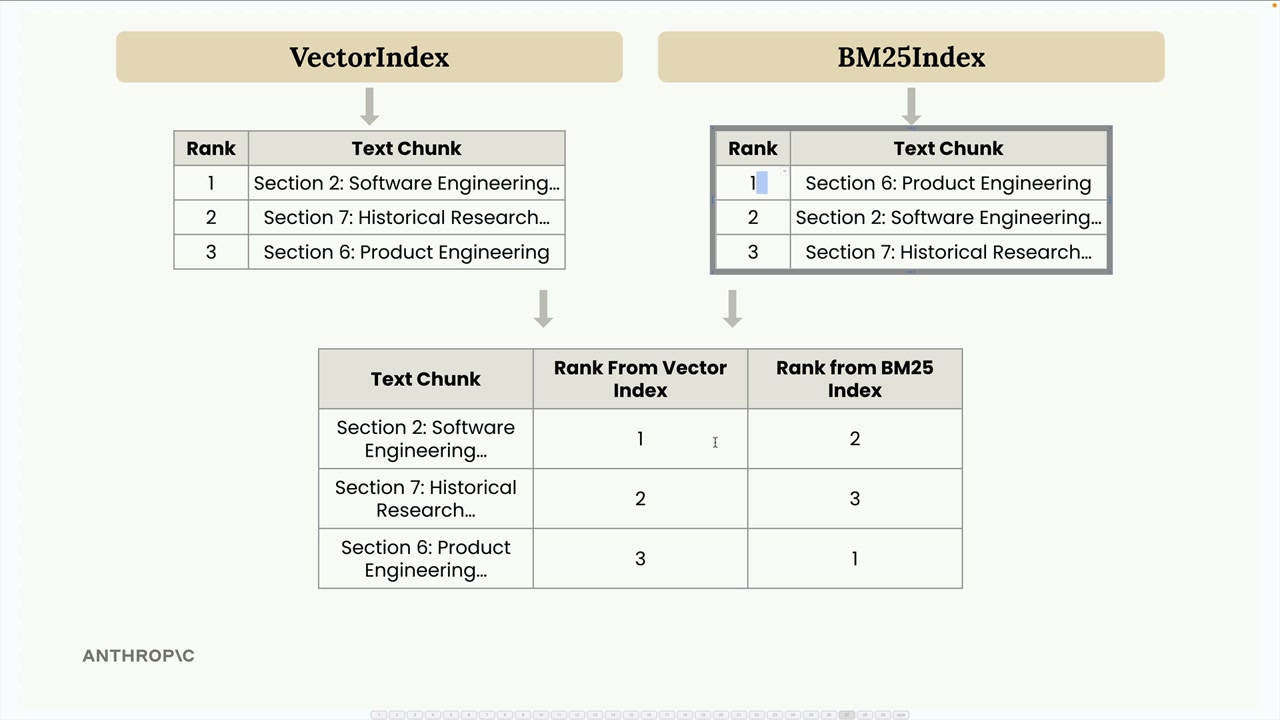
Chúng ta kết hợp các kết quả này vào một bảng duy nhất hiển thị thứ hạng của từng đoạn văn bản từ cả hai chỉ mục, sau đó áp dụng công thức RRF:
RRF_score(d) = Σ(1 / (k + rank_i(d)))
Trong đó k là một hằng số (thường là 60, nhưng chúng ta sẽ dùng 1 để kết quả rõ ràng hơn) và rank_i(d) là thứ hạng của tài liệu d trong bảng xếp hạng thứ i.
