📖 Lesson content
Summary
Prompt engineering is about taking a prompt you've written and improving it to get more reliable, higher-quality outputs. This process involves writing an initial prompt, evaluating its performance, then systematically applying engineering techniques to improve it step by step.
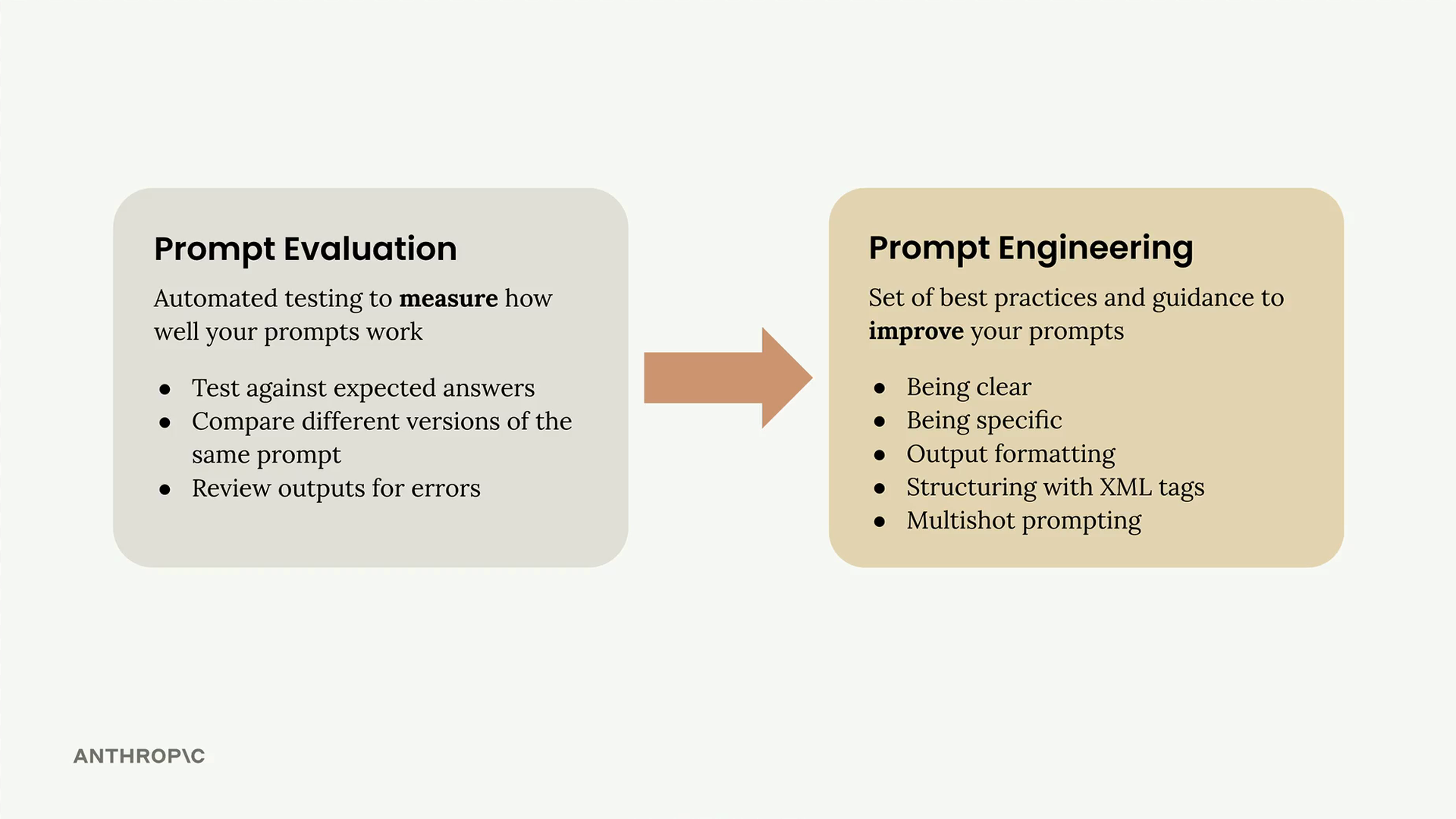
The Iterative Improvement Process
The approach follows a clear cycle: set a goal, write an initial prompt, evaluate it, apply a prompt engineering technique, then re-evaluate to verify better performance. This cycle repeats as you refine your prompt.

For this tutorial series, we'll work on a practical example: creating a prompt that generates one-day meal plans for athletes based on their height, weight, physical goals, and dietary restrictions.
Setting Up the Evaluation Pipeline
The evaluation uses an improved version of the pipeline from previous modules, wrapped in a PromptEvaluator class that handles dataset generation and model grading. The class supports concurrency to speed up the evaluation process:
evaluator = PromptEvaluator(max_concurrent_tasks=5)
Start with a low concurrency value (like 3) to avoid rate limit errors. You can adjust this based on your API quota.
Generating Test Data
The generate_dataset method creates test cases for your prompt. You need to specify:
- A task description explaining what your prompt should do
- A specification of the inputs your prompt requires
- The number of test cases to generate
For the meal planning example:
dataset = evaluator.generate_dataset(
task_description="Write a compact, concise 1 day meal plan for a single athlete",
prompt_inputs_spec={
"height": "Athlete's height in cm",
"weight": "Athlete's weight in kg",
"goal": "Goal of the athlete",
"restrictions": "Dietary restrictions of the athlete"
},
num_cases=3
)
Writing Your Initial Prompt
Start with a simple, naive prompt to establish a baseline. The run_prompt function receives the test case inputs and should return the model's response:
def run_prompt(prompt_inputs):
prompt = f"""
What should this person eat?
