📖 Nội dung bài học
Tóm tắt
Sau khi đã hiểu về luồng RAG (Retrieval Augmented Generation) về mặt khái niệm, chúng ta hãy cùng triển khai nó từng bước một. Chúng ta sẽ đi qua một ví dụ hoàn chỉnh, minh họa cách chia văn bản thành các chunk, tạo embedding, lưu trữ chúng trong cơ sở dữ liệu vector, và thực hiện tìm kiếm độ tương đồng.
Năm bước triển khai RAG
Việc triển khai của chúng ta tuân theo năm bước đã thảo luận trước đây:
- Chia văn bản thành các phần (chunk).
- Tạo embedding cho từng chunk.
- Tạo một vector store và thêm từng embedding vào đó.
- Tạo embedding cho câu hỏi của người dùng.
- Tìm kiếm trong store để tìm các chunk liên quan nhất.
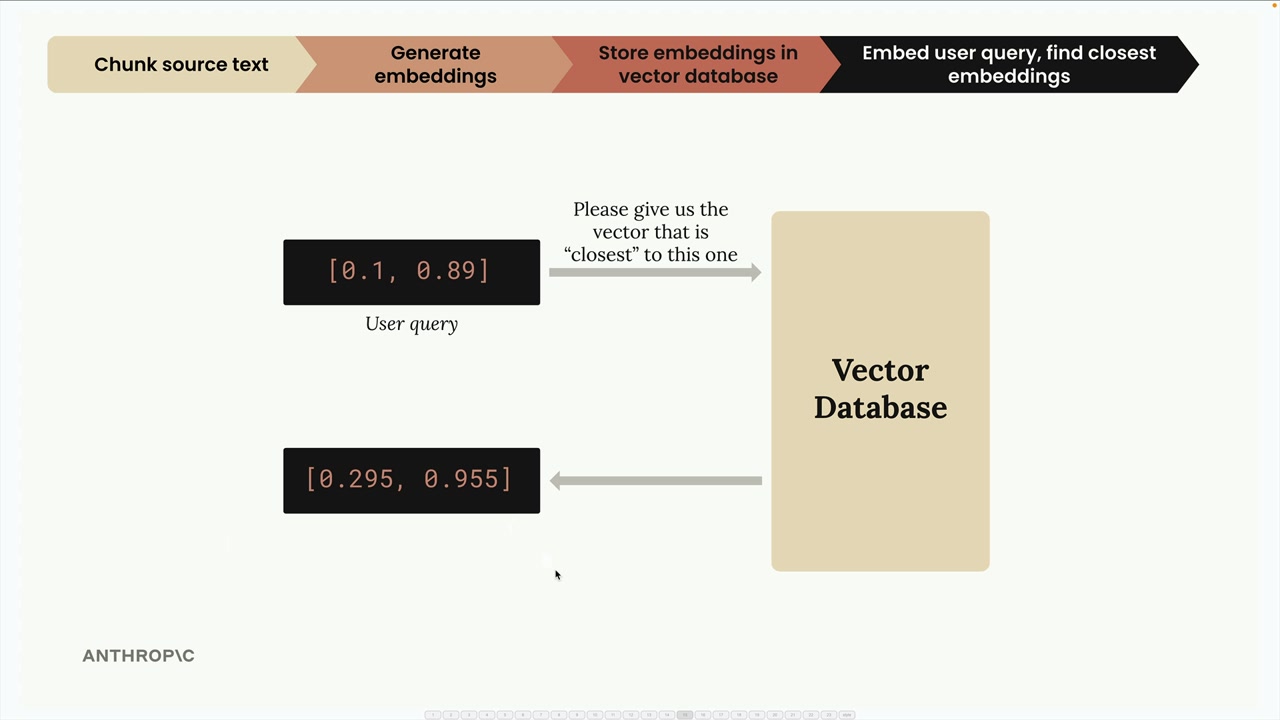
Sơ đồ này minh họa cách chúng ta chuyển đổi truy vấn của người dùng thành các embedding và tìm kiếm trong cơ sở dữ liệu vector để tìm nội dung liên quan nhất.
Bước 1: Chia văn bản thành các chunk
Đầu tiên, chúng ta tải tài liệu và chia nó thành các phần dễ quản lý:
with open("./report.md", "r") as f:
text = f.read()
chunks = chunk_by_section(text)
chunks[2] # Test to see the table of contents
Chúng ta dùng hàm chunk_by_section tương tự như trước để chia tài liệu thành các phần hợp lý.
Bước 2: Tạo Embedding
Tiếp theo, chúng ta tạo embedding cho tất cả các chunk cùng một lúc:
embeddings = generate_embedding(chunks)
Hàm tạo embedding đã được cập nhật để xử lý cả chuỗi đơn và danh sách chuỗi, giúp việc xử lý theo lô (batch processing) hiệu quả hơn.
