📖 Lesson content
Summary
A typical prompt evaluation workflow follows five key steps that help you systematically improve your prompts through objective measurement. While there are many different ways to assemble these workflows and various open source and paid tools available, understanding the core process helps you start small and scale up as needed.
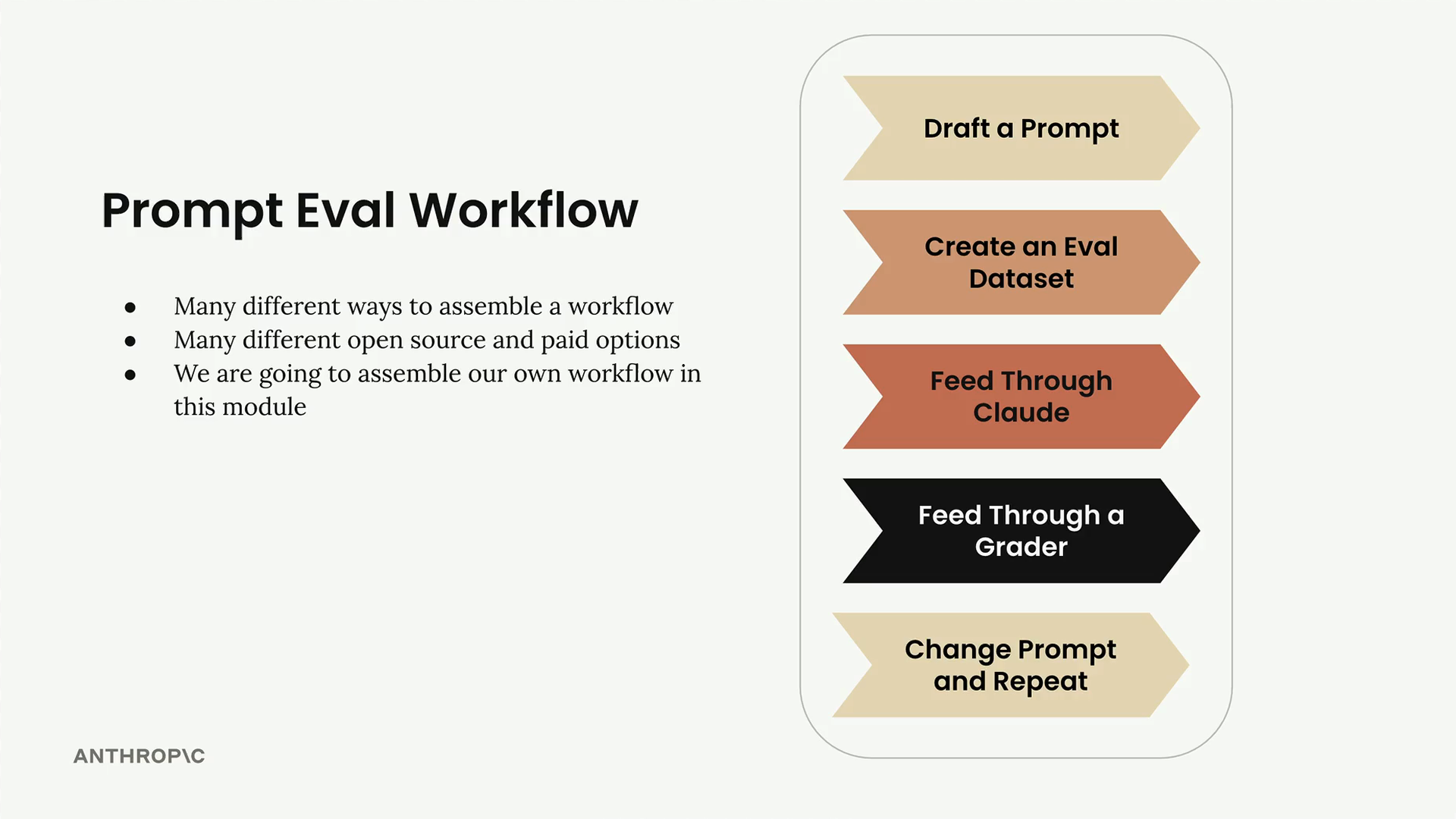
Step 1: Draft a Prompt
Start by writing an initial prompt that you want to improve. For this example, we'll use a simple prompt:
prompt = f"""
Please answer the user's question:
{question}
"""

This basic prompt will serve as our baseline for testing and improvement.