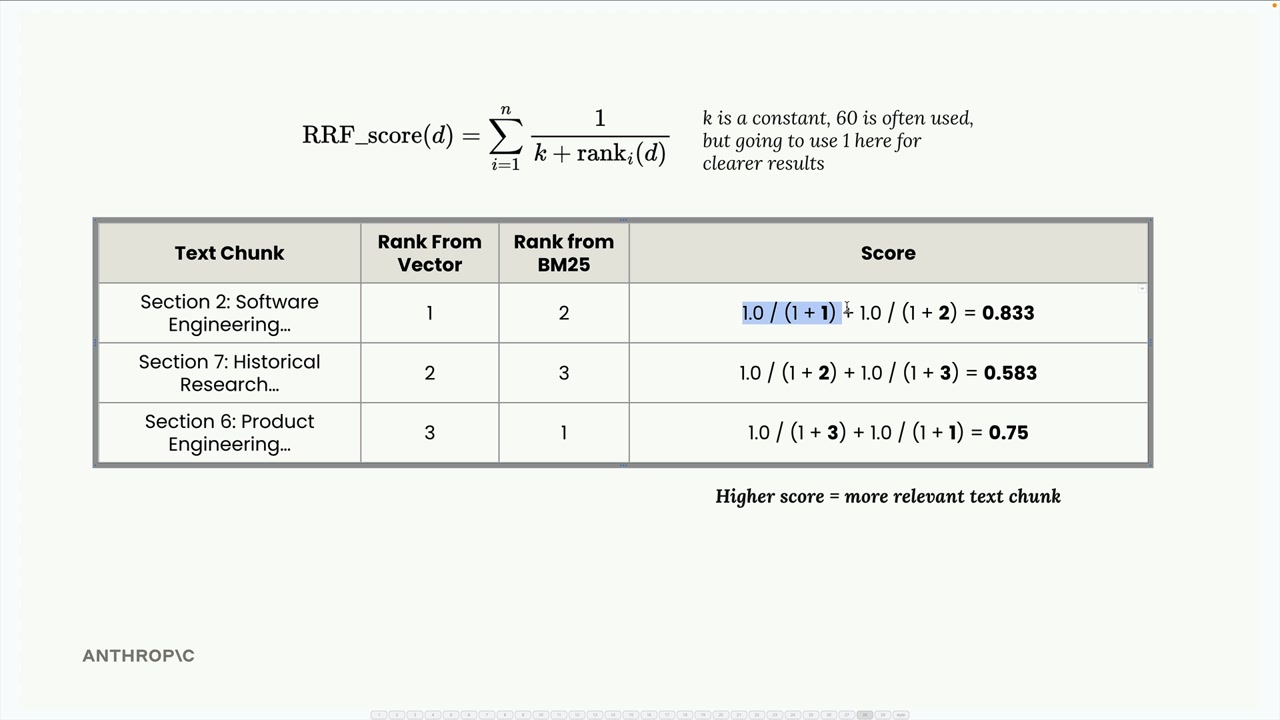
Cho ví dụ của chúng ta:
- Section 2: 1.0/(1+1) + 1.0/(1+2) = 0.833
- Section 7: 1.0/(1+2) + 1.0/(1+3) = 0.583
- Section 6: 1.0/(1+3) + 1.0/(1+1) = 0.75
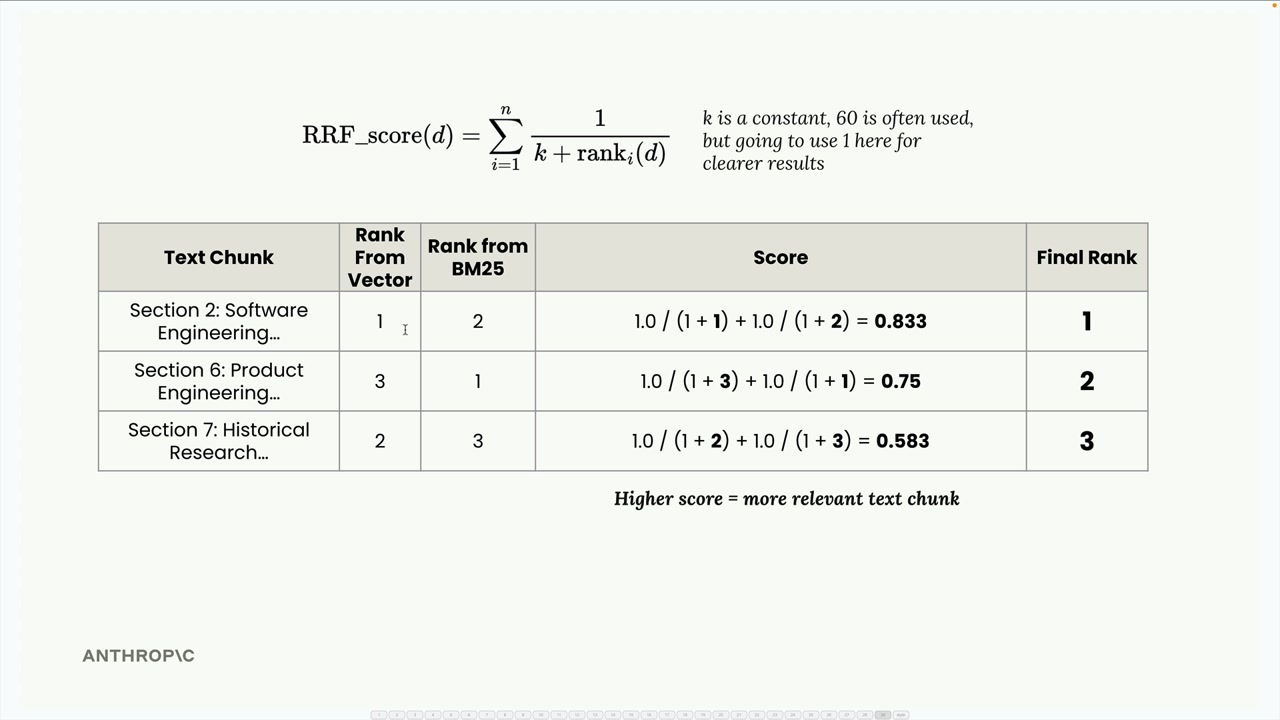
Thứ hạng cuối cùng sẽ là: Section 2 (0.833), Section 6 (0.75), Section 7 (0.583). Điều này hoàn toàn hợp lý - Section 2 có kết quả tốt ở cả hai chỉ mục, nên nó vươn lên dẫn đầu.
Chi tiết triển khai
Lớp Retriever bao bọc nhiều chỉ mục tìm kiếm và cung cấp một giao diện thống nhất:
class Retriever:
def __init__(self, *indexes: SearchIndex):
if len(indexes) == 0:
raise ValueError("At least one index must be provided")
self._indexes = list(indexes)
def add_document(self, document: Dict[str, Any]):
for index in self._indexes:
index.add_document(document)
def search(self, query_text: str, k: int = 1, k_rrf: int = 60):
# Lấy kết quả từ tất cả các chỉ mục
all_results = []
for idx, results in enumerate(all_results):
for rank, (doc, _) in enumerate(results):
# Theo dõi thứ hạng tài liệu qua các chỉ mục
# Áp dụng công thức tính điểm RRF
# Trả về kết quả đã gộp và sắp xếp
Điểm mấu chốt là bằng cách duy trì các API nhất quán giữa các triển khai tìm kiếm khác nhau, chúng ta có thể dễ dàng kết hợp chúng mà không bị ràng buộc chặt chẽ (tight coupling).
Thử nghiệm phương pháp lai (Hybrid Approach)
Bạn còn nhớ vấn đề trước đây khi tìm kiếm "what happened with INC-2023-Q4-011?" trả về kết quả không mong đợi từ phương pháp chỉ dùng vector không? Sự cố an ninh mạng (Section 10) đứng đầu, nhưng phân tích tài chính (Section 3) lại đứng thứ hai thay vì phần kỹ thuật phần mềm có liên quan hơn.