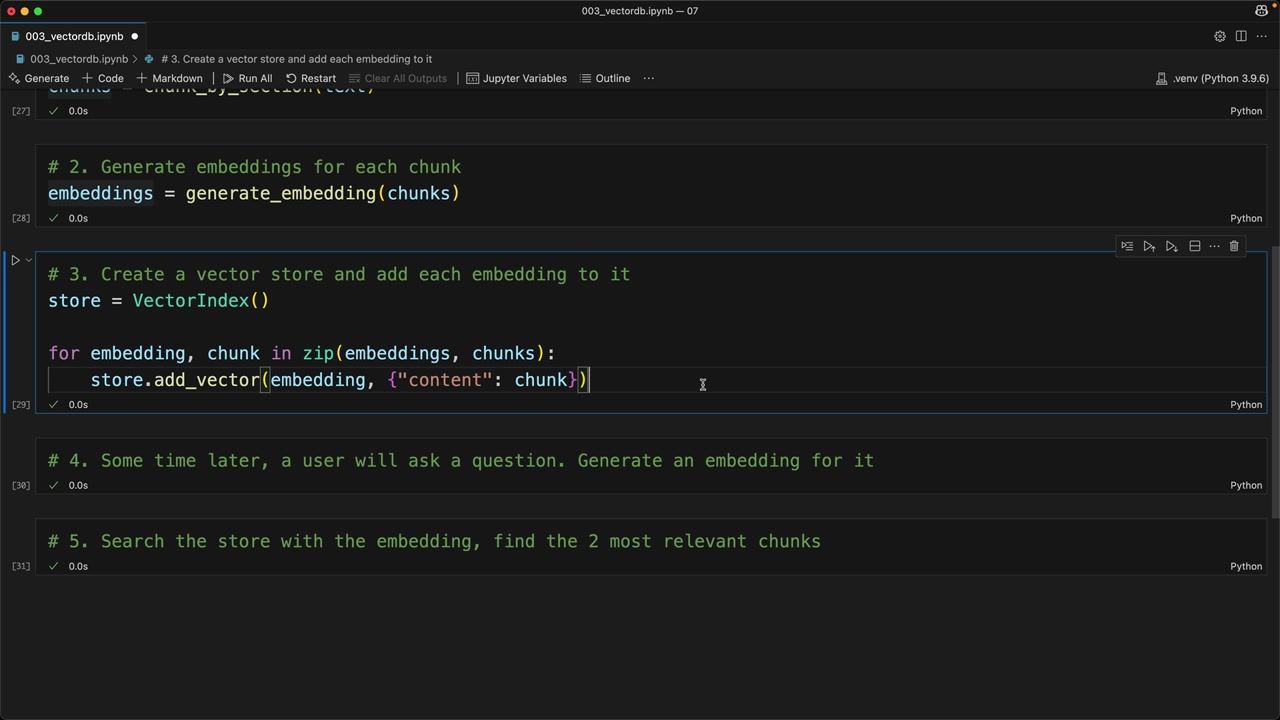
Bước 3: Lưu trữ trong cơ sở dữ liệu vector
Bây giờ chúng ta tạo vector store và điền vào đó các embedding cùng với văn bản liên quan của chúng:
store = VectorIndex()
for embedding, chunk in zip(embeddings, chunks):
store.add_vector(embedding, {"content": chunk})
Lưu ý rằng chúng ta lưu trữ cả embedding và nội dung văn bản gốc. Điều này rất quan trọng vì khi tìm kiếm sau này, chúng ta cần trả về văn bản thực tế, chứ không chỉ các giá trị số của embedding.
Tại sao phải lưu trữ văn bản gốc?
Khi chúng ta truy vấn cơ sở dữ liệu vector, việc chỉ nhận lại các số embedding là không hữu ích. Chúng ta cần văn bản thực tế đã được dùng để tạo ra các embedding đó. Đó là lý do tại sao chúng ta đưa nội dung chunk gốc (hoặc ít nhất là một tham chiếu đến nó) cùng với mỗi embedding trong cơ sở dữ liệu của mình.
Bước 4: Xử lý truy vấn người dùng
Khi người dùng đặt câu hỏi, chúng ta tạo một embedding cho truy vấn của họ:
user_embedding = generate_embedding("What did the software engineering dept do last year?")
Bước 5: Tìm nội dung liên quan
Cuối cùng, chúng ta tìm kiếm trong vector store để tìm các chunk tương tự nhất:
results = store.search(user_embedding, 2)
for doc, distance in results:
print(distance, "\n", doc["content"][0:200], "\n")
Tìm kiếm này trả về hai chunk liên quan nhất cùng với điểm độ tương đồng của chúng (cosine distances).
Kết quả tìm kiếm cho chúng ta thấy những phần nào trong tài liệu của chúng ta liên quan nhất đến câu hỏi của người dùng, cùng với điểm độ tương đồng.
Hiểu về kết quả
Khi chúng ta chạy truy vấn ví dụ về bộ phận kỹ thuật phần mềm, chúng ta nhận được:
- Phần 2: Kỹ thuật Phần mềm với khoảng cách 0.71 (kết quả khớp gần nhất)
- Phần Phương pháp luận với khoảng cách 0.72 (kết quả gần thứ hai)
Giá trị khoảng cách thấp hơn cho thấy độ tương đồng cao hơn, vì vậy Phần 2 là liên quan nhất đến truy vấn của chúng ta.
Tiếp theo là gì?
Việc triển khai này hoạt động tốt cho các trường hợp cơ bản, nhưng có những tình huống nó không hoạt động như mong đợi. Trong các phần tiếp theo, chúng ta sẽ khám phá các cải tiến để làm cho hệ thống RAG của chúng ta mạnh mẽ và chính xác hơn.
Điểm mấu chốt là RAG về cơ bản là việc chuyển đổi văn bản thành các con số (embedding), lưu trữ các con số đó một cách hiệu quả, và sau đó dùng độ tương đồng toán học để tìm nội dung liên quan khi người dùng đặt câu hỏi.
Tải xuống
🔁 Bài học liên quan
- Bài tiếp: BM25 lexical search
- Bài trước: The full RAG flow
- Cùng section: Making a request · Multi-Turn conversations · Chat exercise
- Thuộc lộ trình: Path C
- Docs tham khảo: Glossary · Skills atlas · By use-case
📚 Nguồn & ghi nhận
- Bài học gốc Anthropic Academy: https://anthropic.skilljar.com/claude-with-the-anthropic-api/287761
- © 2025 Anthropic. Chỉ dùng cho mục đích giáo dục, fair-use.
- Crawl: 2026-04-23 · Chuẩn hoá: 2026-05-01