Step 2: Create an Evaluation Dataset
Your evaluation dataset contains sample inputs that you'll feed into your prompt. Since our prompt only has one input (the user's question), we need a collection of different questions to test with.
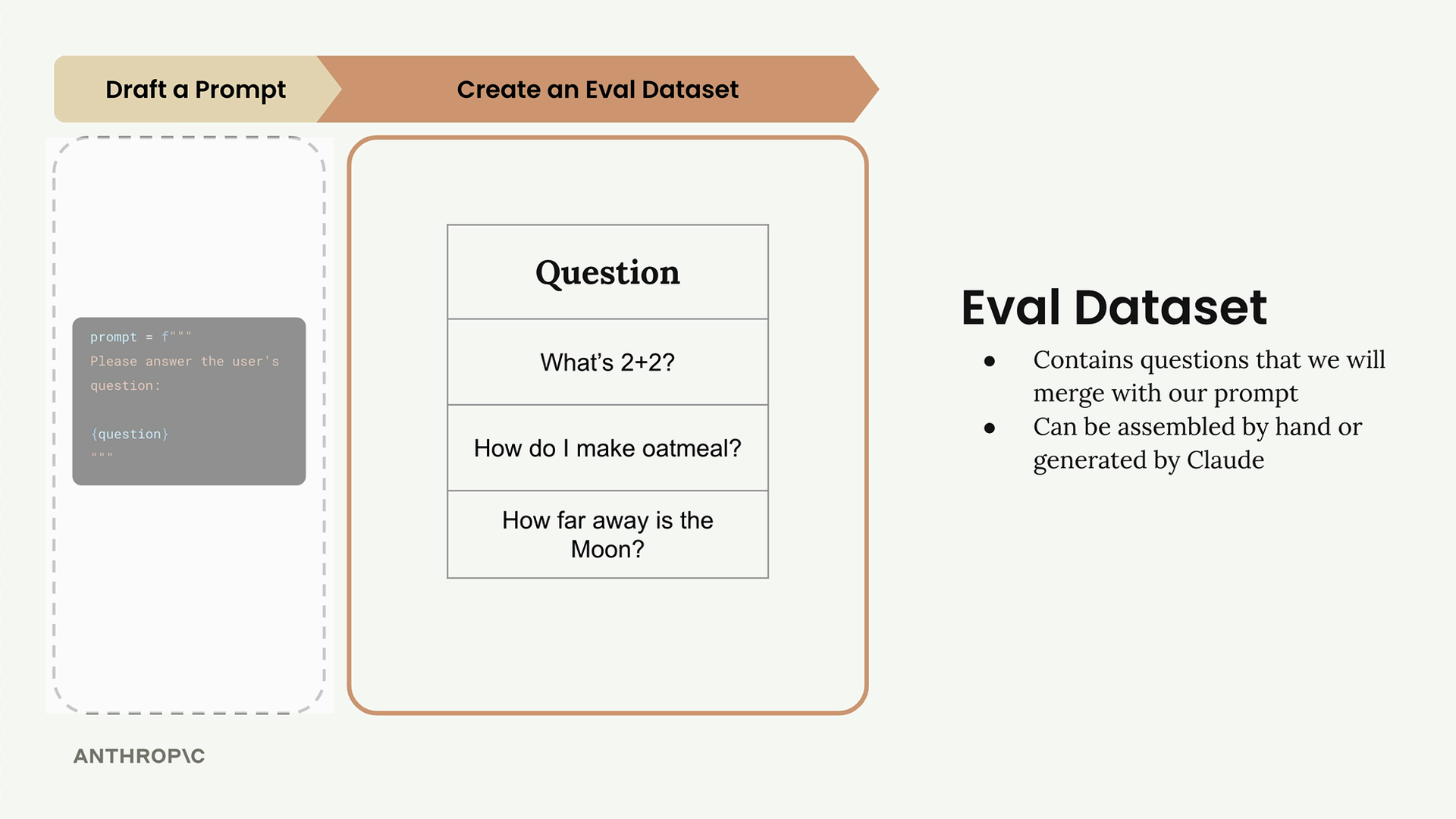
The dataset contains questions that we will merge with our prompt. You can assemble these datasets by hand or generate them using Claude. In real-world evaluations, you might have tens, hundreds, or even thousands of different records, but we'll start with just three questions for this example:
- What's 2+2?
- How do I make oatmeal?
- How far away is the Moon?