Với retriever lai của chúng ta, hiện tại kết quả đã tốt hơn nhiều:
- Section 10: Cybersecurity Analysis - Incident Response Report (liên quan nhất)
- Section 2: Software Engineering - Project Phoenix Stability Enhancements (liên quan thứ hai)
- Section 5: Legal Developments (thứ ba)
Điều này chứng minh việc kết hợp tìm kiếm ngữ nghĩa và từ vựng có thể vượt qua những hạn chế của từng phương pháp khi sử dụng riêng lẻ.
Khả năng mở rộng
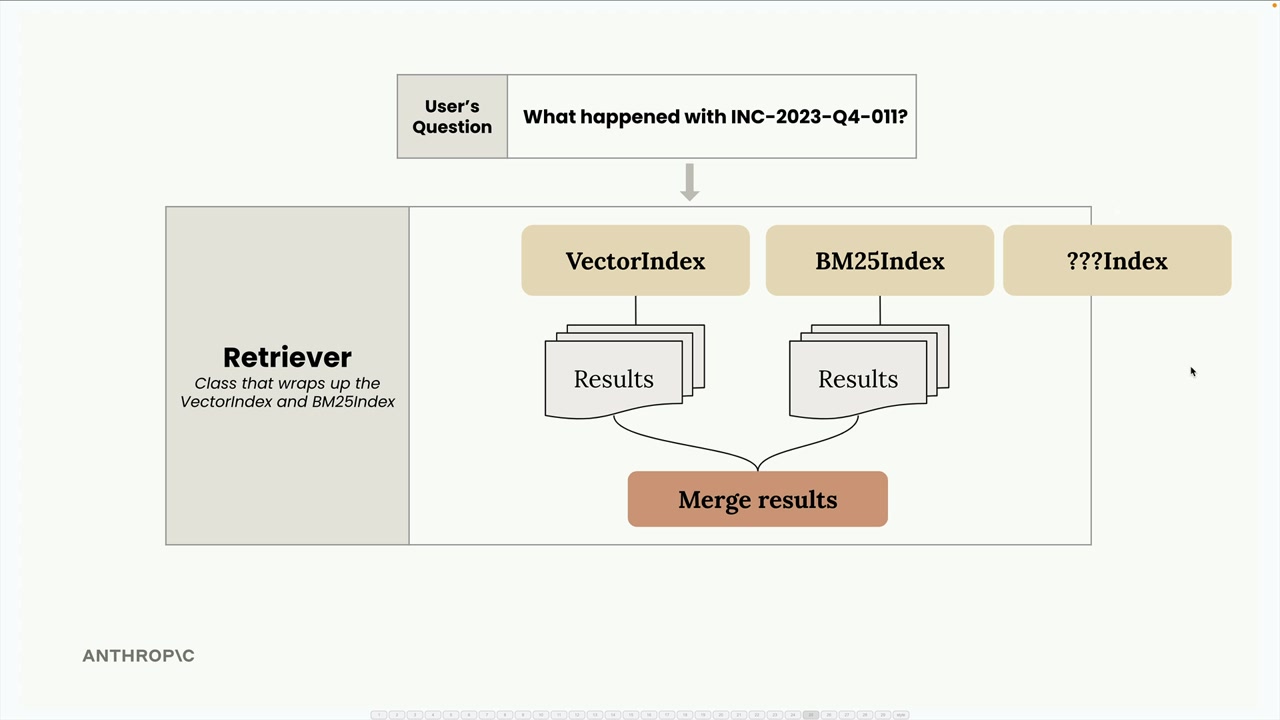
Vẻ đẹp của kiến trúc này là khả năng mở rộng của nó. Vì tất cả các chỉ mục đều triển khai cùng một SearchIndex protocol với các phương thức add_document() và search(), bạn có thể dễ dàng thêm các phương pháp tìm kiếm mới:
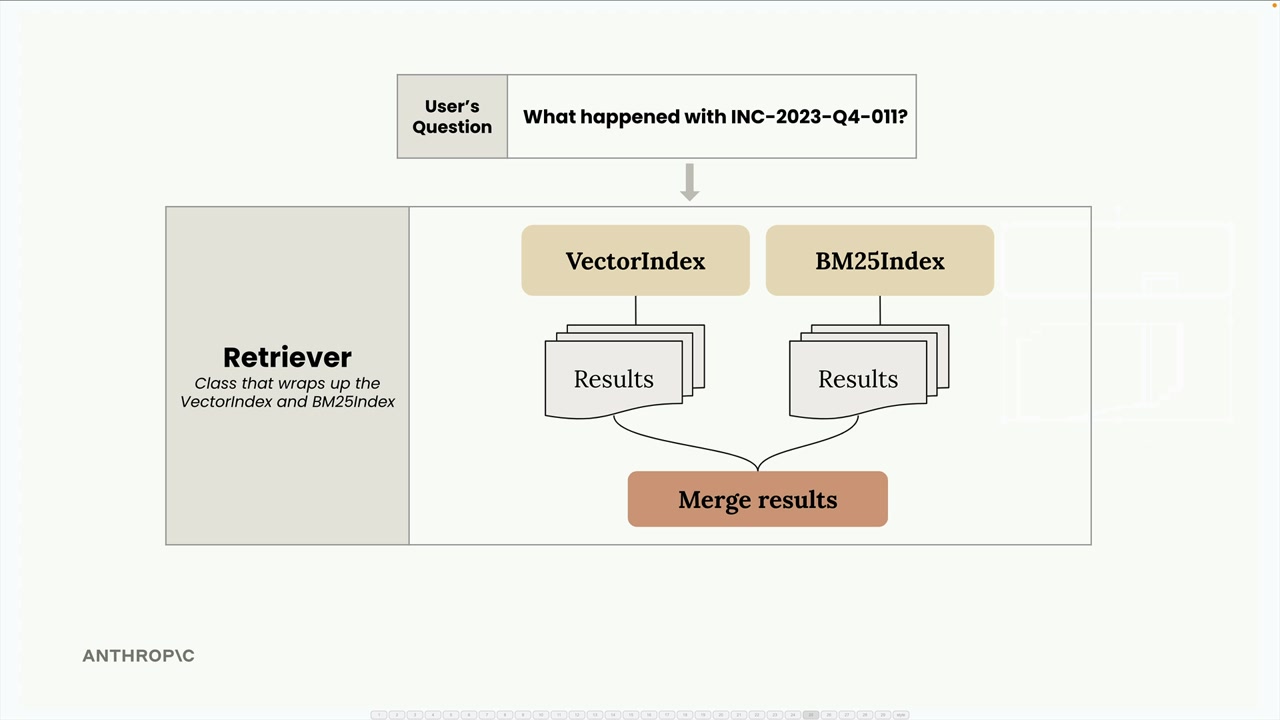
Bạn muốn thêm một chỉ mục dựa trên từ khóa (keyword-based index)? Một tìm kiếm dựa trên đồ thị (graph-based search)? Hay một chỉ mục chuyên biệt cho một lĩnh vực? Chỉ cần triển khai cùng một giao diện và Retriever sẽ tự động tích hợp nó vào quá trình hợp nhất (fusion).
Cách tiếp cận mô-đun này giúp mỗi triển khai tìm kiếm luôn tập trung và dễ kiểm thử, đồng thời cung cấp một cách sạch sẽ để kết hợp thế mạnh của chúng trong hệ thống cuối cùng.
Tải xuống
🔁 Bài học liên quan
- Bài tiếp: Extended thinking
- Bài trước: BM25 lexical search
- Cùng section: Making a request · Multi-Turn conversations · Chat exercise
- Thuộc lộ trình: Path C
- Docs tham khảo: Glossary · Skills atlas · By use-case
📚 Nguồn & ghi nhận
- Bài học gốc Anthropic Academy: https://anthropic.skilljar.com/claude-with-the-anthropic-api/287766
- © 2025 Anthropic. Chỉ dùng cho mục đích giáo dục, fair-use.
- Crawl: 2026-04-23 · Chuẩn hoá: 2026-05-01