- Height: {prompt_inputs["height"]}
- Weight: {prompt_inputs["weight"]}
- Goal: {prompt_inputs["goal"]}
- Dietary restrictions: {prompt_inputs["restrictions"]}
"""
messages = []
add_user_message(messages, prompt)
return chat(messages)
Running the Evaluation
The evaluation process compares your prompt's output against expected criteria. You can add extra criteria to guide the grading:
results = evaluator.run_evaluation(
run_prompt_function=run_prompt,
dataset_file="dataset.json",
extra_criteria="""
The output should include:
- Daily caloric total
- Macronutrient breakdown
- Meals with exact foods, portions, and timing
"""
)
Analyzing Results
The evaluation generates an output.html file that you can open in your browser. This report shows detailed results for each test case, including scores, reasoning, and the actual output generated by your prompt.
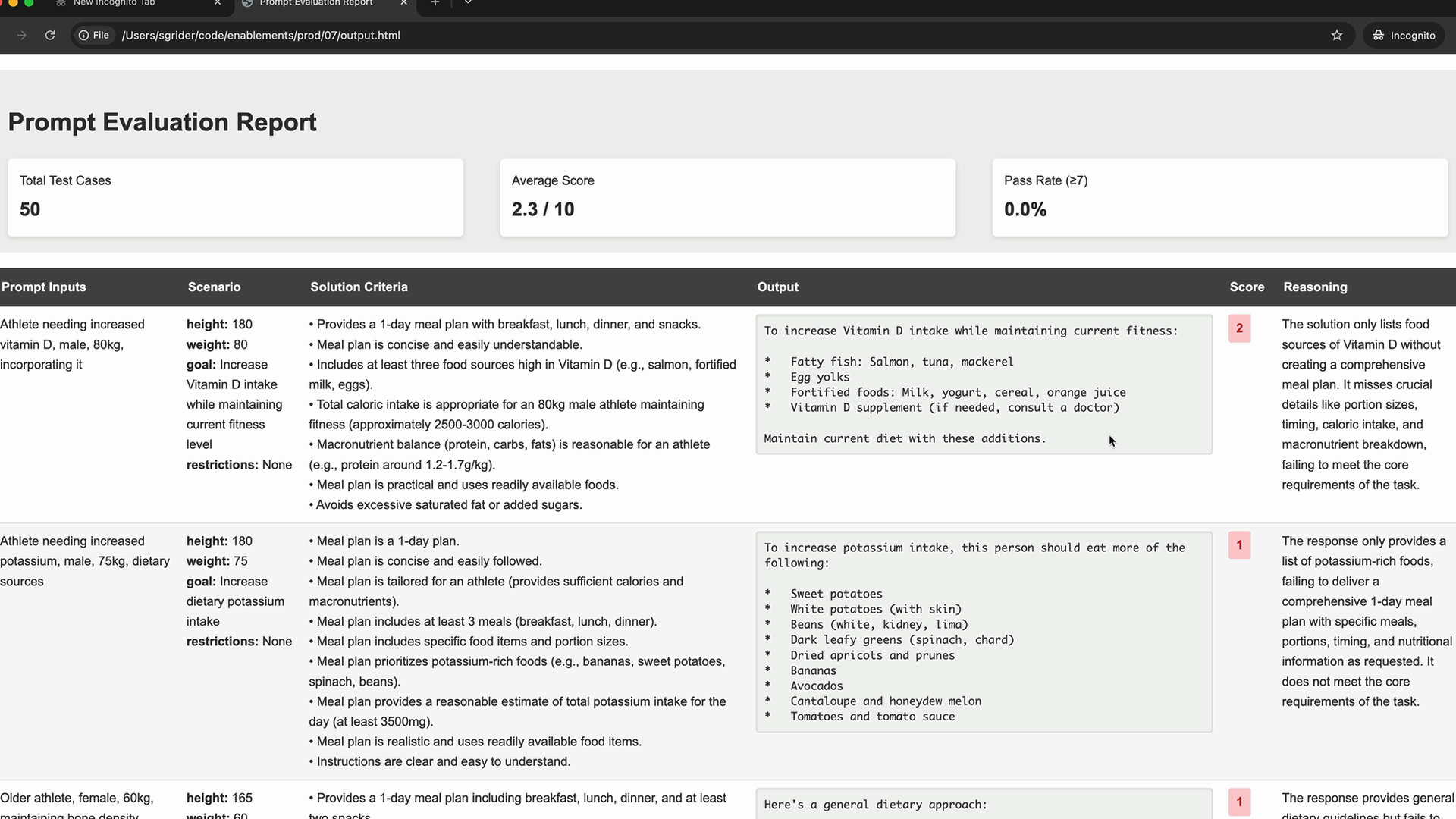
Don't be discouraged by low initial scores - that's expected! The initial prompt in this example scored only 2.3 out of 10, but this gives you a clear baseline to improve from.
What's Next
With your baseline established, you can now systematically apply prompt engineering techniques like being more specific, adding output formatting requirements, using structured prompts, and implementing multi-shot examples. Each technique should improve your evaluation score, giving you measurable progress toward your goal.
Downloads
🔁 Related lessons
- Next: Being clear and direct
- Previous: Quiz on prompt evaluations
- Same section: Overview of Claude Models · Accessing the API · Making a request
- Part of paths: Path C
- Reference docs: Glossary · Skills atlas · By use-case
📚 Source & attribution
- Original Anthropic Academy lesson: https://anthropic.skilljar.com/claude-in-amazon-bedrock/276749
- © 2025 Anthropic. Educational fair-use only.