Step 3: Feed Through Claude
Take each question from your dataset and merge it with your prompt template to create complete prompts. Then send each one to Claude and collect the responses.
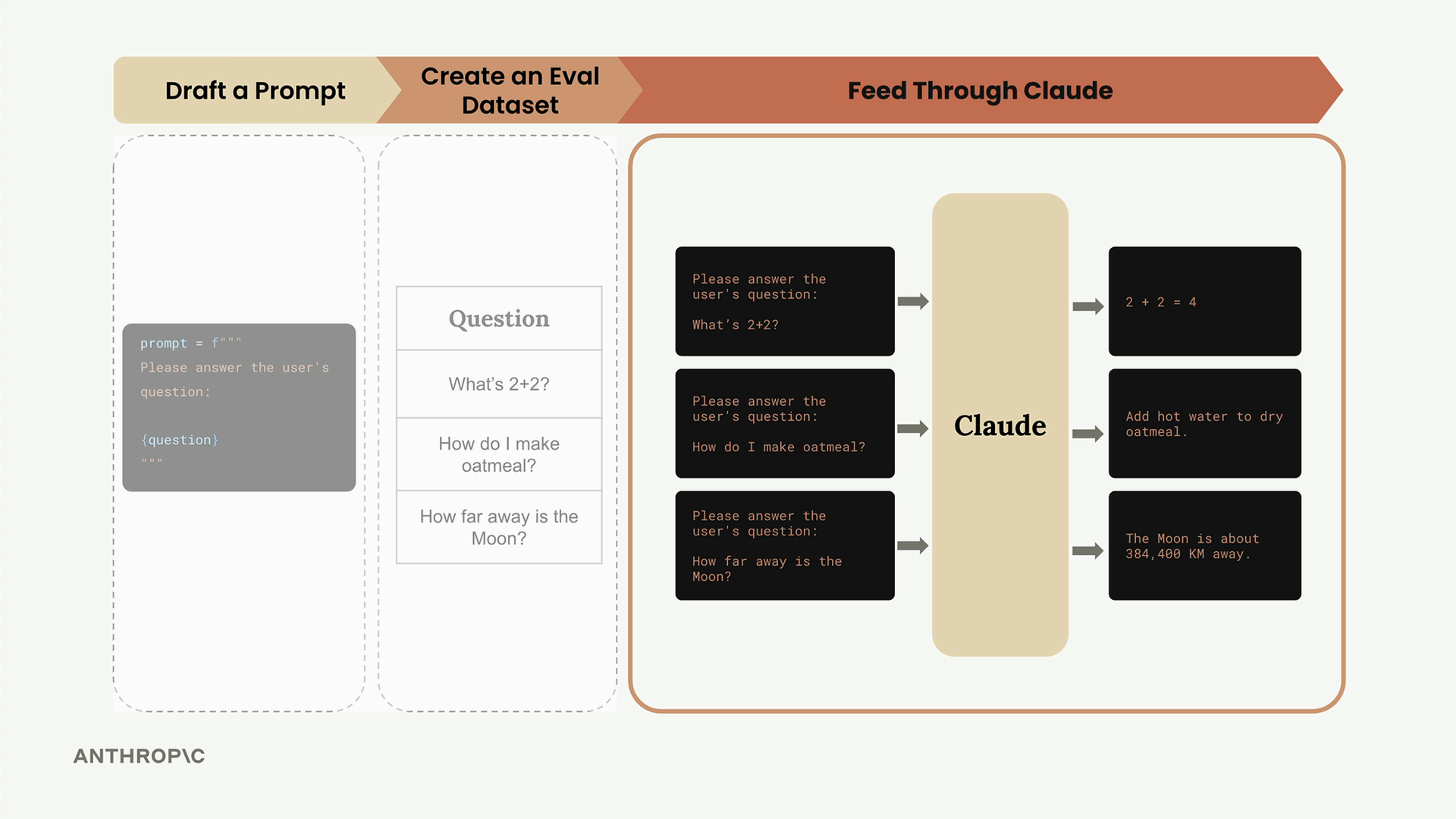
For example, the first question becomes a complete prompt that Claude processes and returns an answer like "2 + 2 = 4". You repeat this process for all questions in your dataset, building a collection of question-answer pairs.
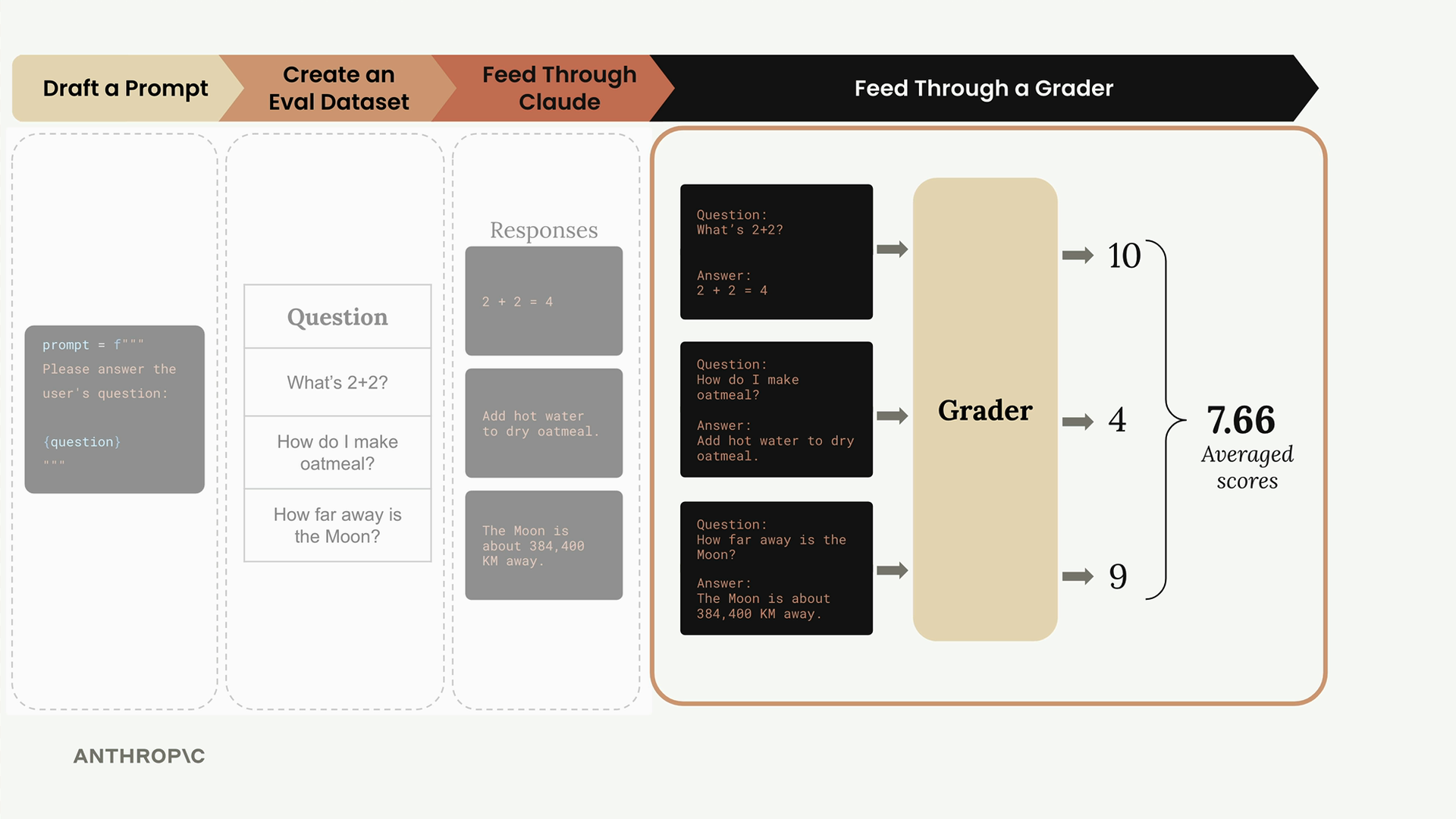
Step 4: Feed Through a Grader
Now comes the crucial step of objectively measuring the quality of Claude's responses. You take each question-answer pair and feed them into a grader that scores the responses.
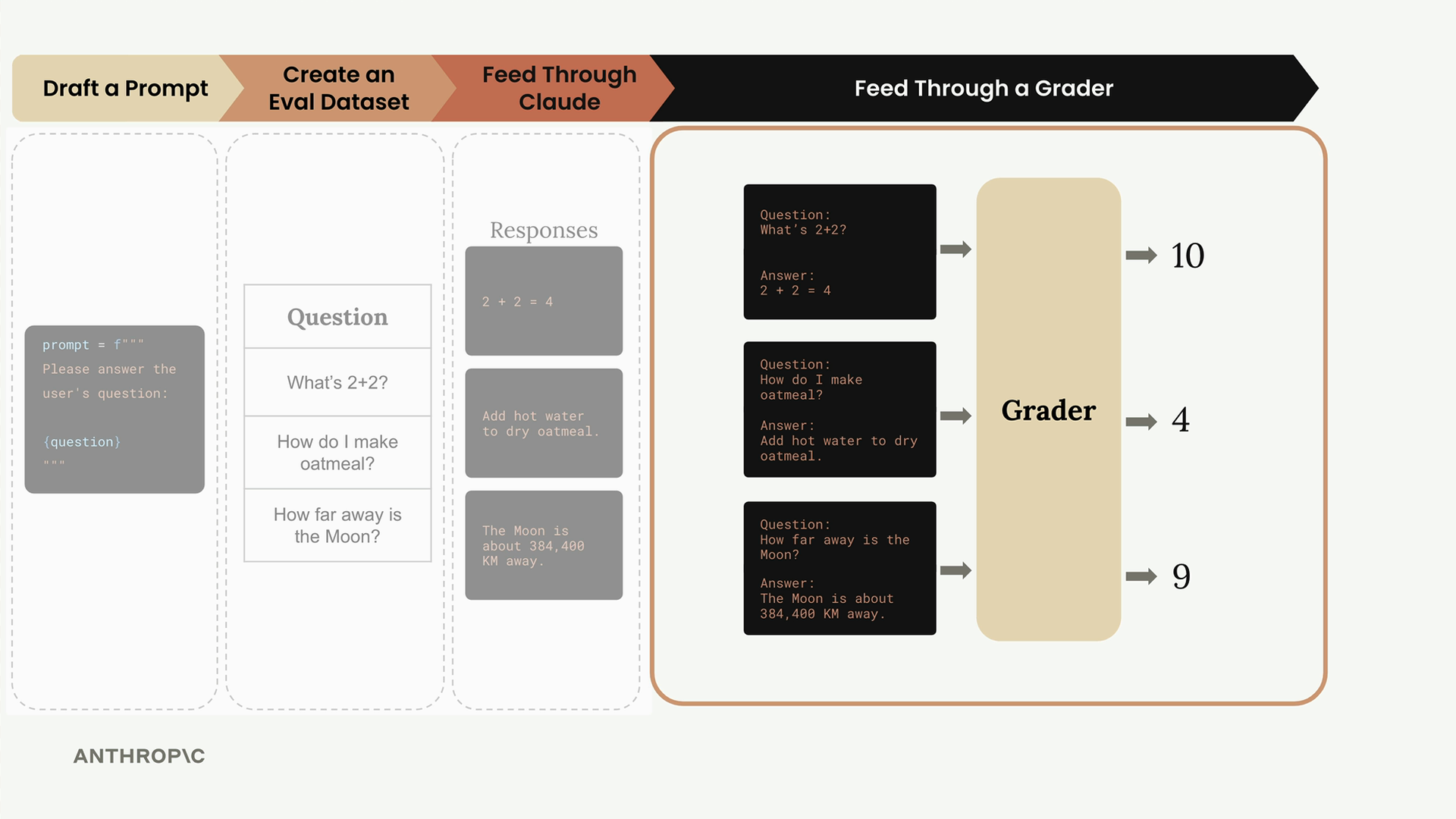
The grader assigns scores (typically 1-10) based on answer quality:
- 10 = Perfect answer with no room for improvement
- 4 = Adequate but definitely room for improvement
- Lower scores indicate poor responses
After scoring all responses, you average the scores together. In our example, scores of 10, 4, and 9 average to 7.66, giving you an objective measurement of your prompt's performance.
Step 5: Change Prompt and Repeat
With your baseline score established, you can now modify your prompt and run the entire process again to see if your changes improve performance.
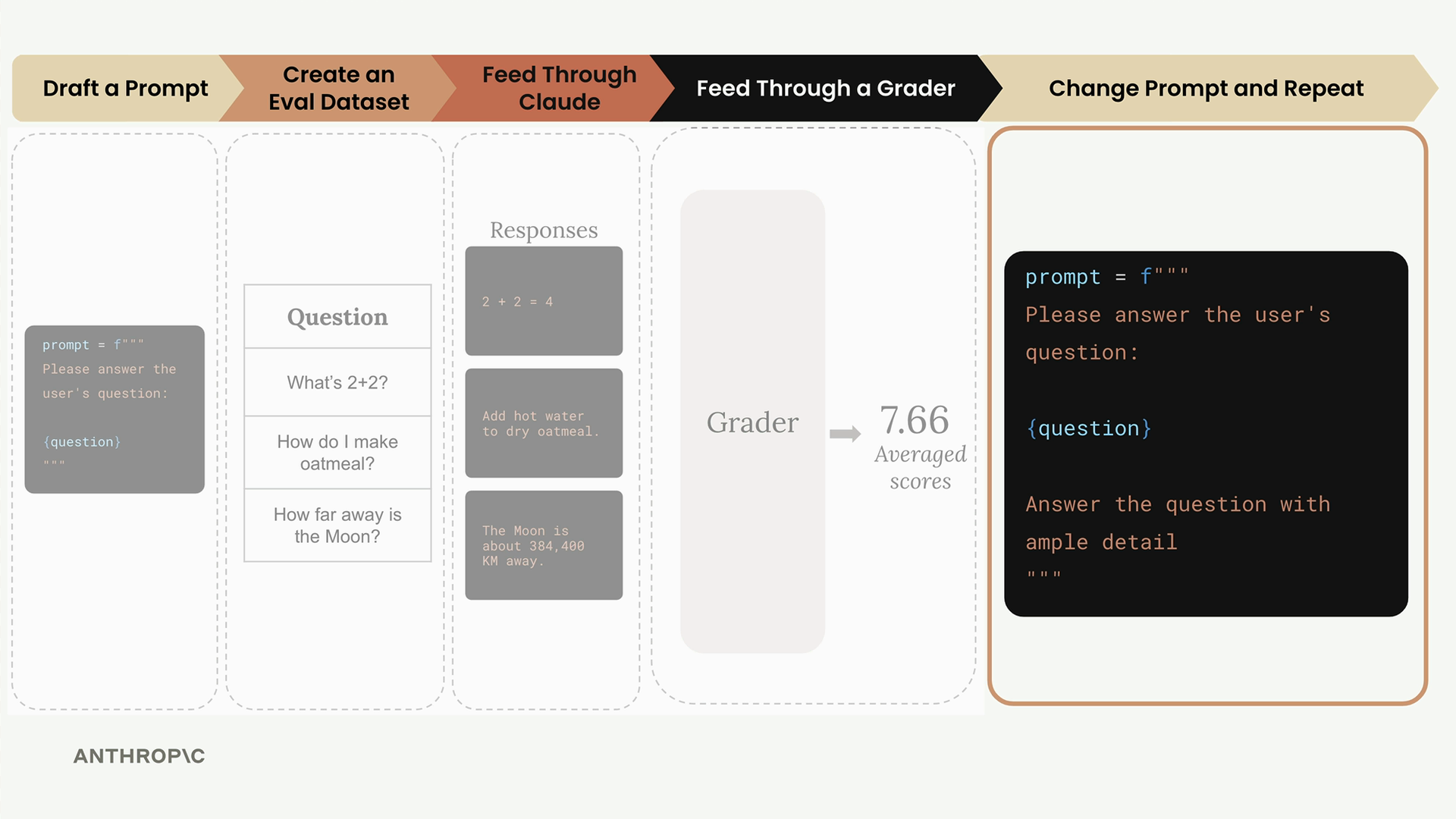
For example, you might enhance the original prompt by adding more specific instructions:
prompt = f"""
Please answer the user's question:
{question}
Answer the question with ample detail
"""
Prompt Scoring
The power of this workflow lies in getting objective measurements of prompt performance. You can compare scores between different prompt versions to determine which performs better.

In our example:
- Prompt v1 scored 7.66
- Prompt v2 scored 8.7
The higher score for v2 provides objective evidence that adding "Answer the question with ample detail" improved the prompt's performance. You can then use the better-performing version or continue iterating to achieve even higher scores.
This systematic approach removes guesswork from prompt improvement and gives you a reliable framework for optimization. While there's complexity in implementing effective graders, this workflow provides a solid foundation for building your own evaluation system.
🔁 Related lessons
- Next: Generating test datasets
- Previous: Prompt evaluation
- Same section: Making a request · Multi-turn conversations · Chat exercise
- Part of paths: Path C
- Reference docs: Glossary · Skills atlas · By use-case
📚 Source & attribution
- Original Anthropic Academy lesson: https://anthropic.skilljar.com/claude-with-google-vertex/289161
- © 2025 Anthropic. Educational fair-use only.